
OneUptime is taking a direct shot at the fragmented observability ecosystem by bundling uptime checks, APM, incident response, logging, on-call, and status pages into a fully open-source platform. For teams wrestling with Datadog sprawl, PagerDuty fatigue, and SaaS lock-in, it poses a pointed question: why are you still stitching this together yourself?
OneUptime’s Open-Source Bet: Can a Single Stack Replace Your Entire Observability Toolchain?

The modern observability stack is a success story that got away from itself.
A typical production environment in 2025: you’re running uptime checks in one SaaS, logs in another, APM somewhere else, incident workflows in a fourth, on-call rotations in a fifth, and a status page bolted on top. Each tool is best-in-class; together they’re a tax—on budget, on cognitive load, on incident mean-time-to-clarity.
OneUptime, an open-source observability and reliability platform, is making a blunt counter-offer: what if you didn’t have to do that anymore?
Backed by a public GitHub repo and a growing community, OneUptime aims to absorb the roles of Pingdom, StatusPage.io, PagerDuty, New Relic, DataDog, Loggly, Sentry (soon), and various automation layers into a single, integrated system. Ambitious? Absolutely. But the timing—and the strategy—are telling.
Source: OneUptime on GitHub
From Fragmented Stack to Opinionated Platform
What makes OneUptime interesting is not that it does monitoring. It’s that it has a strong, holistic view of what “observability + reliability” should look like in a world of distributed systems and unforgiving SLAs.
At its core, OneUptime is structured around the full incident lifecycle:
- Detect failure.
- Page a human.
- Communicate externally.
- Investigate via logs and metrics.
- Capture decisions and remediation.
- Feed that back into better reliability.
Instead of gluing together six vendors and ten webhooks, these capabilities are natively integrated.
Uptime Monitoring: The Front Door
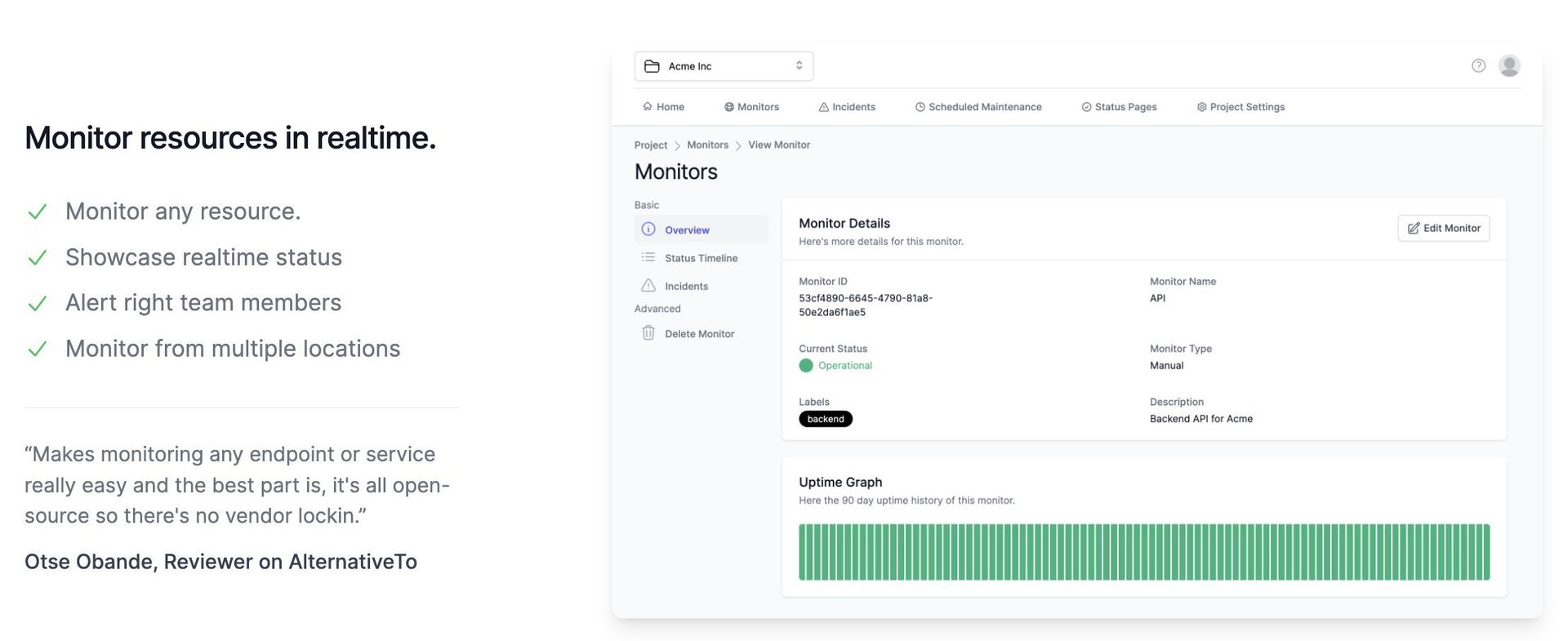
OneUptime’s uptime monitoring plays a familiar role: synthetic checks from multiple regions, response time measurements, and alerts when thresholds break.
What matters for engineers is where this data goes next:
- Alerts can drive on-call escalations without leaving the platform.
- Incidents can be spawned directly from failures, with context preserved.
- Public or private status pages can reflect real states automatically.
This is less about “can they ping an endpoint?” and more about “can the ping be the first structured event in a coherent incident narrative?” OneUptime leans into the latter.
Status Pages: Reducing the Copy-Paste Chaos
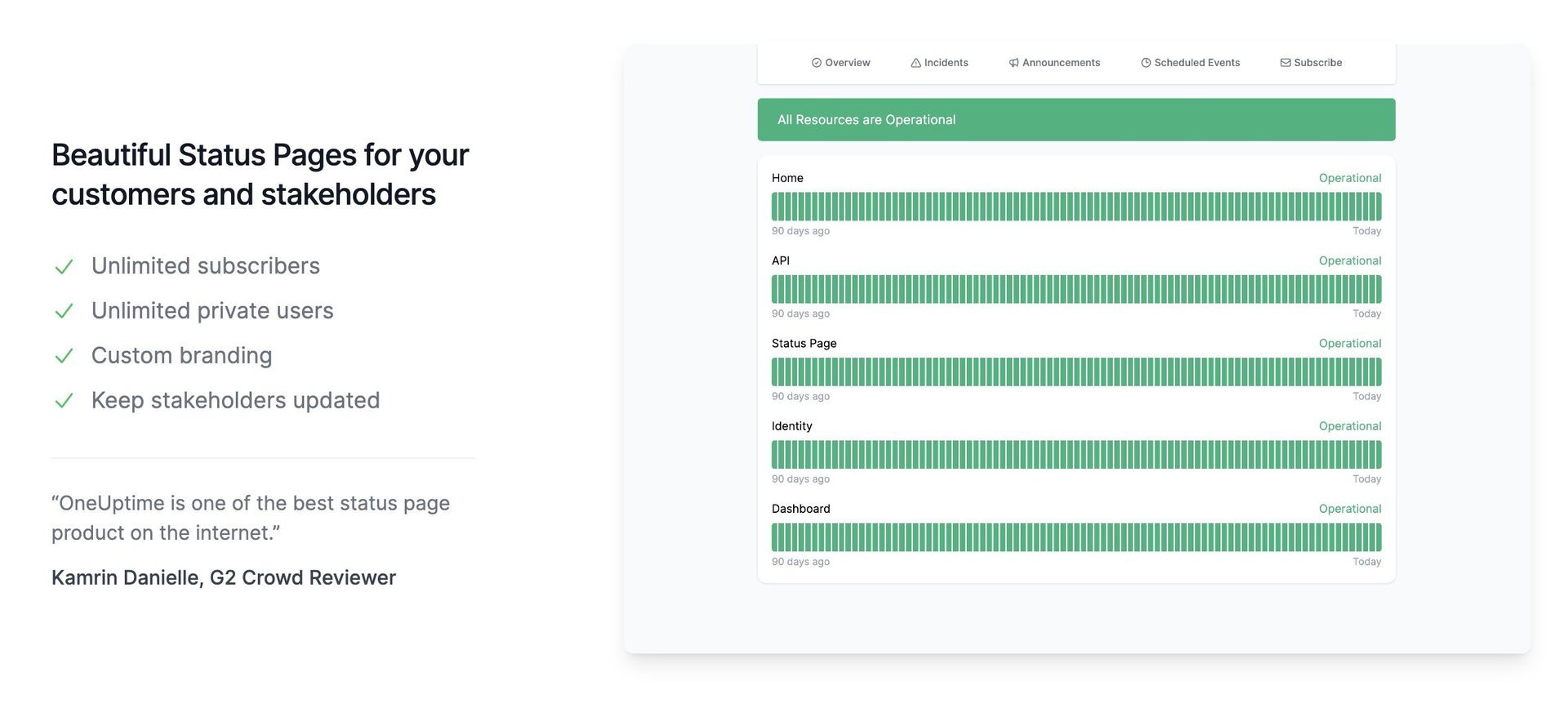
During an outage, someone always ends up manually syncing five tools and three audiences.
OneUptime bakes status pages into the same stack that’s detecting incidents and driving alerts:
- Custom-branded pages with historical uptime.
- Direct linkage between incidents and customer-facing updates.
- A single source of truth instead of “who last updated the status page?”
For teams operating public APIs, SaaS products, or multi-tenant platforms, this alignment between internal state and external narrative isn’t just cosmetic—it lowers the risk of conflicting messages in the middle of a critical event.
Incident Management: Workflow Without the Vendor Sprawl
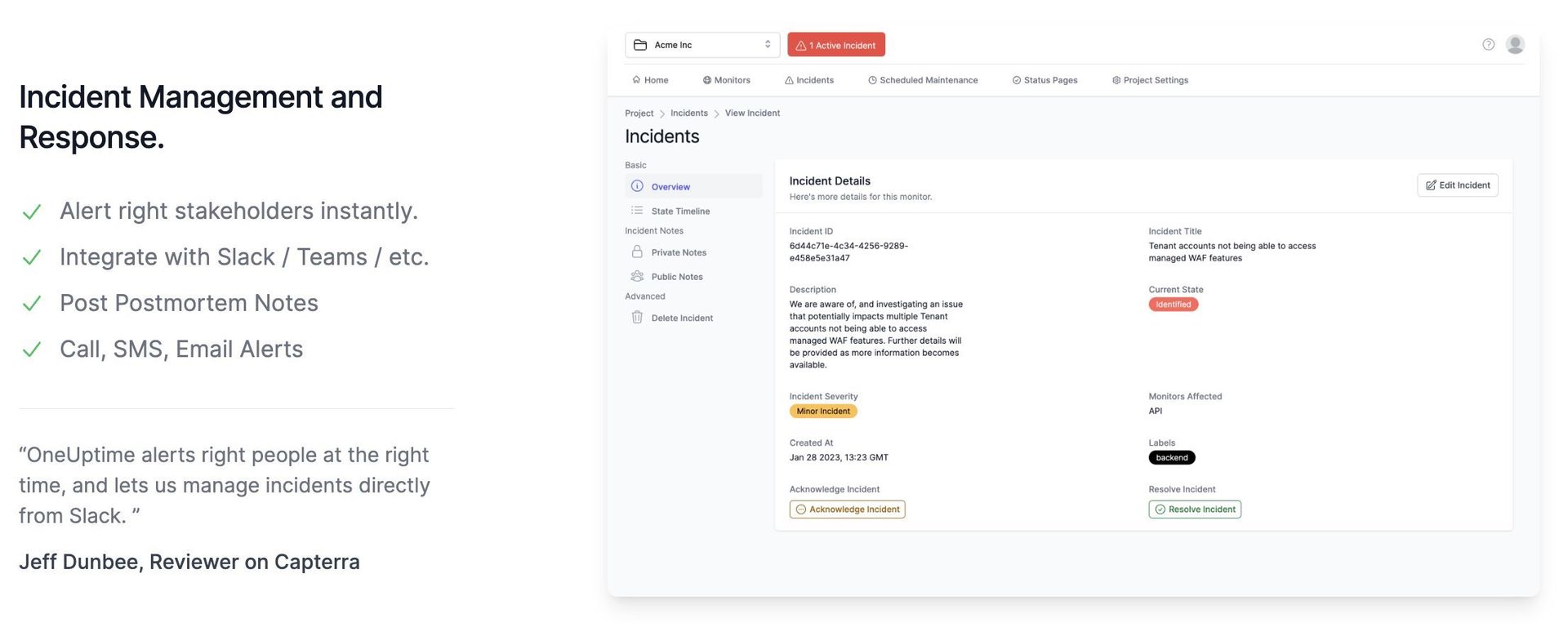
Incident tooling has matured from “create a ticket” to structured, collaborative workflows—and OneUptime clearly takes cues from tools like Incident.io.
Key elements include:
- Incident timelines with ownership, tasks, and updates.
- Stakeholder communication hooks.
- Post-incident documentation living next to the telemetry that informed it.
The meaningful bit is co-location. When logs, metrics, uptime checks, and on-call history live inside the same system as the incident record, the path from “what happened?” to “how do we prevent this?” is shorter and less lossy.
On-Call and Alerts: PagerDuty Without the PagerDuty Bill?
OneUptime includes:
- On-call schedules.
- Escalation policies.
- Multi-channel notifications (email, SMS, Slack, etc.).
Functionally, this targets PagerDuty, Opsgenie, and similar platforms. The differentiator is again philosophical: alerting is treated as a native part of observability, not a separate commercial island.
For lean teams, or orgs fatigued by escalating notification costs, the prospect of an integrated, open-source option is not just appealing—it’s strategically relevant.
Logs Management and APM: Consolidating the Backend Reality
The platform’s log aggregation and application performance monitoring aim squarely at DataDog, New Relic, and Loggly-style workflows:
- Centralized log ingestion and querying.
- Performance metrics: traces, response times, throughput, error rates.
- Correlation across services and components.
For developers, the real question is not “do they support logs and APM?”—that’s table stakes. It’s “how painful is it to get from a failing endpoint to the trace to the exact log line and deploy that caused it?”
If OneUptime continues to tighten the connections between its features (for example, associating an incident with the traces and logs from its triggering window), it moves closer to being an actual observability platform rather than just a suite of adjacent features.
Workflows: The Glue for Real-World Stacks
Adoption rarely happens in a vacuum. OneUptime’s workflow engine and integrations with Slack, Jira, GitHub, and thousands more tools acknowledge a simple truth: you’re not rebuilding your org around a single vendor.
This is where it can either shine or stumble:
- If workflows make it easy to automate incident creation, CI/CD hooks, and postmortem generation, OneUptime can sit comfortably at the center of a modern engineering stack.
- If they’re shallow or fragile, teams will default back to their bespoke scripts and scattered SaaS.
The success of this layer will determine whether OneUptime becomes infra-critical, or “just another dashboard.”
The Open-Source Play: Control, Compliance, and Cost
OneUptime’s most consequential decision is philosophical: the entire platform is open source.
For developers and engineering leaders, that has concrete implications:
- No black box: You can audit how data is handled, how alerts are triggered, how incidents are modeled.
- Customization: Extend or adapt components instead of waiting on closed-roadmap vendors.
- Exit strategy: Self-host if pricing or policy shifts; you’re not contractually handcuffed.
Community vs Enterprise: A Familiar but Important Split
The project ships in two flavors:
Community Edition
- Full feature set for self-hosters.
- Standard security posture.
- Community-driven support.
- Rapid public releases.
Enterprise Edition
- Hardened container images and tightened security controls.
- Custom features and input into roadmap.
- Priority support (including 1-hour response with a dedicated engineer).
- Data residency and retention flexibility.
- Deployable in private cloud or as managed SaaS.
This mirrors the now-standard commercial open-source model—but in the observability space, it’s strategically potent. Regulated industries and large-scale platforms routinely balk at sending everything to multi-tenant SaaS. A serious, self-hostable alternative with enterprise support is not a nice-to-have; it’s often the deciding factor.
Reliability Copilot and Error Tracking: Where It Gets Interesting
Two “coming soon” capabilities hint at the next phase of OneUptime’s ambition:
Error Tracking
- Sentry-style error capture with stack traces and context.
- Bridges the final gap between raw telemetry and developer-facing issues.
Reliability Copilot
- An AI-assisted system to scan code and suggest fixes for performance and reliability issues.
If executed well, these features can shift OneUptime from being reactive tooling to proactive infrastructure intelligence:
- Error tracking closes the loop from production behavior to code.
- An AI copilot layered on top of unified telemetry has a richer signal than tools trying to infer reliability issues from a single dimension.
The caveat is obvious: “AI copilot for reliability” is only as good as its training data, guardrails, and integration into real workflows. But the direction is aligned with where high-performing teams are headed: automated detection, prioritized insight, assisted remediation—not just more dashboards.
Why This Matters for Engineering Leaders
OneUptime isn’t just another monitoring tool announcement. It’s a stress test of several assumptions that have quietly governed observability for the last decade:
- That you need many vendors to do observability well.
- That the best tooling must be closed-source, multi-tenant SaaS.
- That integration complexity is simply the cost of operating at scale.
By challenging all three at once, OneUptime forces a set of uncomfortable but useful questions for technical leaders:
- How much of your incident response time is lost in tool-switching rather than debugging?
- How much are you paying—financially and operationally—for overlapping features across vendors?
- Which observability components do you actually need to own (for compliance, for sovereignty, for resilience)?
- If a unified, open-source platform can get you to “good enough plus control,” is best-in-class-but-siloed still worth it?
None of this means every team should rip out Datadog or PagerDuty tomorrow. Mature ecosystems, advanced analytics, and proven reliability are real advantages. But the existence of a credible open-source, all-in-one contender changes the negotiation.
Signals to Watch as OneUptime Grows Up
For developers, SREs, and platform teams evaluating OneUptime, a few practical signals will indicate whether this is a serious long-term pillar or a promising side project:
- Issue velocity and transparency on GitHub.
- Depth and performance of log search and APM at real-world scale.
- Robustness of integrations with CI/CD, IaC, and incident tooling.
- UX under pressure: how it behaves in a messy, high-cardinality, multi-service incident.
- The quality of the upcoming Error Tracking and Reliability Copilot features.
If OneUptime can keep its promise of unifying observability, incident management, and automation without collapsing under its own scope, it won’t just be “another option” in the stack.
It will be a forcing function: one that pushes the entire industry—incumbents included—toward more integrated, transparent, and developer-respectful reliability tooling.
Comments
Please log in or register to join the discussion