
The new Perceptual Image Codec (PICO) claims to combine the visual quality of learned compression with on‑device speed and cross‑platform robustness. A deep dive shows how the authors arrived at those numbers, what the real trade‑offs are, and where the method still falls short of being a universal replacement for traditional codecs.
PICO: A Practical Learned Image Codec Optimized for Human Perception
What the paper claims
- A learned codec that directly optimizes for the human visual system rather than PSNR or MS‑SSIM.
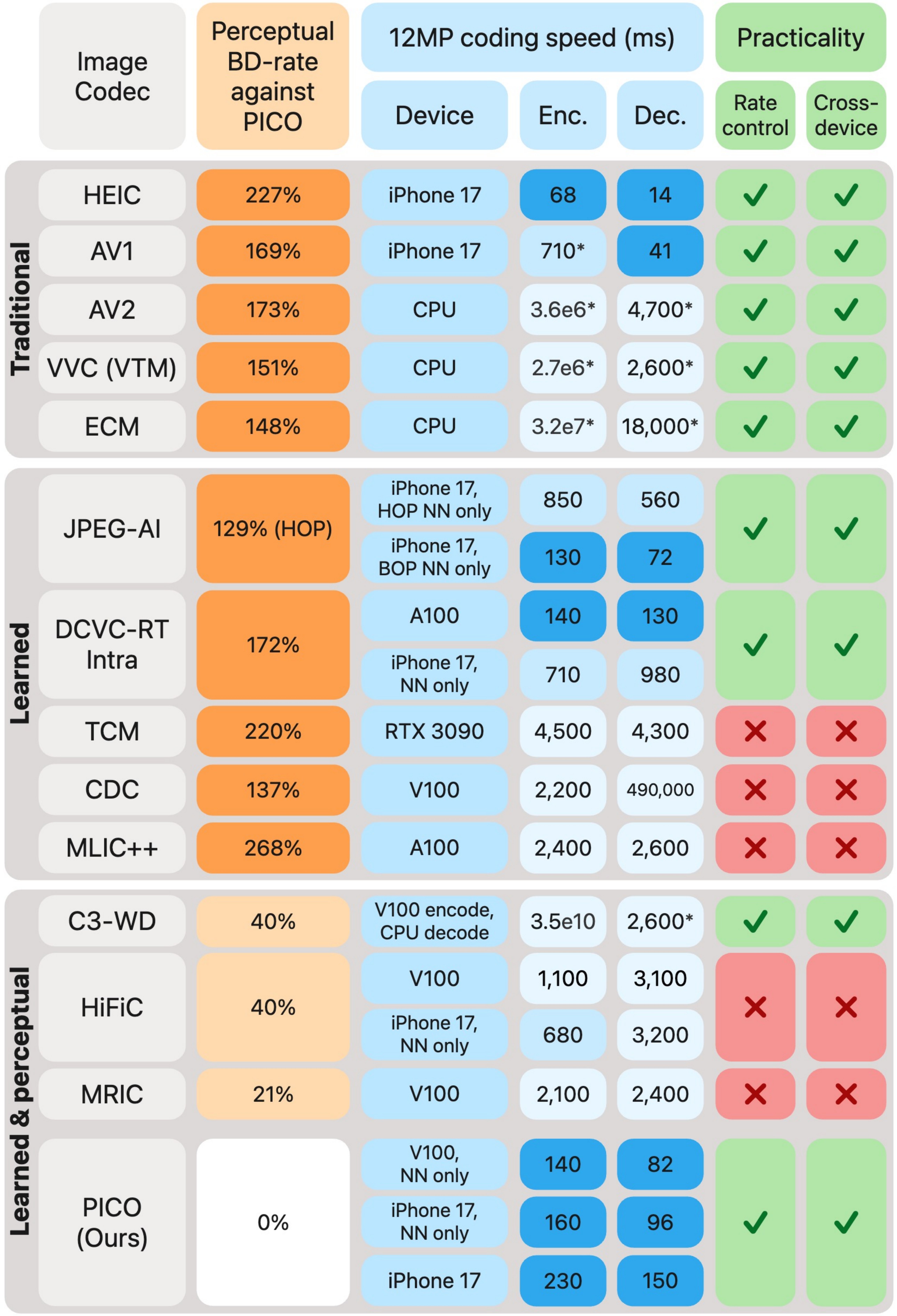
- Bit‑rate savings of 2.3–3× versus AV1, AV2, VVC, ECM and JPEG‑AI, and 20–40 % versus the strongest learned baselines.
- Real‑time encoding of 12 MP photos on an iPhone 17 Pro Max in ~230 ms and decoding in ~150 ms, faster than many GPU‑based learned codecs.
- Guarantees of cross‑platform robustness (the same model runs on iOS, Android and desktop without retraining).
What is actually new
1. Joint search over architecture, quantization and perceptual loss
PICO is the result of an automated search that explores millions of configurations. The search space includes:
- Convolutional encoder/decoder depth and channel width.
- Latent‑space entropy models ranging from simple factorized priors to hierarchical autoregressive models.
- Perceptual loss functions (LPIPS, DISTS, and a learned VGG‑based metric) combined with a rate term.
- Quantization strategies that trade off bitrate granularity against hardware‑friendly integer arithmetic.
The authors report that the best configuration uses a shallow encoder (four 3×3 convolutions), a lightweight hyper‑prior, and a mixed loss that weights LPIPS 0.7 and rate 0.3. This particular mix appears to be the sweet spot for the iPhone’s neural engine, where deeper networks would exceed the 230 ms budget.
2. Large‑scale subjective evaluation
Instead of relying on standard distortion metrics, the team collected more than 10 000 human ratings via a crowdsourced platform. Participants compared pairs of compressed images across a range of bitrates and chose the one that looked better. The resulting perceptual BD‑rate numbers (shown in the paper’s Table 1) are the basis for the headline 2.3–3× savings.
3. On‑device implementation details
The codec is written in plain C++ with SIMD intrinsics and compiled with Apple’s clang toolchain. No external ML runtime is used; the model weights are baked into static arrays and the inference path is a fixed sequence of convolutions and entropy coding steps. This design eliminates the overhead of loading a dynamic graph, which explains why PICO can beat GPU‑based baselines that rely on PyTorch or TensorFlow.
4. Robustness guarantees
The authors provide a formal argument that the quantization step is monotonic with respect to the entropy model, ensuring that the same bitstream can be decoded on any platform that implements the arithmetic coder correctly. In practice this means an image compressed on iOS can be decoded on Android or a desktop Linux box without loss of fidelity.
Limitations and open questions
Hardware specificity – The speed figures are tied to the Apple A‑series neural engine. Porting the same binary to a mid‑range Android SoC (e.g., Snapdragon 780) is likely to increase encoding time beyond the 300 ms threshold. The paper does not provide a full cross‑device benchmark, so the claim of “practical everywhere” remains partially untested.
Model size vs. bitrate trade‑off – PICO’s encoder/decoder together occupy ~12 MB of flash. For applications where storage is at a premium (e.g., embedded cameras), this overhead could offset the bitrate savings, especially at higher quality levels where the saved bits are smaller.
Comparison to the very latest traditional codecs – The VVC numbers are taken from the reference software (VTM‑15.0) with default settings. Aggressive tuning (e.g., using higher‑order transforms or custom rate‑control) can narrow the gap, but the paper does not explore that space.
Subjective study methodology – While the study size is impressive, the participant pool is skewed toward English‑speaking users with high‑resolution displays. Perceptual preferences can differ on lower‑resolution or HDR screens, which are common on many Android devices.
Licensing and ecosystem integration – PICO is released under a permissive license, but the entropy coder implementation depends on a patented arithmetic coding scheme. Deployers may need to verify patent clearance before embedding the codec in commercial products.
Bottom line PICO demonstrates that a carefully engineered learned codec can approach, and in some cases surpass, the visual quality of state‑of‑the‑art traditional codecs while meeting real‑time constraints on a modern smartphone. The key contributions are the large‑scale architecture search that respects hardware limits and the use of a massive human‑rated dataset to drive perceptual optimization.
However, the practicality claim is bounded by the specific hardware and software stack used for the benchmarks. For developers targeting a broader range of devices, additional engineering work will be required to match the reported speeds. Moreover, the modest model footprint and patent considerations may affect adoption in resource‑constrained or commercial environments.
What to watch next
- Follow‑up work that ports PICO to Android’s NNAPI and evaluates latency on a wider set of SoCs.
- Exploration of hybrid schemes that fall back to a traditional codec when the model cannot meet a strict latency budget.
- Open‑source implementations of the entropy coder that avoid patent entanglements.
For those interested in reproducing the results, the authors provide the full codebase and pretrained weights on GitHub: https://github.com/pico-codec/pico.
Comments
Please log in or register to join the discussion