
Forks usually fall behind. So I pulled both codebases and counted six months of commits, lines, tests, and features. Bazarr+ out-builds its parent on nearly every axis, and the test suite backs it up.

Forks usually die loud and ship little. They open with a manifesto, collect a few stars, and drift a year behind the project they split from. So when Bazarr+, a hard fork of the popular subtitle manager Bazarr, claimed it had not merely kept pace with upstream but pulled ahead, I did the unglamorous thing. I pulled both codebases and counted.
The verdict surprised me. Not because the fork is busy: busy is easy. Because the busyness holds up under scrutiny.
I counted instead of listening
Both projects develop on a development branch, so I measured the last six months on each, side by side: commits, lines of hand-written code, test coverage, supported runtimes, and shipped features. Marketing copy was ignored. Only the diff counts.
The activity gap is not subtle
Over six months, upstream Bazarr landed 247 commits on its development branch. The Bazarr+ ecosystem landed roughly 1,305 across its three repositories: the host application, a separate provider catalog, and an AI translation sidecar. That is more than five times the output.
My first reaction was the reviewer's reflex: commit count is vanity. A thousand commits can mean a thousand nervous tweaks. So I stopped counting commits and started measuring the thing they produced.
More code, and more tests to hold it up
The host application tells the story plainly. Bazarr+ carries about 42,700 lines of backend Python and 61,000 lines of frontend source, against upstream's 23,300 and 25,900. It is, bluntly, roughly twice the program.
Twice the code is a warning sign as often as a feature, so I went looking for the safety net. I found it. Bazarr+ ships 1,288 Python test functions across 139 files. Upstream has 246 across 34. A project moving five times faster while writing five times more tests is not vibe-coding its way forward. It is the opposite of the reckless-fork stereotype I arrived expecting.
| Signal (last 6 months, dev branch) | Bazarr+ | Upstream Bazarr |
|---|---|---|
| Commits (ecosystem) | ~1,305 | 247 |
| Backend Python (LOC) | 42,749 | 23,274 |
| Frontend source (LOC) | 61,360 | 25,864 |
| Python test functions | 1,288 | 246 |
| Test files | 139 | 34 |
| Python versions in CI | 3.12 to 3.14 | 3.10 to 3.13 |
What the extra code actually buys you
Volume only matters if it becomes capability, so here is what the fork shipped that upstream simply does not have.
A multi-tenant subtitle API. Bazarr+ split its single shared OpenSubtitles-compatible endpoint into a "Distribution Hub": named API keys, per-key rate tiers, provider scoping, and usage metering. If you serve subtitles to more than one client, this is a different class of tool.
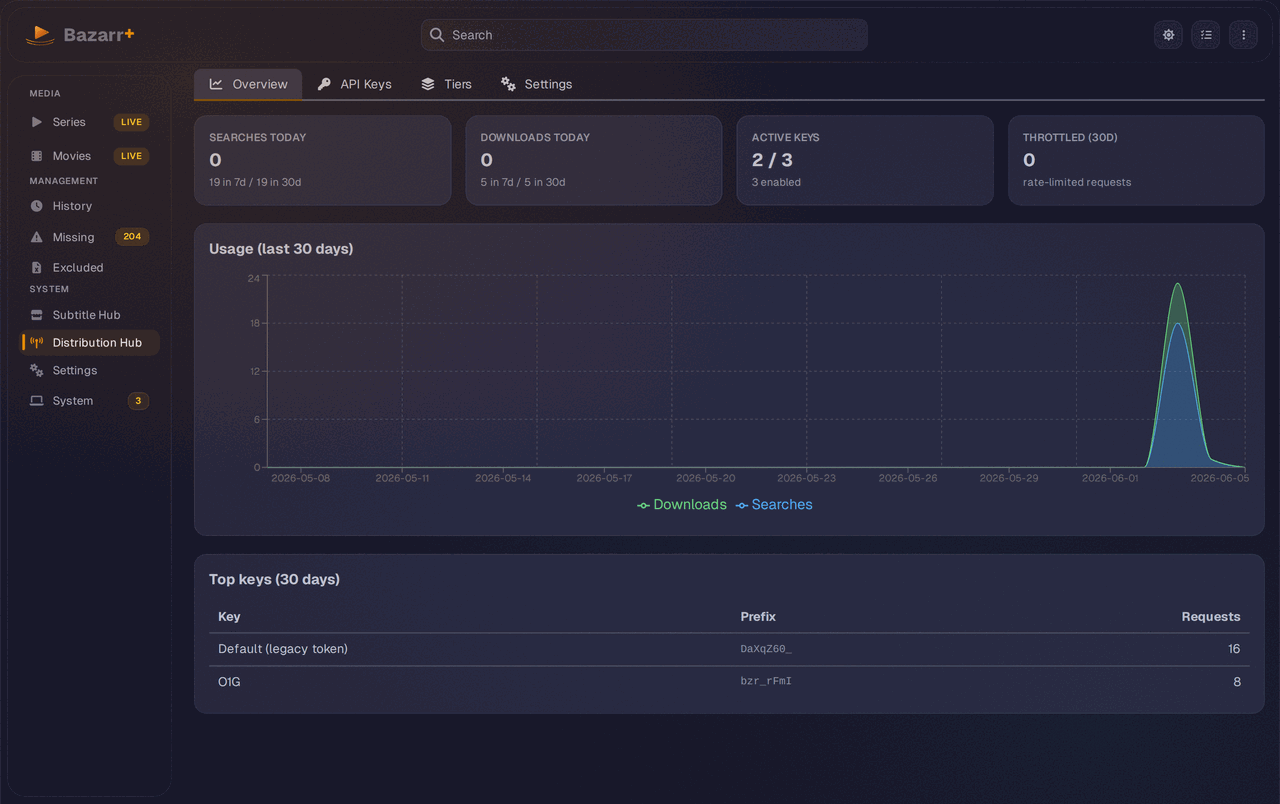
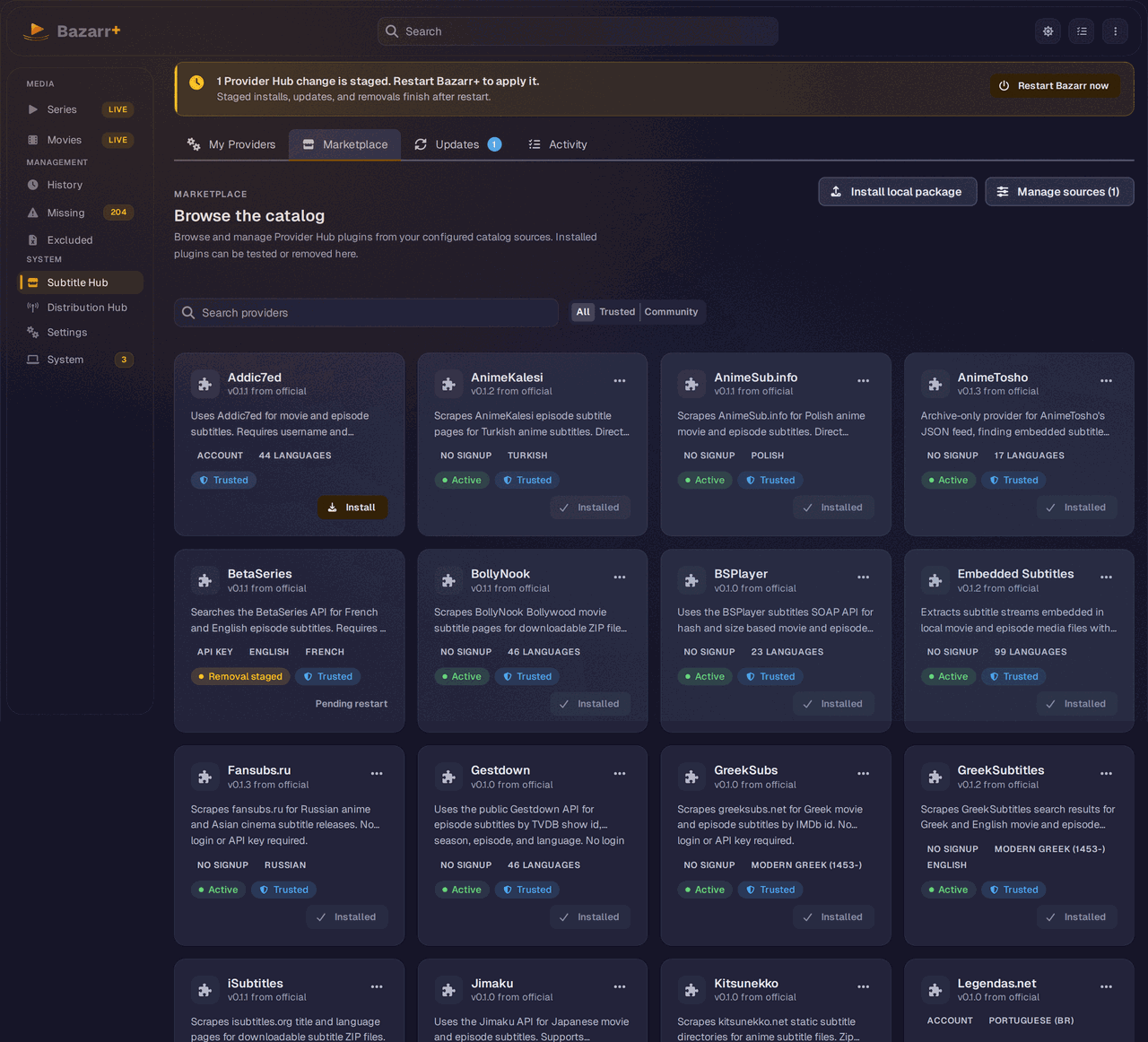
A plugin marketplace for providers. The biggest architectural bet is the Provider Hub: subtitle providers became installable plugins that update through a separate catalog instead of being welded to the application release. A provider breaks, you ship a catalog update, not a whole new version of the app. Upstream still bundles every provider into the core.
Composed bilingual subtitles. Bazarr+ can merge two on-disk subtitle tracks into a single bilingual or trilingual file, as SRT or ASS, on demand or per language profile. It is the kind of feature language learners and mixed-language households actually ask for.

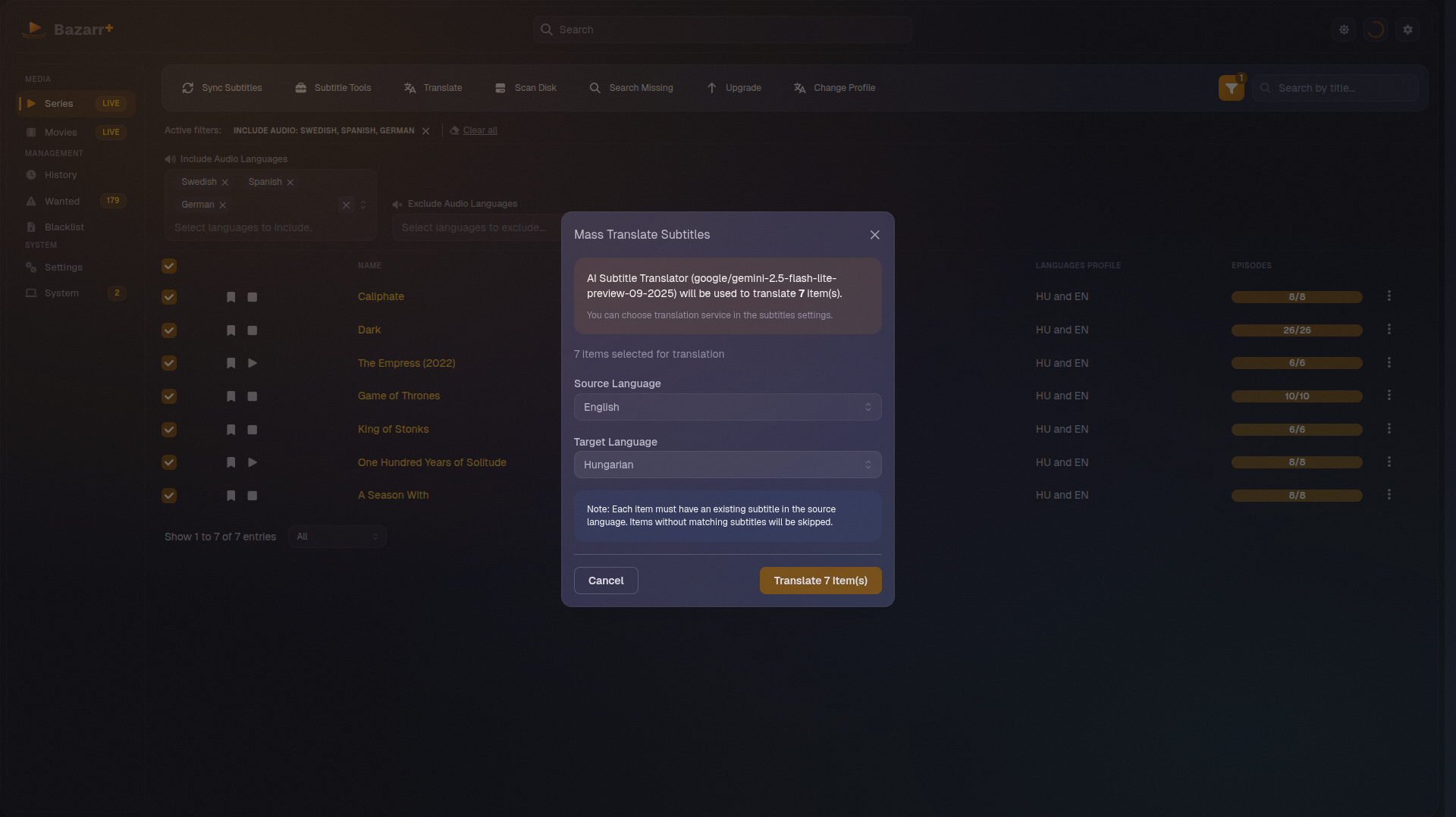
Built-in AI translation. When no human-made subtitle exists for a language, Bazarr+ can make one. It ships an integrated AI translation engine, a companion service wired into the app, that converts an existing track into another language and can run in bulk across an entire library. Upstream offers nothing comparable in-app.
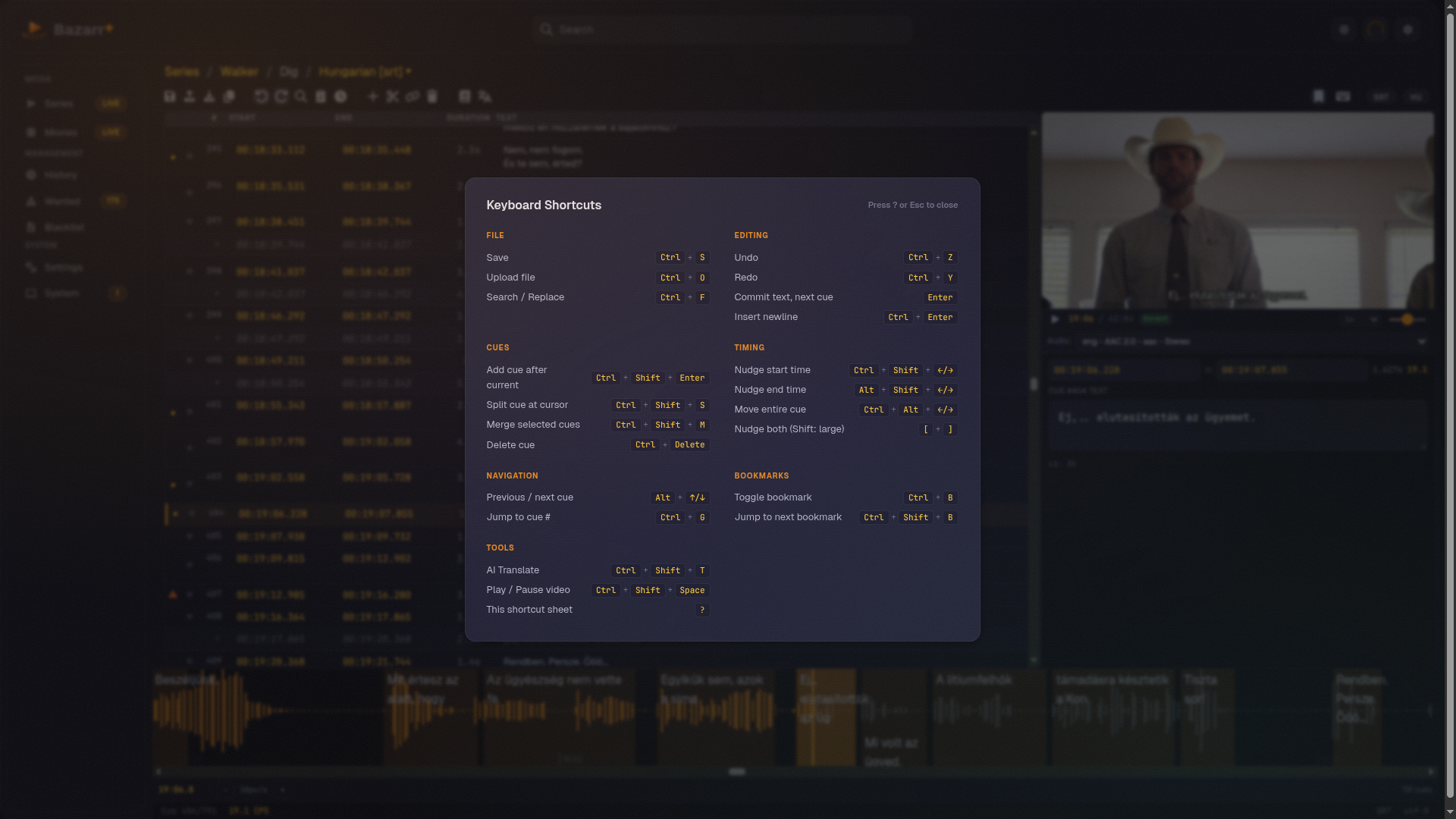
A real subtitle editor. Bazarr+ includes an in-app subtitle editor with a video preview, a fullscreen toggle, keyboard shortcuts, and direct editing of combined bilingual files. Upstream points you at an external program. Fixing a mistimed line where you already manage the library is a small convenience until the night you actually need it.
Add multi-engine synchronization with side-by-side output comparison and host-side archive extraction, and the gap stops being cosmetic. It is a different feature surface.
The case for staying on upstream
A skeptic who only prints good news is just a different kind of marketer, so here is the other side.
The fork is, for practical purposes, one person. The provider catalog and the translation sidecar are effectively solo projects, and the host application is overwhelmingly the work of a single maintainer. That is a brutal bus factor. Upstream leans heavily on one maintainer too, but it lands more outside contributions and carries the weight of a much larger, more battle-tested install base.
Twice the code is also twice the maintenance, and the fork makes its own forward-looking trade: it has dropped Python 3.10 and 3.11, which upstream still supports. If you run an older stack, that matters.
And upstream is no corpse. It committed the day before I ran these numbers. It remains the conservative, broadly trusted baseline, and for a lot of users "boring and proven" is exactly the right answer.
The verdict
I came in expecting fork hype and found a project that out-builds its parent on nearly every axis I could measure, with a test suite that earns the benefit of the doubt on quality rather than asking for it.
For anyone who wants capability and pace, runs a current stack, and is comfortable depending on a small but relentless development engine, Bazarr+ is the better software today. Conservative operators who prize the largest install base and the slowest, safest baseline should stay on upstream, and will not be wrong to.
But "just a fork" undersells this one badly. It ships, it tests what it ships, and it has quietly become the more ambitious of the two.
Bazarr+ is free, open source, and self-hosted. The code lives on GitHub, with install guides and documentation at lavx.github.io/bazarr. Upstream Bazarr is here.
Comments
Please log in or register to join the discussion