
RapidFire AI has officially integrated with Hugging Face's TRL library, enabling developers to concurrently test multiple fine-tuning configurations on LLMs with dramatically reduced GPU requirements and significantly faster iteration cycles.
In the fast-evolving landscape of large language models, fine-tuning and post-training experiments are crucial for optimizing model performance. However, the traditional approach of testing configurations sequentially creates significant bottlenecks, consuming both valuable time and expensive GPU resources. RapidFire AI aims to revolutionize this process with its newly announced integration with Hugging Face's Transformer Reinforcement Learning (TRL) library, promising up to 24x acceleration in experimentation throughput.

The Challenge of Sequential Experimentation
When fine-tuning or post-training LLMs, teams face a fundamental trade-off: comparing multiple configurations can significantly boost evaluation metrics, but sequential testing is prohibitively time-consuming. With RapidFire AI, this paradigm shifts dramatically. The platform allows teams to launch multiple TRL configurations concurrently—even on a single GPU—and compare results in near real-time through an adaptive, chunk-based scheduling and execution scheme.
"When fine-tuning or post-training LLMs, teams often do not have the time and/or budget to compare multiple configs even though that can significantly boost eval metrics," explains the RapidFire AI team. "RapidFire AI lets you launch multiple TRL configs concurrently and compare them in near real time."
How RapidFire AI Achieves Breakthrough Performance
At the core of RapidFire AI's innovation is its ability to intelligently orchestrate multiple training jobs simultaneously. The platform splits datasets into randomly distributed "chunks" and cycles different LLM configurations through available GPUs at these chunk boundaries. This approach provides incremental signals on evaluation metrics across all configurations much more quickly than traditional methods.
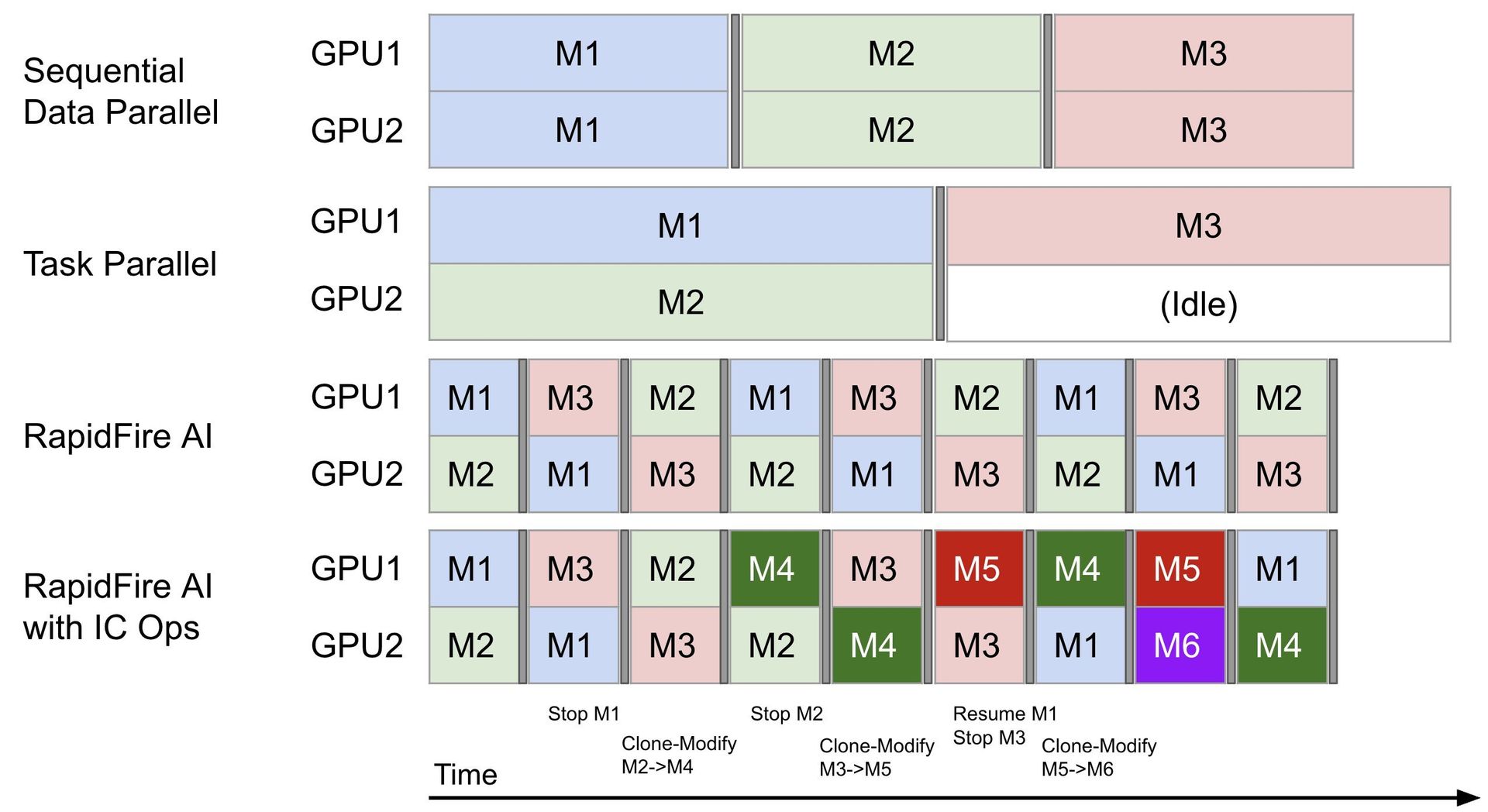
The system employs an efficient shared-memory-based adapter and model spilling/loading mechanism that maintains training stability and consistency while maximizing GPU utilization. This architecture enables what the team calls "hyperparallel experimentation"—running multiple configurations in parallel rather than sequentially.
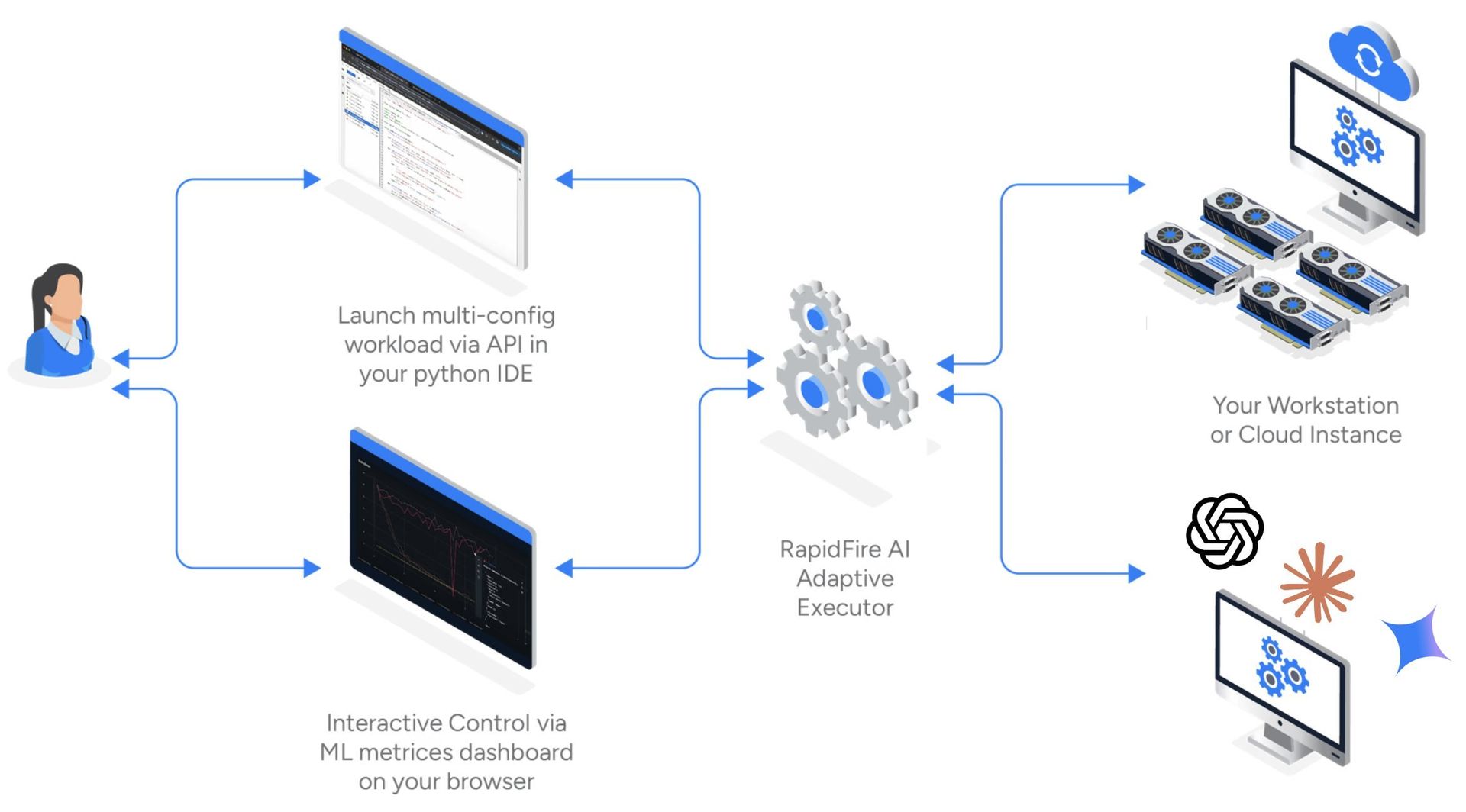
RapidFire AI establishes live three-way communication between the developer's IDE, a metrics dashboard, and a multi-GPU execution backend, creating a seamless workflow for experimentation and iteration.
Key Features for Enhanced Control and Efficiency
The integration with TRL brings several powerful features to developers:
Drop-in TRL Wrappers: RFSFTConfig, RFDPOConfig, and RFGRPOConfig serve as near-zero-code replacements for TRL's standard SFT/DPO/GRPO configs, minimizing the learning curve.
Adaptive Chunk-Based Concurrent Training: By sharding the dataset into chunks and cycling configurations at chunk boundaries, RapidFire enables earlier apples-to-apples comparisons and maximizes GPU utilization.
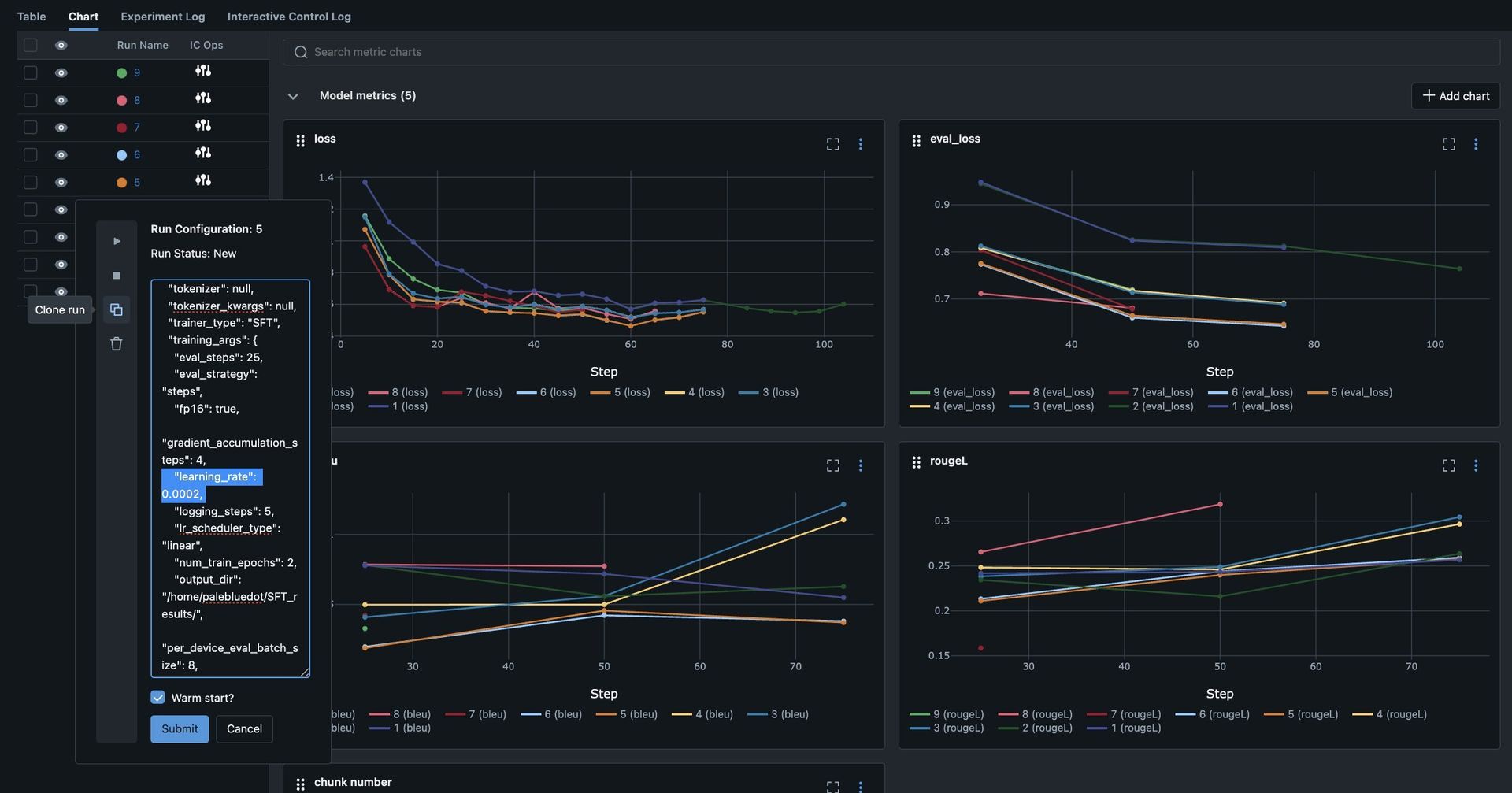
Interactive Control Operations (IC Ops): From the dashboard, developers can Stop, Resume, Delete, and Clone-Modify runs in flight. This allows for immediate resource optimization—stopping underperforming configurations and doubling down on promising ones without job restarts or resource reallocation.
Multi-GPU Orchestration: The scheduler automatically places and orchestrates configurations across available GPUs via efficient shared-memory mechanisms, allowing developers to focus on models and metrics rather than infrastructure plumbing.
MLflow-Based Dashboard: Real-time metrics, logs, and IC Ops are consolidated in one place as soon as experiments begin. Support for additional dashboards like Trackio, W&B, and TensorBoard is planned.
Technical Implementation and Code Example
RapidFire AI's integration is designed to be accessible to TRL users. The minimal code changes required are demonstrated in this SFT example:
from rapidfireai import Experiment
from rapidfireai.automl import List, RFGridSearch, RFModelConfig, RFLoraConfig, RFSFTConfig
from datasets import load_dataset
from transformers import AutoModelForCausalLM, AutoTokenizer
# Setup: load your dataset and define formatting
dataset = load_dataset("bitext/Bitext-customer-support-llm-chatbot-training-dataset")
train_dataset = dataset["train"].select(range(128)).shuffle(seed=42)
def formatting_function(row):
return {
"prompt": [
{"role": "system", "content": "You are a helpful customer support assistant."},
{"role": "user", "content": row["instruction"]},
],
"completion": [{"role": "assistant", "content": row["response"]}]
}
dataset = dataset.map(formatting_function)
# Define multiple configs to compare
config_set = List([
RFModelConfig(
model_name="TinyLlama/TinyLlama-1.1B-Chat-v1.0",
peft_config=RFLoraConfig(r=8, lora_alpha=16, target_modules=["q_proj", "v_proj"]),
training_args=RFSFTConfig(learning_rate=1e-3, max_steps=128, fp16=True),
),
RFModelConfig(
model_name="TinyLlama/TinyLlama-1.1B-Chat-v1.0",
peft_config=RFLoraConfig(r=32, lora_alpha=64, target_modules=["q_proj", "v_proj"]),
training_args=RFSFTConfig(learning_rate=1e-4, max_steps=128, fp16=True),
formatting_func=formatting_function,
)
])
# Run all configs concurrently with chunk-based scheduling
experiment = Experiment(experiment_name="sft-comparison")
config_group = RFGridSearch(configs=config_set, trainer_type="SFT")
def create_model(model_config):
model = AutoModelForCausalLM.from_pretrained(
model_config["model_name"],
device_map="auto", torch_dtype="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_config["model_name"])
return (model, tokenizer)
experiment.run_fit(config_group, create_model, train_dataset, num_chunks=4, seed=42)
experiment.end()
When executed on a 2-GPU machine, this code demonstrates the core advantage of RapidFire AI: instead of training configurations sequentially (Config 1 → wait → Config 2 → wait), both train concurrently. This approach enables reaching comparative decisions 3× sooner on the same resources after both configurations finish processing the first data chunk rather than waiting for sequential completion.
Real-World Performance Benchmarks
Internal benchmarks referenced in the TRL integration page demonstrate the significant performance gains achievable with RapidFire AI:
| Scenario | Sequential Time | RapidFire AI Time | Speedup |
|---|---|---|---|
| 4 configs, 1 GPU | 120 min | 7.5 min | 16× |
| 8 configs, 1 GPU | 240 min | 12 min | 20× |
| 4 configs, 2 GPUs | 60 min | 4 min | 15× |
These benchmarks were conducted on NVIDIA A100 40GB GPUs with TinyLlama-1.1B and Llama-3.2-1B models, showing consistent speedups across different configurations and hardware setups.
Getting Started with RapidFire AI
Adopting RapidFire AI is straightforward, with installation and setup completed in under a minute:
# Install RapidFire AI
pip install rapidfireai
# Authenticate with Hugging Face
huggingface-cli login --token YOUR_TOKEN
# Workaround for current issue
pip uninstall -y hf-xet
# Initialize and start RapidFire AI
rapidfireai init
rapidfireai start
The dashboard launches at http://localhost:3000, providing a centralized interface for monitoring and controlling all experiments.
Supported TRL Trainers
The integration currently supports three key TRL trainers:
- SFT with RFSFTConfig: Supervised Fine-Tuning with RapidFire enhancements
- DPO with RFDPOConfig: Direct Preference Optimization
- GRPO with RFGRPOConfig: Group-wise Reinforcement Learning from Human Preferences
These are designed as drop-in replacements, allowing developers to maintain their existing TRL workflows while gaining significantly more concurrency and control.
The Future of LLM Experimentation
RapidFire AI's integration with Hugging Face TRL represents a significant advancement in how developers approach LLM fine-tuning and post-training. By enabling hyperparallel experimentation and providing real-time control over training runs, the platform addresses critical pain points in the LLM development lifecycle.
As the AI community continues to push the boundaries of what's possible with large language models, tools that optimize resource utilization and accelerate iteration cycles will become increasingly valuable. RapidFire AI's approach to concurrent configuration testing not only saves time and computational resources but also enables more thorough exploration of the model optimization space.
For developers and researchers working with LLMs, this integration offers a compelling proposition: maintain your existing workflows while dramatically improving experimentation efficiency. The ability to clone promising configurations with modified hyperparameters, optionally warm-starting from parent weights, provides a powerful mechanism for rapid model refinement.
In an industry where GPU time remains a precious commodity, innovations like RapidFire AI that maximize utilization without compromising on experimental rigor may well shape the future of how we train and optimize large language models.
Comments
Please log in or register to join the discussion