When developers wonder whether to adopt Fil‑C’s stricter memory safety or stick with Clang’s well‑known AddressSanitizer, the numbers don’t point to a clear winner. A side‑by‑side benchmark reveals that Fil‑C can outperform ASAN in allocation‑heavy workloads, yet falls behind in lookups as memory pressure grows.
The Context
In the world of C++ memory safety, two tools often surface in the same conversation: Fil‑C and Clang’s AddressSanitizer (ASAN). While ASAN is a mature, widely‑used runtime checker that flags classic memory errors—buffer overflows, use‑after‑free, double frees—Fil‑C takes a stricter stance. It not only catches the usual suspects but also flags undefined‑behaviour cases where a pointer legitimately points inside a buffer but is out of bounds relative to its provenance.
A recent post on Bannalia’s blog asked the practical question: How do these tools compare in terms of execution time when used with Boost.Unordered containers? The author updated their benchmarking repository to include results for:
- Clang 18 (plain, release mode)
- Clang 18 + ASAN (release mode, with sanitisation enabled)
- Fil‑C v0.674 (release mode)
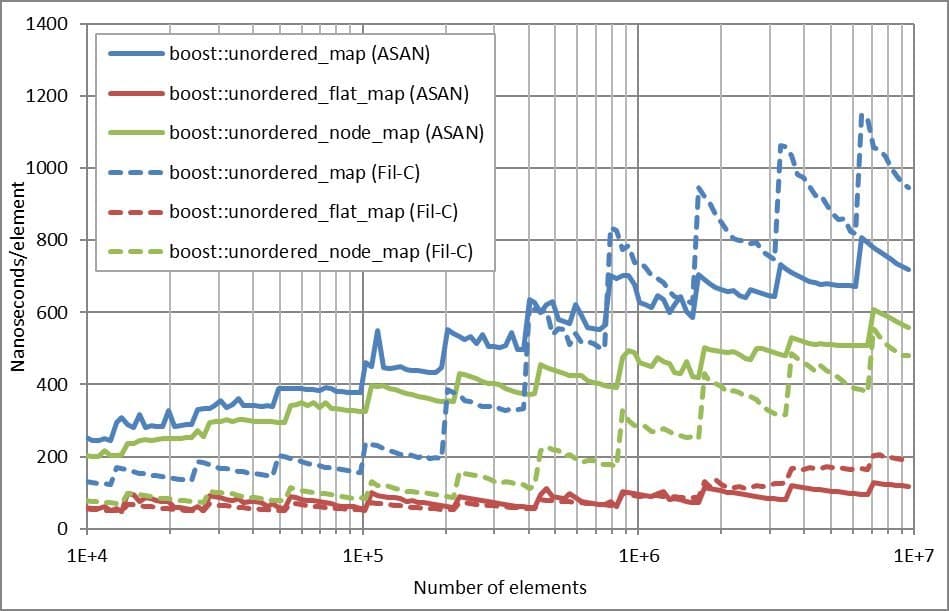
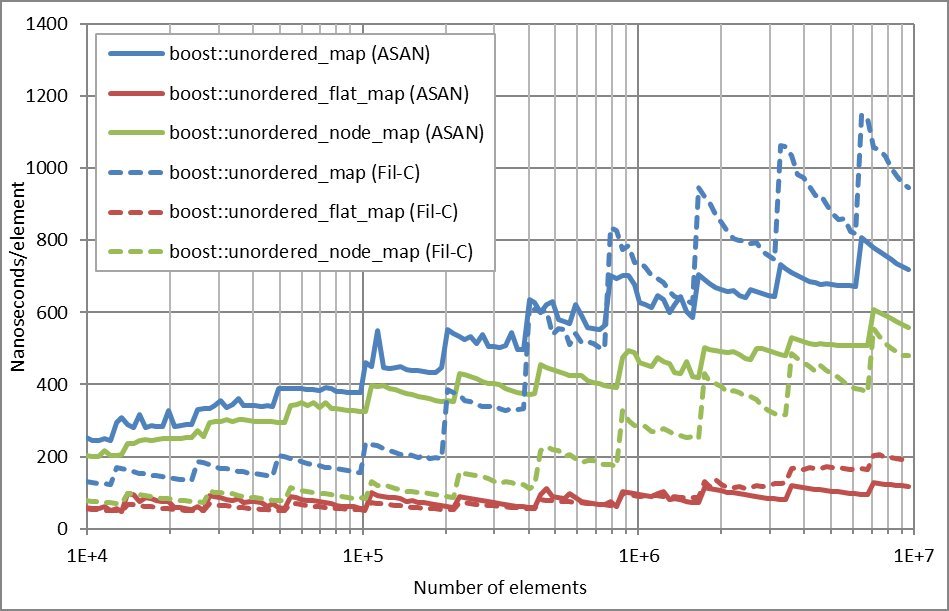
All tests ran on the same hardware, with identical compiler flags, and measured nanoseconds per element for three Boost.Unordered containers: boost::unordered_map, boost::unordered_flat_map, and boost::unordered_node_map.
Source: http://bannalia.blogspot.com/2025/11/comparing-run-time-performance-of-fil-c.html
The Numbers at a Glance
The benchmark plots (shown in the article’s main image) depict solid lines for Clang/ASAN and dashed lines for Fil‑C. Four scenarios were evaluated:
- Insertion only – allocating new entries.
- Lookup only – reading existing entries.
- Mixed allocation/lookup – a realistic workload.
- Large working set – stressing memory as the dataset grows.
Allocation‑Heavy Workloads
When the benchmark involved frequent allocations and deallocations, Fil‑C consistently outperformed ASAN. The difference shrank only when the working set exceeded a certain threshold, at which point ASAN’s overhead began to surface.
“Fil‑C seems to perform better when allocation/deallocation is involved, except for insertion when the memory working set gets past a certain threshold.” – author’s observation.
Lookup‑Heavy Workloads
For read‑heavy scenarios, Fil‑C lagged behind. The gap widened as more memory was used, suggesting that the stricter provenance checks introduce additional indirection or bounds checks that pay off less during lookups.
“For lookup, Fil‑C is generally worse, and the gap increases as more memory is used.”
Why the Divergence?
The author admits a lack of deep knowledge about the internals of both tools. However, a few educated guesses can be made:
- ASAN’s instrumentation is lightweight for lookups; it mainly wraps memory accesses with guard checks and a shadow memory map. Allocation overhead is significant because it instruments every
malloc/free. - Fil‑C’s provenance checks add per‑pointer metadata and bounds verification, which can be expensive during lookups, especially when the data structure is large and cache‑line friendly.
- Cache behavior may differ: ASAN’s shadow memory can cause cache misses, whereas Fil‑C’s tighter checks might keep the working set more localized.
A deeper analysis would require inspecting the generated LLVM IR and profiling the hot paths, which is beyond the scope of the current post.
Takeaway for Practitioners
If your project’s primary concern is allocation safety—for instance, a server that churns through short‑lived objects—Fil‑C could offer a performance advantage over ASAN. Conversely, if you’re dealing with read‑heavy workloads or need to minimize lookup latency, sticking with ASAN (or perhaps a hybrid approach) might be wiser.
Ultimately, the choice hinges on the profile of your application and the trade‑off you’re willing to accept between safety guarantees and performance.
A Call for Community Insight
The author invites further discussion: "A deeper analysis would require knowledge of the internals of both tools that I, unfortunately, lack." If you’ve run similar benchmarks or have insights into Fil‑C’s implementation, sharing your findings could help the community make more informed decisions.
This article was originally published on Bannalia’s blog and has been adapted for a technical audience.
Comments
Please log in or register to join the discussion