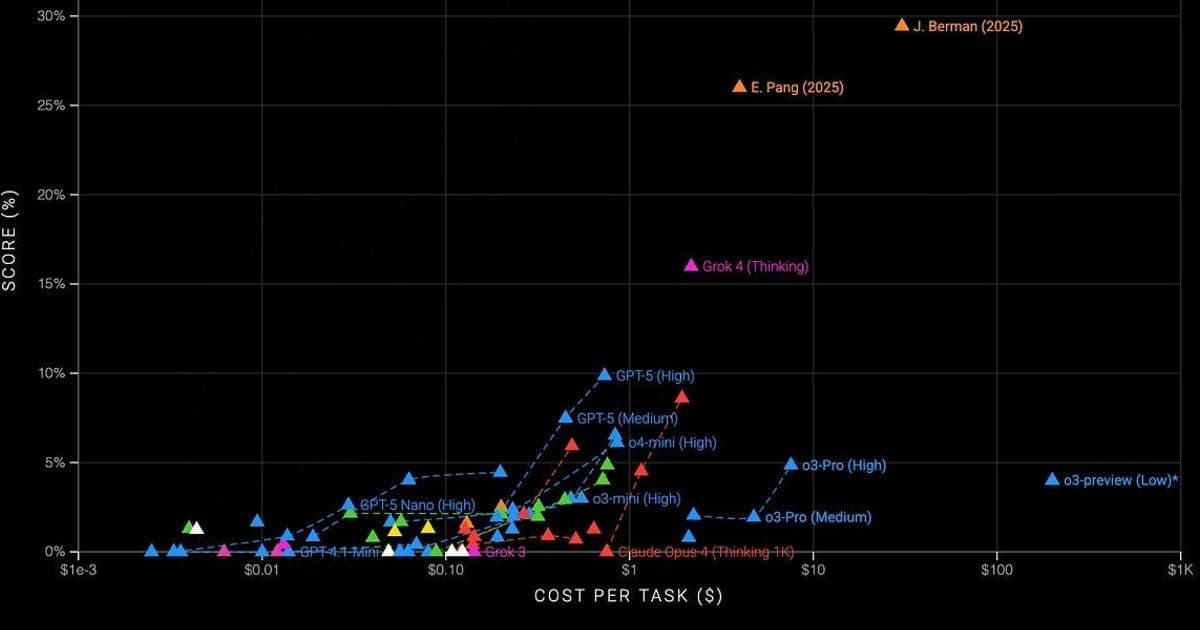
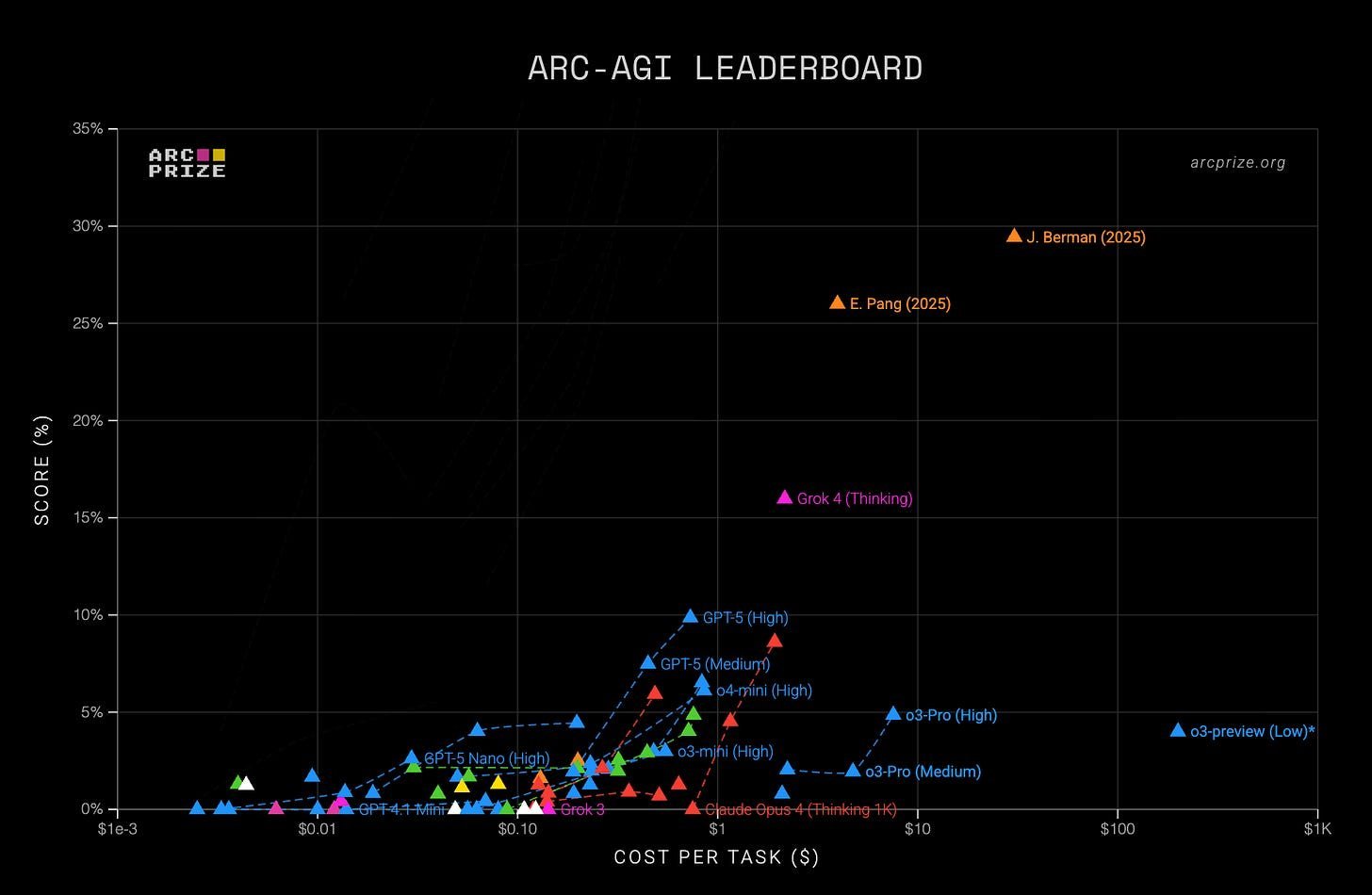
Jeremy Berman achieves new SOTA on ARC-AGI using evolutionary refinement of English instructions instead of Python, solving 79.6% of abstract reasoning puzzles at 25x lower cost. This breakthrough exposes fundamental limitations in LLM reasoning while pointing toward more generalizable AI architectures.
The Reasoning Gap: When Math Olympians Fail Children's Puzzles
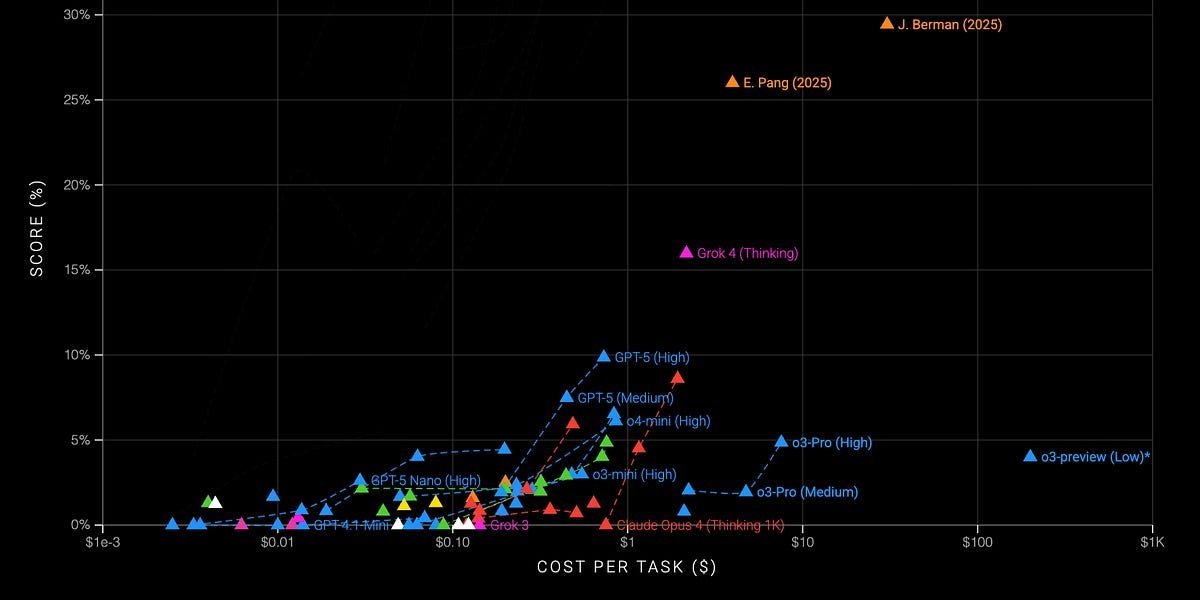
Large language models ace advanced mathematics yet falter at simple visual puzzles solvable by humans in seconds. This paradox lies at the heart of the ARC-AGI benchmark, designed by François Chollet to measure genuine generalization—the ability to solve novel problems absent from training data. For years, it remained AI's toughest nut to crack, with top models scoring just 25% on its latest iteration. Today, that ceiling has shattered through an unexpected approach: replacing code with carefully evolved English instructions.
Inside ARC-AGI's Abstract Reasoning Challenges
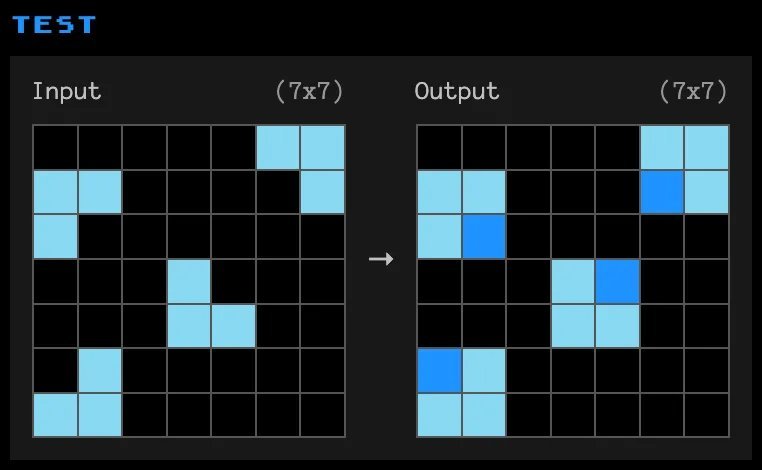
ARC tasks present input/output grid transformations like this example:
*Humans quickly infer the rule: "Fill all cells where the row and column both contain at least one blue cell." LLMs historically struggle with such abstraction. Version 2 intensifies complexity:

"These puzzles require multi-step reasoning about spatial relationships," explains researcher Jeremy Berman. "While humans approach 100% accuracy, prior AI peaks capped at 25%—until now."
The Evolutionary Leap: From Python to Plain English
Berman's previous SOTA used evolutionary methods to generate Python functions. But ARC-v2's complexity exposed limitations: "Transformations became too nuanced for elegant code," he notes. His radical pivot? Evolving natural language instructions instead.
The Architecture:
- Initial Generation: Grok-4 produces 30 English instruction candidates (e.g., "Identify symmetrical patterns and invert colors along the axis")
- Fitness Testing: Sub-agents score instructions against training examples by comparing predicted vs. actual grids
- Evolutionary Refinement:
- Individual Revision: Top candidates are refined using error feedback (e.g., showing ASCII diffs of mistakes)
- Pooled Revision: Best instructions merge into hybrid solutions
"We're breeding instructions like biological traits," says Berman. "The system performs test-time compute by simulating how each 'genetic line' would solve puzzles it has never seen."
The approach generated 40 candidates per task using 36 dynamic prompts, achieving 79.6% on ARC-v1 (25x cheaper than prior SOTA) and 29.4% on v2—a 17% absolute improvement.
Why This Matters for AGI Development
Berman's results reveal critical insights about LLM reasoning:
- Dead Reasoning Zones: Models exhibit catastrophic inconsistencies when encountering novel patterns, confidently asserting false conclusions even when shown contradictions
- The Fused Circuit Problem: Current LLMs learn domain-specific reasoning (math-logic, code-logic) rather than a universal reasoning kernel
"Humans have a transferable logic core," Berman observes. "LLMs need reinforcement learning to bake consistent reasoning into their weights—not just pattern recognition."
This evolutionary prompt engineering suggests a path forward: treating language not just as input/output, but as a mutable substrate for refining reasoning itself. As Berman concludes: "When models apply logic as consistently as humans across arbitrary domains, that’s when we’ll have AGI."
Source: Jeremy Berman's Substack
Comments
Please log in or register to join the discussion