An experienced developer's journey from Java VM garbage collection to solving bidirectional text editing challenges reveals the timeless value of foundational CS papers. By applying concepts from a 2004 OOPSLA paper, 'A Unified Theory of Garbage Collection', the author optimized ProseMirror and Ohm integration for efficiency in large documents. This story underscores how classic algorithms continue to influence contemporary software development.
Garbage Collection Insights from 2004 Reshape Modern Text Editing: A Deep Dive into Incremental Parsing
In the ever-evolving landscape of software development, it's easy to get lost in the latest frameworks and tools. Yet, as one seasoned developer recently discovered, the most elegant solutions often lie in the foundational principles of computer science. Patrick Dubroy, a veteran in the field with years spent optimizing garbage collection in the J9 Java Virtual Machine, recently tackled a modern challenge in rich text editing by drawing on a 2004 research paper. His experience highlights how timeless concepts like garbage collection can breathe new life into today's parsing and UI frameworks.
From Java VMs to ProseMirror: The Problem at Hand
Dubroy's current project involves using Ohm, a powerful parsing library, to process text documents and render them as rich text in ProseMirror, a robust editor toolkit for the web. The objective was to enable bidirectional updates: modifications in the ProseMirror interface should reflect back to the plain text, and edits to the text should seamlessly update the rich version. This setup demands efficiency, especially for long documents where small changes shouldn't trigger full re-parses.
Ohm's incremental parsing capabilities were a natural fit. It allows reusing portions of previous parse results after minor edits, minimizing computational overhead. Additionally, Ohm supports 'attributes'—memoized visitors that recompute only when affected subtrees change. Leveraging this, Dubroy implemented a persistent data structure for the Abstract Syntax Tree (AST), where new parses share nodes with prior ones, promoting efficiency.
The next step was to generate ProseMirror transactions from these updates. To do so, he needed to identify nodes present in the old document but absent in the new one—essentially, the 'dead' nodes that no longer contribute to the updated view. His initial approach mimicked tracing garbage collection: after each edit, he'd traverse the entire document and track nodes in a set, then compare sets to find differences. While functional, this was inefficient for large texts, as it required visiting every node regardless of the edit's scope, undermining the benefits of incrementality.
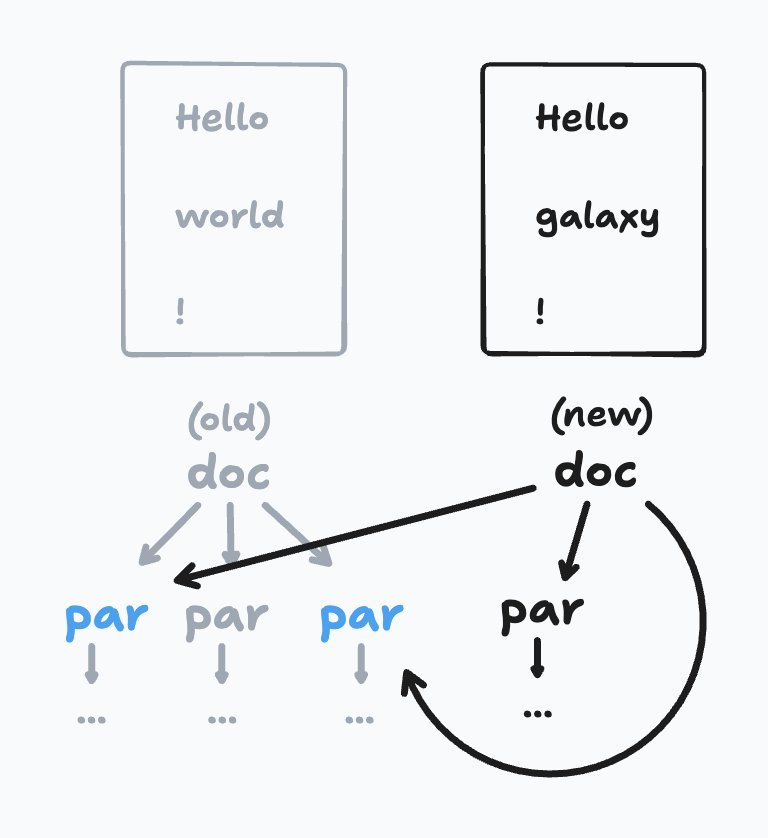
Caption: The pmNodes tree before and after an edit, illustrating shared structure and the need for efficient dead node detection.
Rediscovering Garbage Collection Duality
That's when Dubroy turned to his roots in garbage collection. He recalled "A Unified Theory of Garbage Collection," a seminal 2004 OOPSLA paper co-authored by former colleagues. The paper argues that tracing (which scans live objects) and reference counting (which tracks dead objects via counts) are not opposites but duals—mirrored operations where tracing deals with 'matter' (live data) while reference counting handles 'anti-matter' (dead data). As the paper states:
Tracing and reference counting are uniformly viewed as being fundamentally different approaches to garbage collection that possess very distinct performance properties. We have implemented high-performance collectors of both types, and in the process observed that the more we optimized them, the more similarly they behaved—that they seem to share some deep structure.
This duality was the key insight. Instead of tracing all live nodes, Dubroy flipped the approach: implement reference counting on the nodes. When generating a new document from an edited text, he decrements the reference count starting from the old root (which drops to zero). This recursively propagates decrements, pinpointing exactly the dead nodes without traversing the bulk of unchanged structure.
Implications for Developers Building Rich Editors
This solution not only solved Dubroy's immediate problem but also serves as a compelling case study for developers working with tree-based data structures, whether in editors, compilers, or UI frameworks. In an era where real-time collaboration tools like Google Docs or Notion rely on similar incremental updates, understanding these low-level optimizations can mean the difference between smooth performance and frustrating lags.
For those venturing into ProseMirror or Ohm, this approach exemplifies how to maintain persistence in ASTs while efficiently managing updates. It's a reminder that while modern libraries abstract away much complexity, peeking under the hood—especially at GC principles—can unlock performant implementations. Dubroy's story bridges the gap between systems programming and web development, showing that the algorithms of yesteryear remain vital tools in our arsenal.
As we push the boundaries of interactive applications, such cross-pollination of ideas will undoubtedly fuel further innovations, ensuring that even the largest documents edit as fluidly as a single keystroke.
Comments
Please log in or register to join the discussion