While Graph Neural Networks dominate AI research, their real-world impact is hampered by inefficiency, flawed benchmarks, and academic incentives. This critique reveals how simpler embedding methods often match GNN performance, arguing that progress hinges on scalable implementations and fundamental understanding rather than architectural tweaks. Discover why the future of graph AI lies in computational pragmatism.
The Overlooked Limits of Graph Neural Networks
Graph Neural Networks (GNNs) have surged as a darling of AI research, promising breakthroughs in modeling complex relationships from social networks to molecular structures. Yet, beneath the torrent of academic papers and benchmarks lies a sobering reality: GNNs frequently offer marginal gains over simpler, faster methods while consuming disproportionate resources. As one researcher bluntly states, "I’m only lukewarm on Graph Neural Networks." This skepticism isn't nihilism—it's a call to refocus on what truly advances the field.
The Compression Principle: Graphs as Matrices in Disguise
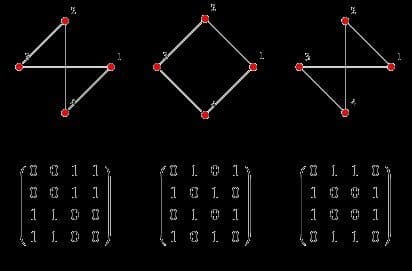
At their core, graphs are adjacency matrices—square grids encoding connections between nodes. Labeling them "non-euclidean" obscures this simplicity. In an ideal world, we'd use these matrices directly for tasks like node embeddings or link prediction. But real-world graphs are sparse, making full-matrix operations computationally prohibitive.
 Adjacency matrices reveal graphs as structured data, not mystical constructs.
Adjacency matrices reveal graphs as structured data, not mystical constructs.
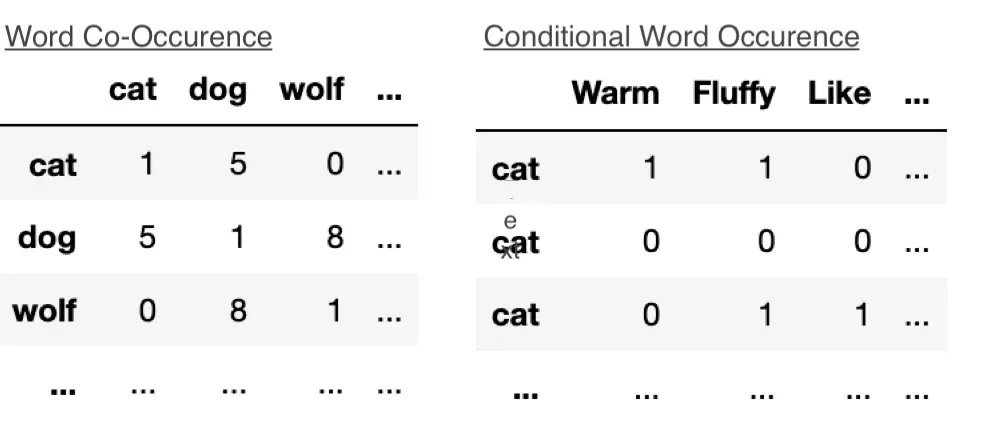
Enter embeddings: techniques that compress graph information into lower-dimensional vectors. First-order methods like Laplacian Eigenmaps or ProNE factorize the adjacency matrix directly. Remarkably, for tasks like node classification or clustering, they often rival—or even surpass—GNNs. As the source notes:
"For many graphs, simple first-order methods perform just as well on graph clustering and node label prediction tasks as higher-order embedding methods. Higher-order methods are massively computationally wasteful for these use cases."
The Language Model Parallel: Upsampling Isn't Always Better
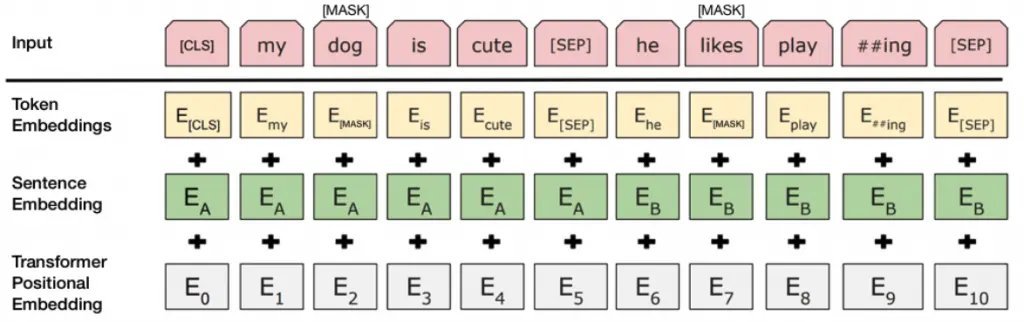
NLP offers a revealing analogy. Early word embeddings like Word2Vec and GloVe factorized co-occurrence matrices—effectively first-order graph representations of word relationships. Modern language models like BERT "upsample" this by capturing context through higher-order conditional dependencies.
 BERT-style models expand co-occurrence matrices combinatorially, akin to higher-order graph methods.
BERT-style models expand co-occurrence matrices combinatorially, akin to higher-order graph methods.
But just as summing Word2Vec vectors often suffices for sentence embeddings, first-order graph embeddings (e.g., ProNE or GGVec) frequently match GNNs in performance. Higher-order methods like Node2Vec or GNNs shine only in specific tasks like link prediction—and even then, gains vanish for synthetic graphs. Visualizations underscore this:
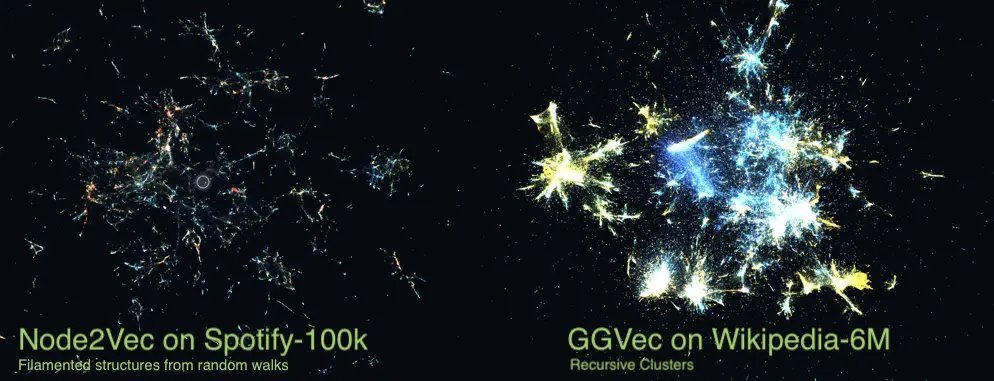 {{IMAGE:5}}
Node2Vec embeddings (top) show filament-like artifacts from random walks, while simpler methods yield cleaner clusters (bottom).
{{IMAGE:5}}
Node2Vec embeddings (top) show filament-like artifacts from random walks, while simpler methods yield cleaner clusters (bottom).
Why Academia's Incentives Stifle Progress
The GNN boom masks a reproducibility crisis. Papers often:
- Propose minor architectural tweaks with "cute" acronyms.
- Benchmark on tiny datasets like Cora or PubMed (2K–20K nodes), which fail to differentiate methods meaningfully.
- Skip rigorous hyperparameter tuning for baselines.
Node2Vec exemplifies this: its 7,500+ citations dwarf its predecessor DeepWalk, yet it adds little beyond tunable hyperparameters. Worse, reference implementations are notoriously inefficient—embedding 150K nodes can take 32 hours versus 3 minutes with optimized libraries like Nodevectors. As a result:
"Grid-searching Node2Vec’s p and q is wasted effort compared to tuning DeepWalk—but terrible implementations deter researchers."
Efficiency: The Unsexy Frontier of Real-World Impact
Breakthroughs like AlexNet or Word2Vec succeeded not through novelty alone, but via scalable implementations on commodity hardware. GNNs lag here. Key bottlenecks include:
- Data Structures: Libraries like NetworkX rely on pointer-based graphs, causing memory bottlenecks. CSR matrices (used in Nodevectors) or edgelists (like DGL’s backend) enable faster, disk-mappable operations for large graphs.
- Sampling Strategies: Methods that update embeddings edge-by-edge (e.g., GGVec) or via neighborhood sampling scale better than full-graph approaches. Pinterest and Instagram already leverage such techniques for recommendations.
- Architectural Overemphasis: OpenAI’s scaling laws show model size often trumps architecture. Transformers now challenge CNNs and GNNs alike—yet we’re "tremendously over-researching" layers while ignoring computational pragmatism.
Where Graph AI Should Go Next
The path forward demands:
- Task-Specific Understanding: Clarify why certain graphs (e.g., social networks vs. biomolecules) respond to different methods.
- Robust Benchmarks: Initiatives like OpenGraphsBenchmark (OGB) must replace tiny datasets with real-world scale.
- Fundamental Research: Explore whether embeddings like Poincaré disks can better encode directed relationships.
As the author concludes, throwing "spicy new layers" at toy datasets helps no one. True innovation lies in making graph methods fast, scalable, and comprehensible—because without efficiency, even the cleverest architecture gathers dust.
Comments
Please log in or register to join the discussion