OpenAI’s latest GPT‑5.1 update slashes latency and token usage for developers, thanks to adaptive reasoning, a no‑reasoning mode, and extended prompt caching. These changes not only cut API bills but also make AI agents more agentic inside IDEs, reshaping how apps embed intelligence.
GPT‑5.1: The Speed‑and‑Cost Game Changer for Embedded AI
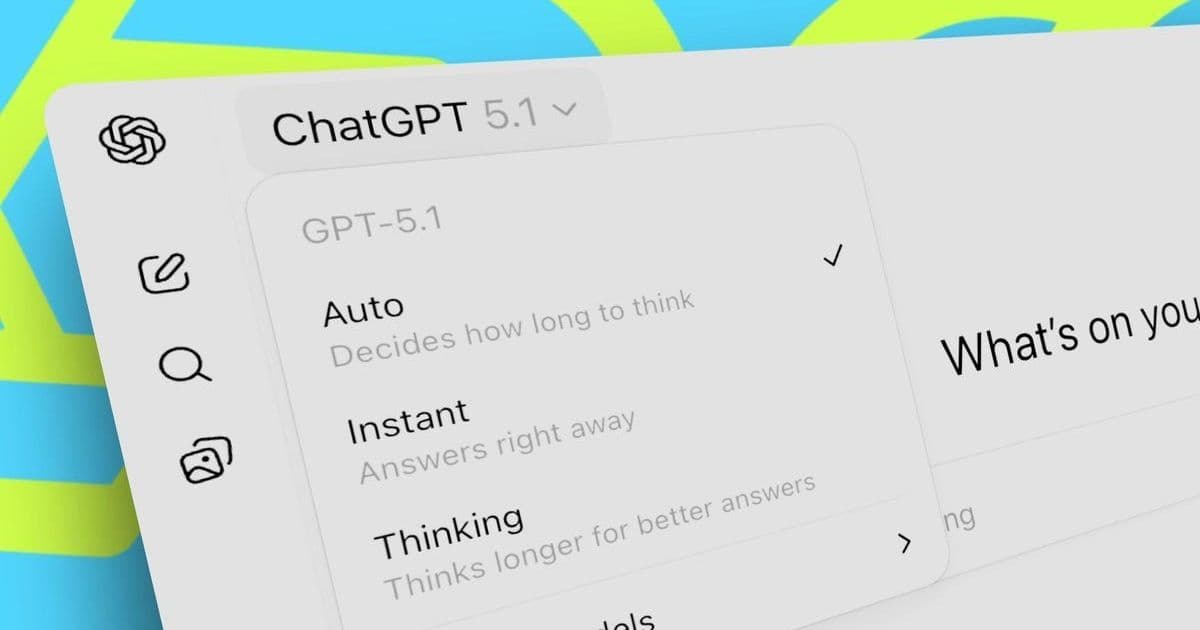
OpenAI’s newest release, GPT‑5.1, arrives with a suite of optimisations that could dramatically alter the economics of AI‑powered software. According to a detailed ZDNET feature by David Gewirtz (13 Nov 2025), the model now adapts its reasoning depth to the complexity of a prompt, offers a no‑reasoning mode that skips chain‑of‑thought deliberation, and caches prompts for up to 24 hours. Together, these tweaks cut latency, reduce token consumption, and lower the cost of every API call – a boon for developers who embed AI directly into their products.
From “One‑Size‑Fits‑All” to Context‑Aware Reasoning
GPT‑5 was already a leap forward for code‑generation, but its monolithic reasoning engine meant that even trivial look‑ups could take minutes and cost a lot of tokens. GPT‑5.1 introduces adaptive reasoning: the model first classifies a prompt as simple or complex and then allocates the appropriate amount of cognitive effort. A quick WP‑CLI question now returns in milliseconds, while a multi‑file code audit still receives the full depth of analysis.
“It writes like you, codes like you, effortlessly follows complex instructions, and excels in front‑end tasks,” says Denis Shiryaev, head of AI DevTools at JetBrains, reflecting on the model’s newfound autonomy.
The “No‑Reasoning” Mode (or “Don’t Overthink” Mode)
Deep, chain‑of‑thought reasoning is valuable for hard problems, but it can also cause analysis paralysis for routine tasks. GPT‑5.1’s no‑reasoning mode disables that step‑by‑step thinking while preserving context understanding and code quality. The result is a snappier, more conversational response that feels like a pair‑programming partner who knows when to jump straight to the answer.
Extended Prompt Caching: 24‑Hour Reuse
Token costs are driven largely by the initial parsing of a prompt. Re‑asking the same prompt – a common pattern in customer‑support bots or IDE assistants – previously incurred the full token cost each time. GPT‑5.1 now compiles a prompt once and re‑uses that compiled representation for up to 24 hours, delivering substantial speed gains and bill reductions for high‑frequency applications.
Design‑In Implications for the Ecosystem
The cumulative effect of these optimisations strengthens OpenAI’s business case for design‑in – the practice of embedding a component into a product at the design stage. As ZDNET notes, the cost of API calls directly impacts the price of consumer apps. With GPT‑5.1’s lower cost and higher performance, large‑scale platforms such as CapCut or Temu could integrate AI more aggressively without eroding margins.
New Tooling and Agentic Coding
Beyond performance, GPT‑5.1 adds a apply_patch tool that streamlines multi‑step code modifications and a more capable shell tool for command‑line interactions. These extensions make the model a more effective agent inside modern IDEs, a trend that could accelerate the adoption of AI‑powered development assistants.
What It Means for Developers
- Faster iteration: Adaptive reasoning cuts wait times for routine queries.
- Lower bills: Prompt caching and token‑efficient modes reduce API spend.
- Better integration: New tools and agentic behaviour fit naturally into existing workflows.
If you’re already using GPT‑5, the jump to GPT‑5.1 should feel like a new engine under the hood – more responsive, cheaper, and more aligned with your coding style.
Source: ZDNET, "Developers gain major speed and cost savings with new GPT‑5.1 update," 13 Nov 2025.
Comments
Please log in or register to join the discussion