
For the first time, AI models from Google and OpenAI achieved gold-medal scores at the prestigious International Mathematical Olympiad, solving five of six complex problems. Despite this leap in machine reasoning, the programs fell short of the perfect scores attained by human competitors, exposing lingering gaps in logic and efficiency. The breakthrough underscores AI's rapid evolution but raises urgent questions about the staggering computational and environmental costs of its progress.
AI Clinches Gold at Math Olympiad, But Human Teens Still Outpace the Machines
In a watershed moment for artificial intelligence, experimental models from Google DeepMind and OpenAI have secured gold-level scores at the 66th International Mathematical Olympiad (IMO)—the first time AI has reached such heights in one of the world’s most rigorous intellectual arenas. Hosted in Queensland, Australia, this year’s competition saw 641 elite teenage mathematicians from 112 countries tackle six fiendishly complex problems within a grueling 4.5-hour window. The AI entrants matched this pace, solving five problems to earn 35 out of 42 possible points, placing them among the top 10% of human participants. Yet, they couldn’t surpass the five teenagers who achieved perfect scores, highlighting a persistent chasm between machine computation and human ingenuity.
The Logic Gap: Why Math Remains AI's Nemesis
Mathematics, with its demand for flawless, deterministic reasoning, has long been a stumbling block for generative AI. Unlike creative or linguistic tasks, math problems typically have only one correct solution—no room for probabilistic approximations. As explained in the source material, models like ChatGPT and Google Gemini operate by breaking inputs into tokens and predicting likely output sequences rather than executing step-by-step logic. This token-based approach can falter even on basic arithmetic, as seen when ChatGPT miscalculated 4596 × 4859:
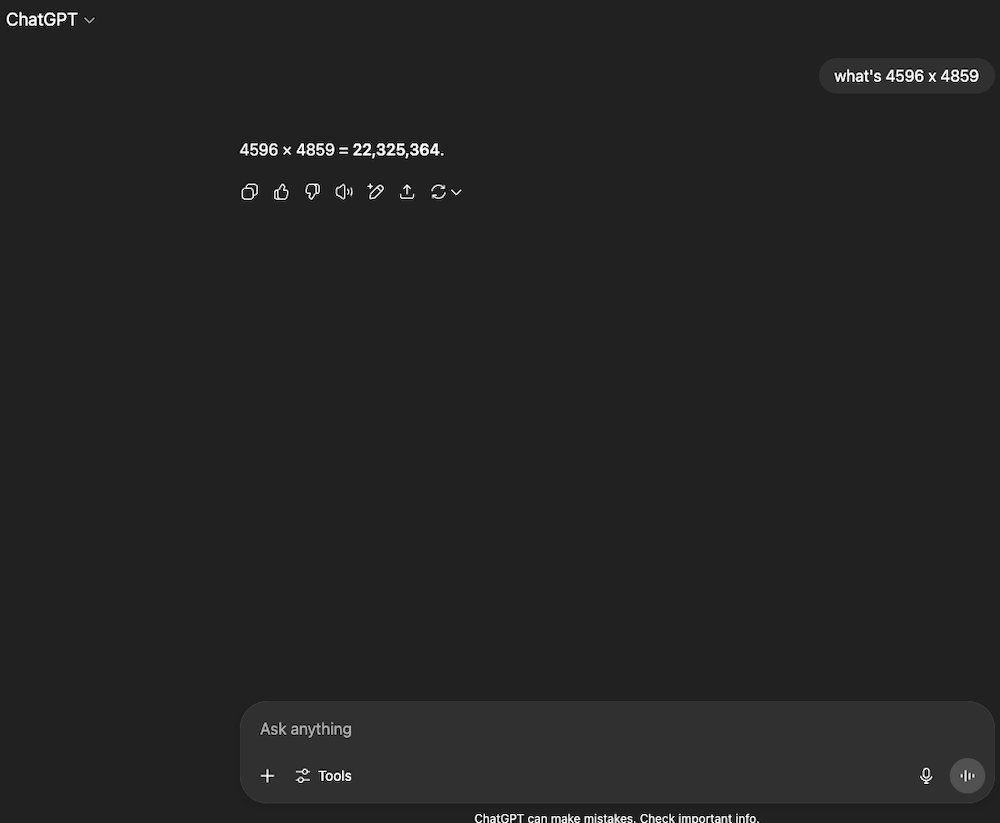
"To an AI, an answer is just the most likely string of tokens. Humans, however, process them as words, sentences, and complete thoughts," notes the analysis. This fundamental disconnect explains why advanced models still struggle with the IMO’s abstract problems, which require intuitive leaps and structured proof-building alien to today’s transformer architectures.
From Silver to Gold: AI's Accelerated Ascent
Google’s performance marks a dramatic year-over-year improvement. In 2024, its DeepMind model scored a silver medal by solving four problems but required 2-3 days of computation—far exceeding the IMO’s time constraints. This year, both Google and OpenAI’s systems delivered results within the 4.5-hour limit, with solutions that impressed judges with their clarity. IMO president Gregor Dolinar remarked in Google’s announcement: "Their solutions were astonishing... IMO graders found them to be clear, precise and most of them easy to follow." This refinement in explanatory reasoning suggests progress toward more transparent, trustworthy AI systems—a critical need for fields like scientific research and cybersecurity.
The Hidden Cost: Energy, Oversight, and Unanswered Questions
Despite the milestone, significant caveats shadow AI’s triumph. Organizers couldn’t verify the computational resources expended during the test or confirm whether human oversight guided the models. This opacity underscores broader industry concerns: Training and running cutting-edge AI demands colossal energy, with data centers consuming electricity and water at unsustainable rates. Watchdogs estimate the AI sector could soon rival entire nations like Argentina in power usage, potentially exacerbating climate impacts if reliant on fossil fuels. As the source starkly notes, "That’s a problem that AI—nor its makers—have yet to solve."
For developers and tech leaders, this achievement is a double-edged sword. It demonstrates AI’s growing prowess in symbolic reasoning, paving the way for applications in theorem proving, code verification, and educational tools. Yet, it also spotlights the inefficiencies of brute-force computation. As we celebrate machines that think, we must grapple with whether their brilliance justifies the planetary toll—and whether true innovation lies not just in matching human minds, but in doing so without consuming the future they’re meant to build.
Source: Popular Science
Comments
Please log in or register to join the discussion