As AI search engines reshape how users discover information, traditional analytics tools like Google Analytics are becoming increasingly blind. This article reveals why client-side analytics fail to capture AI-driven traffic and provides a practical framework using server logs to measure your true content reach in the AI era.
The AI Analytics Blind Spot: Why Google Misses Your Search Traffic and How to Fix It
Your Google Analytics reports show organic traffic is flat, maybe even declining. Meanwhile, your sales team reports that inbound leads are better qualified than ever. You're not imagining things. This is the AI search analytics gap.
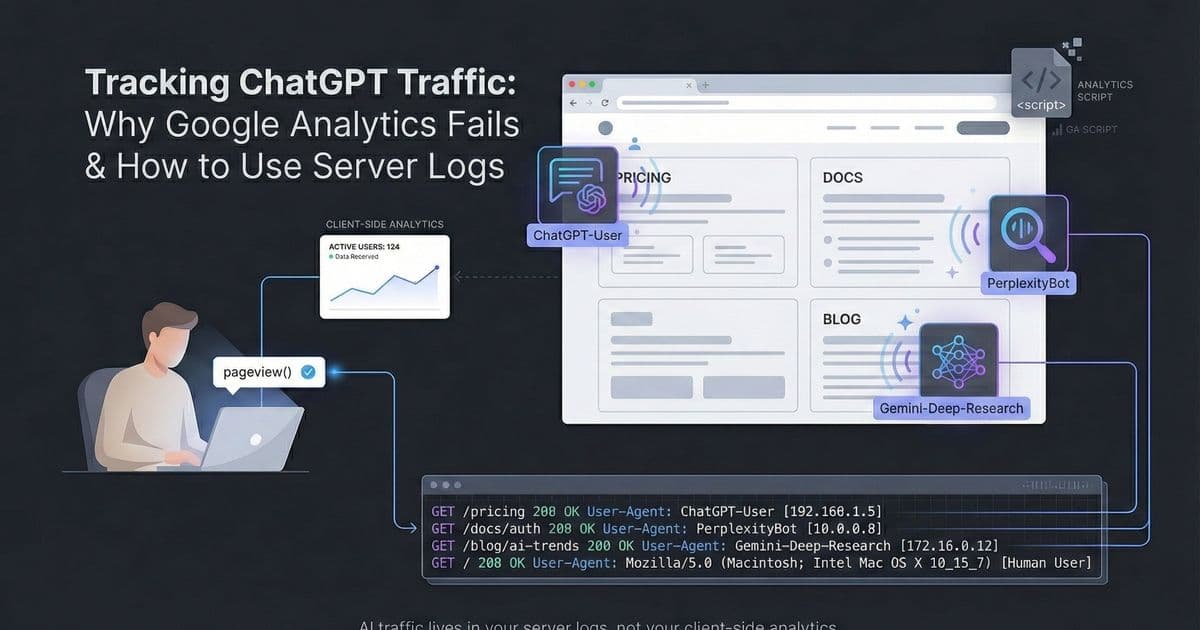
Google Analytics misses most AI search traffic because the bots powering these experiences rarely execute the client-side JavaScript needed to fire a tracking pixel. If you can't measure this traffic, you can't optimize for it. You're investing in content that AI models might ignore, and you can't prove the ROI of your Answer Engine Optimization (AEO) efforts.
This guide explains why client-side analytics fail to capture AI-driven traffic and provides a practical framework for using server-side logs to get the complete picture. You'll learn how to distinguish between Training Crawlers (archival ingestion) and Real-Time Searchers (active user intent). It's time to shift from outdated metrics to a new model that reflects how modern B2B buyers actually find information.
Why Google Analytics Can't Track AI Bots (The JavaScript Gap)
To solve the AI analytics gap, you need to understand its technical origins. The measurement problem isn't a flaw in Google Analytics. It's a fundamental mismatch between how client-side tools work and how AI models interact with the web.
The core issue is the JavaScript Execution Gap. Google Analytics tracking code is JavaScript-based. It requires a browser to download and execute this script to send a tracking event to Google's servers. AI crawlers aren't full browsers. They're built for efficiency, fetching raw HTML to analyze content without running client-side scripts.
Since the GA script never runs, the visit never gets recorded. This interaction is completely invisible to your analytics dashboard.
The Funnel Gap: Ingestion vs. Action
The JavaScript gap isn't the only problem. There's a bigger shift happening in where users actually get value from your content.
In traditional search, value transfer happens on your site when someone visits. In AI search, it happens on the AI's interface when the model provides an answer. When a bot like ChatGPT-User reads your content, it's ingesting your knowledge to synthesize an answer for a user who may never click through to your site.
Think about what this means for measurement:
- Server Logs measure Ingestion (Top of Funnel): This is the AEO equivalent of a Google Search Impression or Indexation. The AI is consuming your value.
- Google Analytics measures Action (Bottom of Funnel): This only tracks when users click a citation link.
Modern AI engines answer questions directly, creating zero-click searches. Your ingestion numbers from logs will be much larger than your referral numbers in GA.
If you only track GA, you're missing the massive volume of users consuming your brand's information inside the AI interface. You're essentially blind to most of your actual reach.
The Privacy Wall makes this measurement challenge worse. Your most valuable technical audiences, the exact people buying tools like ClickHouse or Render, have broken client-side tracking. Many developers use ad blockers or browsers that block tracking pixels by default. For this audience, even direct click-throughs from AI platforms might not register in Google Analytics.
{{IMAGE:3}}
Server-Side Logs vs. Google Analytics: Comparing Data Sources
Client-side analytics show what the browser reports. Server-side logs show what your infrastructure actually experiences. Server logs provide the ground truth for every interaction with your website, a complete and unalterable record of all requests.
A server log is just a text record your web server (Nginx, Apache) or edge network (Vercel, Cloudflare) generates automatically. Each time a bot requests a file, the server records the IP, timestamp, URL, status code, and the User-Agent string.
The User-Agent helps you distinguish AI bots from human users. But in the era of Answer Engine Optimization, you can't treat all bots as generic "traffic." You need to distinguish between two distinct types of AI Crawlers: The Learners and The Searchers.
1. What Are Training Crawlers? (The Learners)
These bots scrape the web massively to build underlying datasets for Large Language Models (LLMs).
- Purpose: To train the model (e.g., GPT-4, Claude 3)
- Frequency: Sporadic, high-volume bursts
- Meaning: High activity here means your content is being archived for future training. It does not indicate a user is asking about you right now.
Examples:
- GPTBot (OpenAI training crawler)
- ClaudeBot (Anthropic training crawler)
- CCBot (Common Crawl)
2. What Are RAG Crawlers? (The Searchers)
These are the bots you need to track for AEO. They activate when a human user asks a question, and the AI needs to browse the live web (RAG - Retrieval Augmented Generation) to find answers.
- Purpose: To answer a specific, real-time user query
- Frequency: Correlated with user demand
- Meaning: A hit from these bots means a user is asking a question right now that your content can answer. This is a high-intent signal.
Examples:
- ChatGPT-User (OpenAI, triggered by a user query)
- PerplexityBot (Perplexity, indexing for real-time answers)
Crucial Analysis Note: If your dashboard lumps GPTBot (Training) with ChatGPT-User (Search), your data is useless. A massive spike in GPTBot might just mean OpenAI is updating its dataset. A spike in ChatGPT-User means your market is active.
Do Google AI Overviews Appear in Server Logs?
Google works differently from OpenAI or Perplexity. Google AI Overviews generally don't trigger a real-time crawl from a unique bot. They generate answers using Google's massive, pre-existing search index (populated by standard Googlebot).
You likely won't see specific "Google AI" traffic in your logs for most queries. The exception is their new deep research agent:
- Gemini-Deep-Research: This agent performs real-time fetching for complex, multi-step deep research tasks in Gemini and will appear in your logs.
How to Configure Server Logs for AI Traffic Analysis: A Step-by-Step Guide
Accessing and analyzing server logs is more straightforward than it sounds, even for modern "serverless" stacks. You set up a pipeline that moves data from your host to where you can query it.
Step 1: Configuring Log Drains (Vercel, AWS, Netlify)
If you're running on modern infrastructure like Vercel, you won't SSH into a server to read text files. Vercel (and similar providers like Netlify or Heroku) uses Log Drains instead.
Logs on these platforms are ephemeral. They disappear quickly. To analyze them, configure a Log Drain to stream every request to permanent storage.
- The Destination: For many technical clients, this means streaming logs to Datadog or directly into a database/warehouse like ClickHouse, Snowflake, or BigQuery.
- The Request: Ask your DevOps engineer: "Can we configure a Vercel log drain to send our production HTTP access logs to [Your Data Warehouse]?"
Step 2: SQL Query to Filter RAG Bots (ChatGPT, Gemini, Perplexity)
Once data is in your warehouse, you need to filter it. This is where distinguishing Training from Search becomes vital. Write a query that excludes training bots and includes search bots.
- Exclude: GPTBot, ClaudeBot, Bytespider
- Include: ChatGPT-User, PerplexityBot, Gemini-Deep-Research
Note: Always cross-reference User-Agents with IP verification. OpenAI publishes their official IP ranges for GPTBot and ChatGPT-User, letting you filter out spoofed actors.
Here's a simple SQL query concept:
SELECT * FROM access_logs
WHERE (user_agent LIKE '%ChatGPT-User%'
OR user_agent LIKE '%PerplexityBot%'
OR user_agent LIKE '%Gemini-Deep-Research%'
OR user_agent LIKE '%OAI-SearchBot%')
AND url NOT LIKE '%.css'
AND url NOT LIKE '%.js'
Step 3: Analyzing AI Behavior
With clean data, you can answer business-critical questions:
- Ingestion Frequency: How often does PerplexityBot hit your pricing page? Frequent hits mean users are actively comparing your pricing against competitors in Perplexity.
- Content Preferences: Which documentation pages does ChatGPT-User visit most? This shows which technical hurdles your prospects are trying to solve using AI assistance.
- Crawl Errors: Are RAG bots hitting 403 or 404 errors? If ChatGPT-User can't read your page due to server errors, you're invisible to users asking questions.
Step 4: Setting Up a Basic Dashboard
To make this analysis repeatable, work with your data team to build a simple view in your BI tool (Looker, Tableau, or Superset).
The "AI Pulse" Dashboard:
- Metric: Daily Unique Requests from ChatGPT-User.
- Metric: Daily Unique Requests from PerplexityBot.
- Table: Top 10 URLs crawled by RAG bots (excluding homepage).
For example, Zapier monitors crawls on their integration docs. A sudden spike in ChatGPT-User crawling their "LangChain Integration" page signals surging developer interest in that specific integration. The marketing team then doubles down on related content.
Key AEO Traffic Metrics: Measuring Content Ingestion and Citation Freshness
AI search requires a fundamental shift in how we measure performance. Traditional metrics like sessions and referral traffic are becoming lagging indicators. Real value gets created inside the AI interface, often before any click happens.
This new measurement model uses two types of indicators.
Leading Indicators (from Bot Traffic)
These metrics measure direct interaction between AI models and your content.
- Content Ingestion Rate (CIR): The number of hits from RAG-specific agents (like ChatGPT-User) on your pillar content pages per week. Think of this as the "Impression" count for the AI era. High CIR means your content is being read and synthesized for answers, even if the user stays on ChatGPT.
- Citation Freshness: Time between a content update and subsequent re-crawl from a RAG bot. Shorter time shows the AI engine trusts your site as a "live" source of truth.
Lagging Indicators (from Business Data)
These metrics connect AI influence to tangible business outcomes.
- High-Intent Conversion Rate: Users clicking through from AI citations (in Perplexity or ChatGPT) often have higher intent than generic searchers. They've been "pre-qualified" by the AI's answer.
- Increase in Branded Search: As AI models cite your brand as an authority, users start bypassing AI to search for your company name directly.
- Correlation Analysis: Map your Leading Indicators against your AI Share of Voice (SoV). Does a 50% increase in PerplexityBot activity on your "Enterprise Security" page correlate with more demo requests 14 days later?
| Characteristic | AI Citation Traffic | User Click-Through Traffic |
|---|---|---|
| Actor | RAG Bot (e.g., ChatGPT-User) | Human User |
| Intent | Fetch live data to answer a user prompt | Get detailed info after an AI summary |
| How to Track | Server-side logs (Log Drains) | Google Analytics (Direct/Organic) |
| What it Signifies | Your content is being synthesized for a user. | Your AI-generated answer drove action. |
| Optimization Goal | Increase Content Ingestion Rate. | Increase conversion on landing pages. |
By combining server-side data with business metrics, you build a comprehensive view of your AI search performance, independent of AI platforms' "black box" nature.
Real-World Examples
DevTools Example (Strategic Content Gap)
A database company like MotherDuck uses server logs to see PerplexityBot heavily crawling their "Serverless SQL" blog post. The logs also show the bot trying to guess URLs like /vs-snowflake or /vs-databricks, which return 404s.
- The Insight: Users are asking Perplexity to compare MotherDuck against specific incumbents. The AI looks for direct comparisons that don't exist.
- The Action: The marketing team creates dedicated Competitor Comparison pages. When Perplexity synthesizes answers, it references MotherDuck's own objective data rather than third-party reviews.
API-first SaaS Example (Technical Optimization)
An infrastructure API company notices ChatGPT-User frequently crawling their "Authentication" and "Error Codes" documentation, often retrying requests or hitting adjacent pages rapidly.
- The Insight: Developers use ChatGPT to write code or debug integrations, but the AI struggles to parse documentation trapped in complex, client-side rendered JavaScript tabs.
- The Action: The engineering team refactors these pages to use semantic HTML and adds HowTo schema. ChatGPT can now cleanly extract code snippets, generating working code for users instead of hallucinations.
The Path Forward
Information discovery has shifted from browser-first to AI-first. Our measurement strategies need to evolve too.
Client-side analytics like Google Analytics still matter. They show what happens after a human clicks. But they're blind to the crucial first step: AI models ingesting the knowledge that powers users' answers.
Server-side logs, specifically filtered for RAG crawlers, are the only way to see this foundational interaction.
To start this transition, take these three steps:
- Configure your Log Drain. Whether you use Vercel, AWS, or bare metal, set up a pipeline to send HTTP logs to a queryable database or warehouse.
- Filter your queries. Distinguish between Training (GPTBot) and RAG (ChatGPT-User, PerplexityBot, Gemini-Deep-Research).
- Perform your first analysis. Check your top 5 pillar pages. How many times did ChatGPT-User request them in the last 30 days? This number is your baseline for measuring your AI Share of Voice.
Source: This article is based on content originally published at https://www.tryzenith.ai/blog/tracking-ai-search-traffic-server-logs
Comments
Please log in or register to join the discussion