Understanding whether your PostgreSQL database is dominated by read or write operations is crucial for effective tuning and scaling. This deep dive reveals how to analyze workload patterns using internal statistics and provides targeted optimization strategies for each scenario. Learn why treating reads and writes as equal metrics is a critical mistake and how to leverage Postgres' internal metadata for actionable insights.
When database performance falters, PostgreSQL administrators instinctively ask: "Is this a read problem or a write problem?" The answer fundamentally changes optimization strategies—yet many teams operate without truly understanding their workload profile.
As David Christensen of Crunchy Data explains, while application logic might suggest workload patterns (social apps = read-heavy, IoT systems = write-heavy), reality often involves complex hybrids. Worse, reads and writes aren't equivalent in cost:
- Reads often leverage cached data in shared buffers, requiring minimal I/O
- Writes trigger WAL entries, index updates, TOAST operations, and background flushes—each change potentially amplifying I/O demands
"Every write operation also has potential read overhead," Christensen notes. "The cost of reading is much lower than writing."
Quantifying the Imbalance
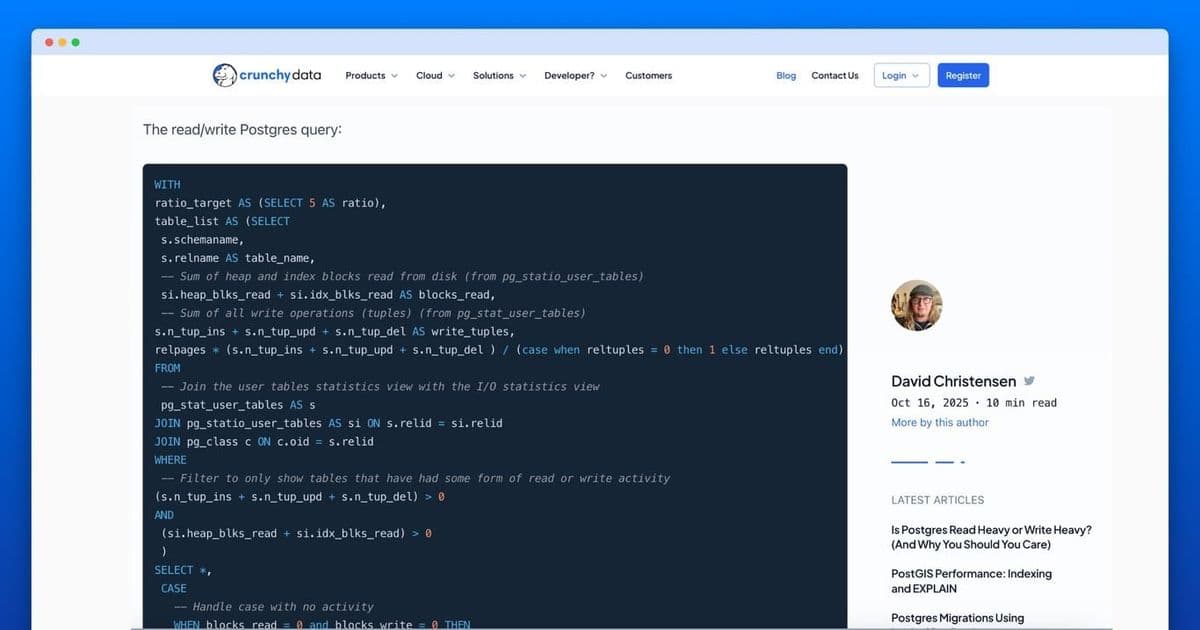
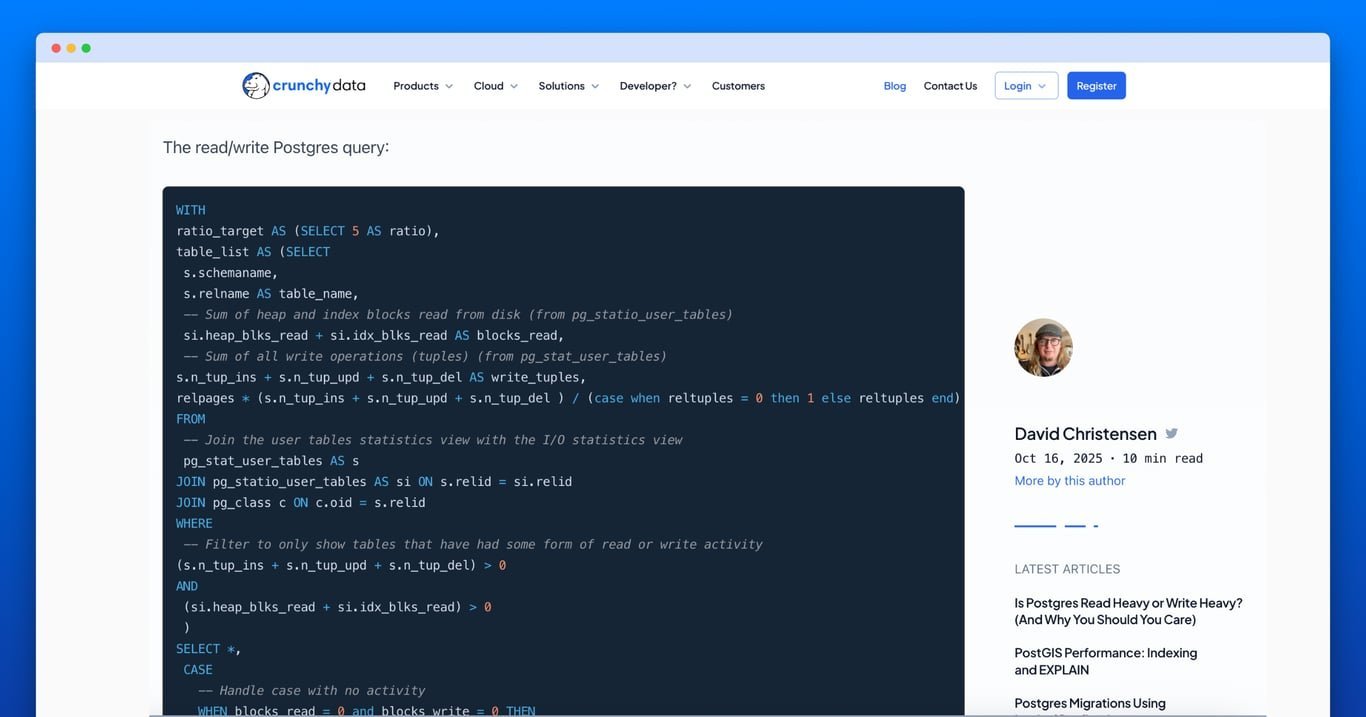
Christensen's diagnostic query estimates read/write ratios using PostgreSQL's internal statistics. It calculates:
- Blocks read from
pg_statio_user_tables - Write operations (inserts/updates/deletes) from
pg_stat_user_tables - Blocks written by estimating page density via
relpages/reltuples
WITH
ratio_target AS (SELECT 5 AS ratio),
table_list AS (SELECT
s.schemaname,
s.relname AS table_name,
si.heap_blks_read + si.idx_blks_read AS blocks_read,
s.n_tup_ins + s.n_tup_upd + s.n_tup_del AS write_tuples,
relpages * (s.n_tup_ins + s.n_tup_upd + s.n_tup_del) /
(CASE WHEN reltuples = 0 THEN 1 ELSE reltuples END) AS blocks_write
FROM
pg_stat_user_tables AS s
JOIN pg_statio_user_tables AS si ON s.relid = si.relid
JOIN pg_class c ON c.oid = s.relid
WHERE
(s.n_tup_ins + s.n_tup_upd + s.n_tup_del) > 0
AND (si.heap_blks_read + si.idx_blks_read) > 0
)
SELECT *,
CASE
WHEN blocks_read = 0 AND blocks_write = 0 THEN 'No Activity'
WHEN blocks_write * ratio > blocks_read THEN
CASE
WHEN blocks_read = 0 THEN 'Write-Only'
ELSE ROUND(blocks_write::numeric / blocks_read::numeric, 1)::text || ':1 (Write-Heavy)'
END
WHEN blocks_read > blocks_write * ratio THEN
CASE
WHEN blocks_write = 0 THEN 'Read-Only'
ELSE '1:' || ROUND(blocks_read::numeric / blocks_write::numeric, 1)::text || ' (Read-Heavy)'
END
ELSE '1:1 (Balanced)'
END AS activity_ratio
FROM table_list, ratio_target
ORDER BY (blocks_read + blocks_write) DESC;
Sample output:
| schemaname | table_name | blocks_read | write_tuples | blocks_write | ratio | activity_ratio |
|---|---|---|---|---|---|---|
| public | audit_logs | 2 | 1,500,000 | 18,519 | 5 | 9259.5:1 (Write-Heavy) |
| public | orders | 8 | 4 | ~0 | 5 | Read-Only |
Tuning for the Workload Extremes
For write-heavy systems:
- ⚡ Prioritize I/O: NVMe storage and increased IOPS
- 📉 Minimize indexes: Reduce update overhead on non-critical indexes
- 🛠️ Tune WAL: Adjust
wal_buffersandwal_compression - ⏱️ Optimize checkpoints: Balance
checkpoint_timeoutandcheckpoint_completion_target - 🔥 Leverage HOT updates: Adjust
fillfactorfor update-intensive tables
For read-heavy systems:
- 🧠 Maximize caching: Optimize
shared_buffersandeffective_cache_size - 🔍 Refine indexing: Add targeted indexes and monitor usage
- 🌐 Scale horizontally: Implement read replicas to distribute load
- 🧩 Optimize queries: Use
EXPLAIN ANALYZEto eliminate inefficiencies
The Reality of Postgres Workloads
Most PostgreSQL deployments skew read-heavy—Christensen estimates a 10:1 read-to-write ratio as the threshold for write-heavy classification. But as cloud-native applications evolve, understanding your specific profile through continuous monitoring (using tools like pg_stat_statements alongside Christensen's query) enables precision tuning that generic benchmarks can't match.
Ultimately, recognizing that reads and writes impose fundamentally different costs transforms database management from reactive firefighting to strategic optimization. Whether scaling replicas for analytics or rearchitecting high-throughput ingestion pipelines, this distinction separates adequate performance from exceptional efficiency.
Comments
Please log in or register to join the discussion