Tiger Data unveils Fluid Storage, a next-generation distributed block storage architecture designed to overcome the rigidity of traditional 'elastic' cloud storage like EBS. Featuring zero-copy forks, true bi-directional elasticity, and synchronous replication, it provides a Postgres-compatible foundation enabling instant environment cloning and agent-driven workflows while charging only for consumed capacity. This foundational shift addresses the critical need for storage that moves as fluidly
The limitations of today's "elastic" cloud storage – slow snapshots, rigid scaling, wasted allocated capacity – are becoming painfully apparent as autonomous agents take on more development and operational tasks. Agents spin up, test, and tear down environments continuously, demanding infrastructure that can fork, scale, and recover instantly. Tiger Data, operating tens of thousands of Postgres instances, encountered these EBS bottlenecks firsthand, prompting them to build Fluid Storage: a fundamentally reimagined distributed block layer.
Beyond Elastic: The Era of Fluid Infrastructure
Traditional cloud storage like Amazon EBS solved decoupling compute from storage but fell short of true elasticity. Volume resizing imposes cooldowns (6-24 hours), shrinking is impossible, and users pay for allocated space, not usage, forcing costly over-provisioning. Operations critical to development velocity – like instant database forking for CI/CD or read replica creation – are hampered by slow snapshot hydration and performance ceilings. Tiger Data identified five core EBS limitations impacting their managed Postgres service (Tiger Cloud):
- Cost Inefficiency: Charging for allocation, not usage, leads to wasted spend.
- Slow Scale-Up: Performance caps (IOPS/TB) and sluggish snapshot hydration delay replica provisioning.
- Scale-Down Bottlenecks: Instance attachment limits hinder cost-efficient hosting of many small databases (e.g., a free tier).
- Limited Elasticity: Infrequent resize operations and inability to downscale.
- Unpredictable Recovery: Detaching failed volumes can take 10-20 minutes during outages.
Agents exacerbate these issues. Their ephemeral, parallel workloads require storage that can instantly branch production data, scale on demand, and vanish without lingering cost – something EBS fundamentally cannot provide. Alternatives like local NVMe (lack durability/elasticity) or Aurora-like page servers (require Postgres forks, database-specific) were deemed insufficient. Tiger Data chose a more foundational approach: rebuilding storage itself.
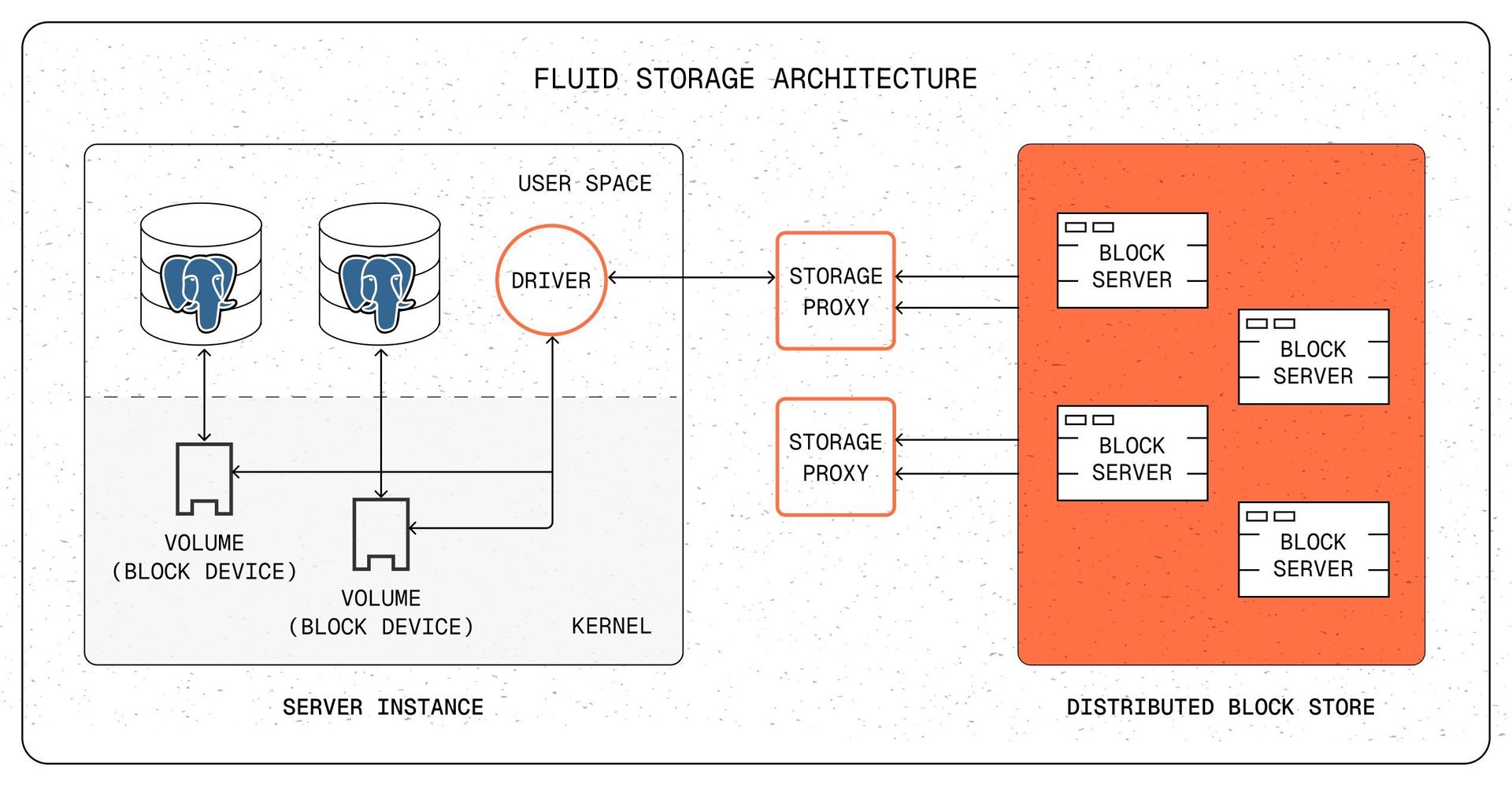
Fluid Storage Architecture: Forkability as a Primitive
Fluid Storage targets six core principles: Fork-first design, true bi-directional elasticity, usage-based billing, predictable performance, Postgres compatibility (via standard block device), and suitability for both developers and platforms. It achieves this through three integrated layers:
- Distributed Block Store (DBS): The foundation. A transactional, sharded key-value store running on local NVMe drives. It handles versioned block writes, synchronous replication across replicas for durability, and horizontal scaling. Sharding distributes I/O and allows capacity adjustments without downtime.
- Storage Proxy: The intelligence layer. Manages virtual volumes, coordinates I/O with DBS, and crucially, tracks volume lineage using efficient metadata (~0.003% overhead). This metadata enables zero-copy snapshots and forks:
- A snapshot increments the parent volume's generation number.
- The child volume starts at this new generation, referencing the parent's prior generation.
- Both share block metadata for previous generations; writes create new blocks tagged with their specific generation.
- Reads traverse generations (newest to oldest) to find the relevant block. Result: Instant forks/snapshots via metadata operations, physical storage only grows as data diverges.
- User-Space Storage Driver: Presents Fluid volumes as standard Linux block devices (ext4/xfs). Uses
io_uringfor performance, supports dynamic resizing, and integrates seamlessly with OS resource controls (cgroups). This ensures full compatibility with unmodified PostgreSQL (and other databases/filesystems) and leverages ongoing Linux kernel improvements.
Life of an I/O Request
- Read: Postgres -> Kernel -> Fluid Driver -> Proxy (checks lineage metadata) -> DBS (retrieves block) -> Back to Postgres.
- Write: Postgres -> Kernel -> Fluid Driver -> Proxy (allocates new block in current gen, updates metadata) -> DBS (writes replicated block) -> Acknowledgment back.
Outcomes: Speed, Efficiency, and New Workflows
Benchmarks on production Fluid Storage clusters demonstrate its capability:
| Operation | Performance |
|---|---|
| Snapshot/Fork | ~500-600ms (metadata op, independent of size) |
| Read Throughput | 110,000+ IOPS, 1.4 GB/s |
| Write Throughput | 40,000-67,000 IOPS, 500-700 MB/s |
| Read Latency | ~1 ms |
| Write Latency | ~5 ms (synchronously replicated) |
Beyond raw speed, Fluid enables transformative workflows:
- CI/CD: Instant, isolated database forks per pull request.
- Safe Migrations: Rehearse schema changes on full-fidelity clones.
- Ephemeral Analytics: Create short-lived production data copies without duplication cost.
- Agentic Workflows: Agents spin up isolated forks, operate in parallel, and discard environments instantly. Snapshots become units of iteration. Compute becomes truly ephemeral.
Reliability and Availability
Fluid Storage ensures resilience through layered approaches:
- Storage Replication: Synchronous block replication within DBS; automatic failure detection and rebalancing.
- Database Durability: PostgreSQL WAL streaming and backups to S3 (independent of Fluid tier).
- Compute Recovery: Fast instance failure recovery (tens of seconds) by reattaching Fluid volumes.
- Region Resilience: Supports single-AZ (low latency/cost) or multi-AZ deployments (stronger isolation, coordinated with Postgres HA).
Fluid Storage is now the default storage for all free-tier databases on Tiger Cloud, available via the Tiger Console, REST API, and Tiger CLI. It operates in public beta for the free tier, with larger workloads onboarded via early-access partnerships ahead of general availability.
A Foundational Shift
Fluid Storage is more than a faster EBS. It redefines block storage primitives for an era defined by autonomous iteration. By delivering zero-copy forks, true elasticity, predictable performance, and Postgres compatibility at the block layer, it removes the friction that hinders developer velocity and agentic potential. Data is no longer a static artifact; with Fluid Storage, it becomes a dynamic substrate that flows with the pace of innovation. Agents demand infrastructure that matches their speed – Fluid Storage delivers that foundation.
Source: Based on the announcement "Fluid Storage: Forkable, Ephemeral, and Durable Infrastructure for the Age of Agents" by Mike Freedman and Samuel Gichohi, Tiger Data Blog (Oct 29, 2025).
Comments
Please log in or register to join the discussion