
Open table formats like Apache Iceberg and Delta Lake are transforming observability by enabling lakehouse architectures that combine object storage economics with database semantics. While promising schema evolution, efficient compression, and multi-engine access, challenges remain in partitioning strategies, metadata scaling, and Parquet's limitations for semi-structured data. Emerging innovations in file formats and engine integrations suggest a converging future where open storage and real-t

Over the past five years, open table formats like Apache Iceberg and Delta Lake have revolutionized data management, morphing chaotic data lakes into structured "lakehouses" that blend object storage scalability with database-like semantics. For observability teams drowning in telemetry data, this promises a tectonic shift: low-cost long-term retention without vendor lock-in, enabled by decoupled storage/compute architectures where any query engine can access standardized Parquet-based datasets. But can lakehouses truly handle the unique demands of observability workloads—high-cardinality filtering, semi-structured events, and point lookups—or do they merely trade one set of constraints for another?
The Foundation: Parquet's Columnar Power
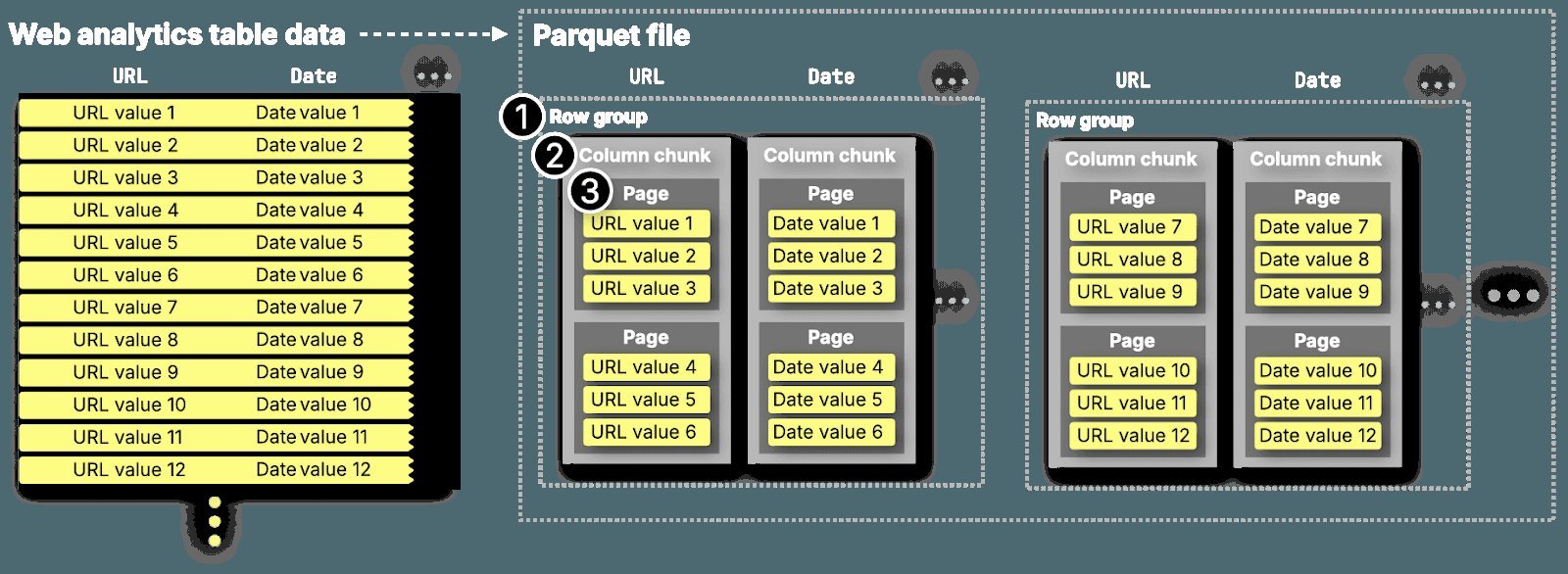 At the heart of most lakehouses lies Apache Parquet, a columnar format engineered for analytical efficiency. Unlike row-based storage, Parquet groups data by column, enabling:
At the heart of most lakehouses lies Apache Parquet, a columnar format engineered for analytical efficiency. Unlike row-based storage, Parquet groups data by column, enabling:
- Selective reads (only fetch needed fields)
- Advanced compression via run-length/dictionary encoding
- Statistical pruning using min/max values and Bloom filters
As illustrated above, data is organized into row groups, column chunks, and pages—each layer optimized for I/O efficiency. When values are sorted (e.g., by timestamp), compression ratios soar, making Parquet ideal for aggregating observability metrics or scanning logs. Yet this design prioritizes large sequential scans, not granular point queries common in trace debugging.
Table Formats: Adding Database Semantics
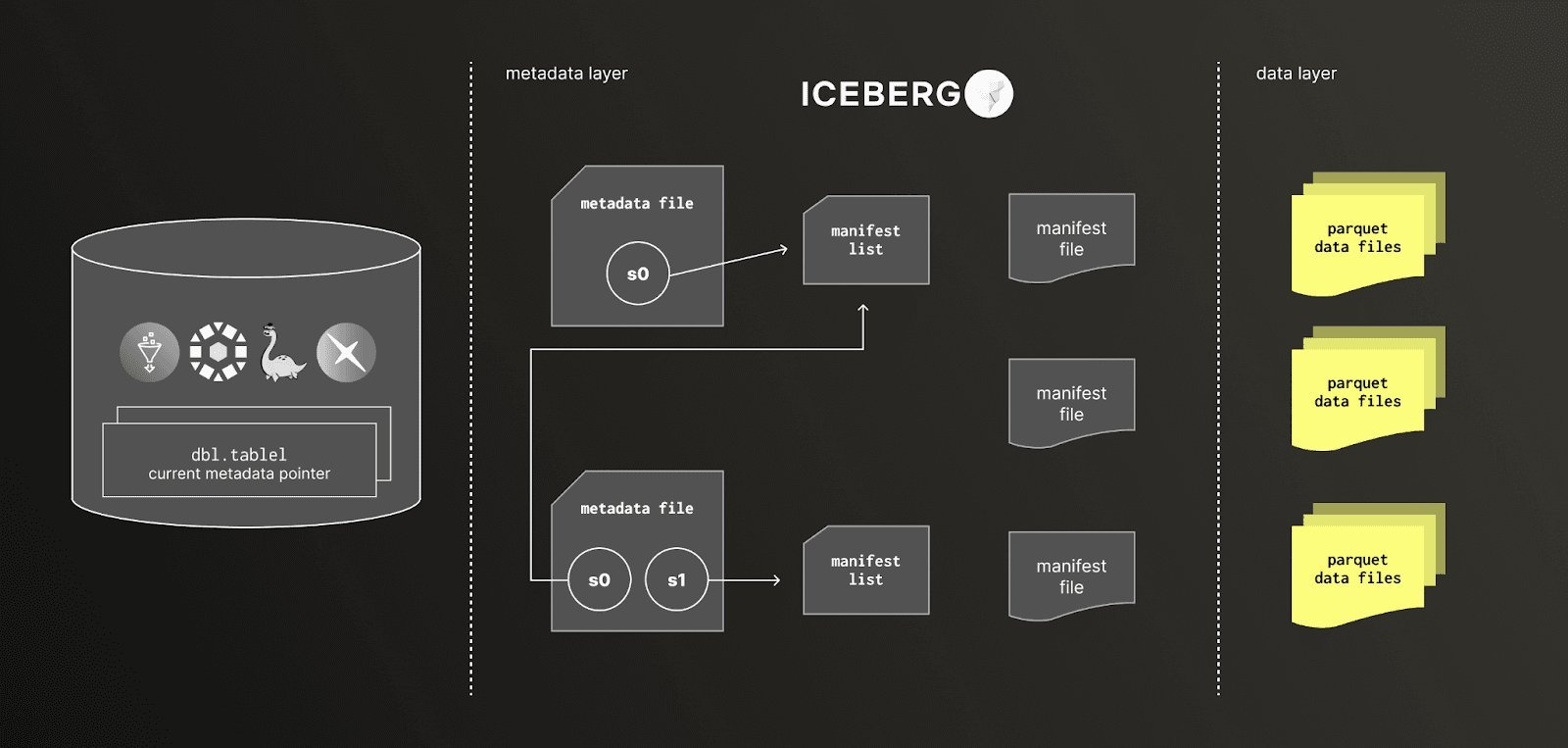 Parquet alone isn't enough. Table formats like Iceberg add critical abstractions:
Parquet alone isn't enough. Table formats like Iceberg add critical abstractions:
- Schema evolution to handle evolving telemetry structures without manual rewrites
- Time travel via snapshots for reproducible debugging
- Partitioning to skip irrelevant data during queries
- Catalogs (e.g., AWS Glue) for centralized metadata management
These features turn object storage buckets into queryable "tables." For observability, this means writing logs/traces directly to S3 while enabling analysis via engines like ClickHouse—eliminating costly data duplication. But the architecture introduces operational complexity:
-- Example: ClickHouse querying an Iceberg table via Glue catalog
CREATE DATABASE unity
ENGINE = DataLakeCatalog('https://<workspace>.cloud.databricks.com/api/2.1/unity-catalog/iceberg')
SETTINGS catalog_type = 'rest', warehouse = '<workspace>'
Scaling Challenges in Observability Workloads
Despite their promise, lakehouses face hurdles at observability scale:
Partitioning Pitfalls: Poorly chosen partitions (e.g., by high-cardinality
trace_id) spawn millions of small files, crushing query planning. Late-arriving data fragments partitions, demanding constant compaction.Metadata Overload: Each write generates new metadata files. At petabyte scale, manifest lists balloon, slowing planning and requiring aggressive garbage collection.
Concurrency Contention: Optimistic concurrency control struggles with 100k+ writes/sec, causing retry storms when updating table metadata.
Parquet's Semi-Structured Limits: Nested JSON forces full-page decoding to access single fields. Schema evolution triggers expensive metadata operations.
Object Storage Latency: Parquet's footer-heavy design requires multiple S3 round-trips per file—disastrous for point queries.
Innovations Closing the Gap
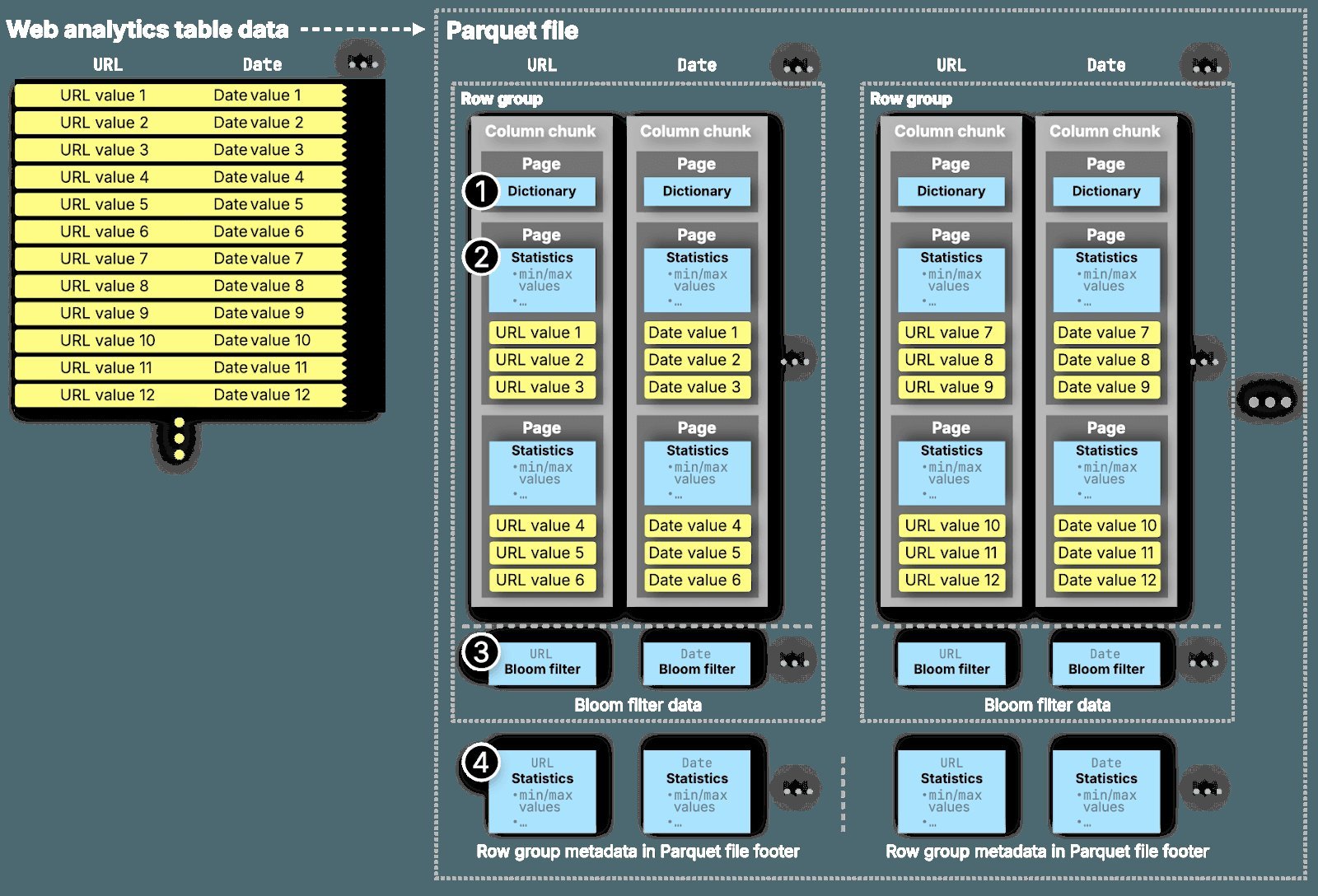 The ecosystem is rapidly adapting:
The ecosystem is rapidly adapting:
- Liquid Clustering: Auto-reclusters data without full rewrites, maintaining sort order for compression.
- Parquet VARIANT Type: Enables efficient nested JSON storage via two-level dictionary encoding (field names + values), reducing semi-structured read overhead.
- Lance Format: Emerges as a Parquet alternative with vectorized I/O, independent column flushing, and pluggable encoders for mixed workloads.
Meanwhile, engines like ClickHouse are bridging the gap:
- Parallel column reads within Parquet row groups
- Async I/O and request merging for S3
- Native Iceberg/Delta Lake integration (read/write)
- Dual-write architectures for hot analytics + cold storage
The Converging Future
Lakehouses won't replace analytical databases for real-time observability tomorrow—but they're evolving from archives to active participants. As formats like Lance mature and engines deepen integrations, we'll see a hybrid future: open table formats as the universal storage layer, with databases like ClickHouse providing the low-latency query layer. This convergence delivers the holy grail: vendor-agnostic economics without sacrificing performance.
Source: ClickHouse Blog
Comments
Please log in or register to join the discussion