
When AMD mistakenly pushed the FSR 4 source code to its public repo, it exposed more than an unreleased build—it revealed a sharp, disciplined hybrid of hand-tuned graphics engineering and tiny neural networks. This is how AMD is closing the gap with DLSS without surrendering to bloated AI, and what it means for engine developers and GPU vendors racing to own the frame.
Inside AMD’s Accidental FSR 4 Leak: How a 100K-Parameter Network Rewrites Real-Time Upscaling

In August, AMD did something Nvidia never would: it accidentally lifted the veil.
For a brief window, the source code for FidelityFX Super Resolution 4 (FSR 4)—the company’s next-gen temporal upscaler—appeared on the official FidelityFX GitHub. Buried inside was not just an implementation for older GPUs that the community quickly weaponized into drop-in DLLs, but a complete blueprint for how AMD intends to fight DLSS on its own turf: deep learning–assisted reconstruction.
What the leak revealed is not a brute-force neural replacement of the rendering pipeline. FSR 4 is far more interesting than that.
It’s a case study in disciplined AI: a compact kernel-prediction network welded onto a battle-tested TAA-style pipeline, aggressively fused, motion-vector aware, and tailored to fit inside a brutal <1 ms budget. For engine developers and graphics programmers, FSR 4 is a signal: the future of real-time enhancement is neither hand-tuned heuristics nor unbounded neural opulence—it’s the synthesis.
Source attribution: This analysis is based primarily on the public breakdown and code reading by Wrong On The Internet ("Understanding FSR 4" on Substack, Nov 10, 2025), combined with broader industry context.
From Open Heuristics to Closed Neural Hybrids
Historically, AMD’s FSR story has been the foil to Nvidia’s DLSS:
- FSR 1/2: Heuristic-heavy, open, cross-vendor, and relatively lightweight—but visibly behind DLSS in detail retention and temporal stability.
- DLSS: Heavily data-driven, vendor-locked, leaning on Nvidia’s deep learning stack to deliver sharper, more temporally consistent results.
FSR 4 was marketed as AMD’s deep learning answer, but unlike FSR 2, it shipped closed-source and RDNA 4–restricted, instantly raising suspicions: how proprietary and how “AI” was this really?
Then came the leak.
The code shows that FSR 4 is not a monolithic image-to-image super-res network. Instead, it is an evolution of FSR 2:
- The traditional temporal accumulation and motion vector machinery stay.
- Many hand-tuned edge, disocclusion, and particle heuristics are ripped out.
- In their place: a tiny neural network that predicts how to filter, blend, and remember.
It’s not end-to-end learning; it’s targeted learning—precisely where FSR 2’s heuristics were most fragile.
Why Real-Time Super Resolution Is Brutal
If you’ve read offline super-resolution papers, you’re used to budgets like “seconds per frame” to push out a single HD or 4K image.
In shipped games, those numbers are absurd.
An upscaler like FSR 4 must:
- Run in the leftover time at the tail of the frame.
- Handle 1080p → 4K or similar jumps.
- Survive a 16.6 ms (or lower) frame budget, often with <1 ms allocated to upscaling.
This constraint makes most academic architectures unusable as-is. Any practical solution must fuse expert prior knowledge (motion vectors, depth, temporal history) with a ruthlessly lean learned component.
FSR 4 is that constraint, codified.
Step 1: Temporal DNA, Inherited from FSR 2
To understand FSR 4, you start with FSR 2—because AMD did.
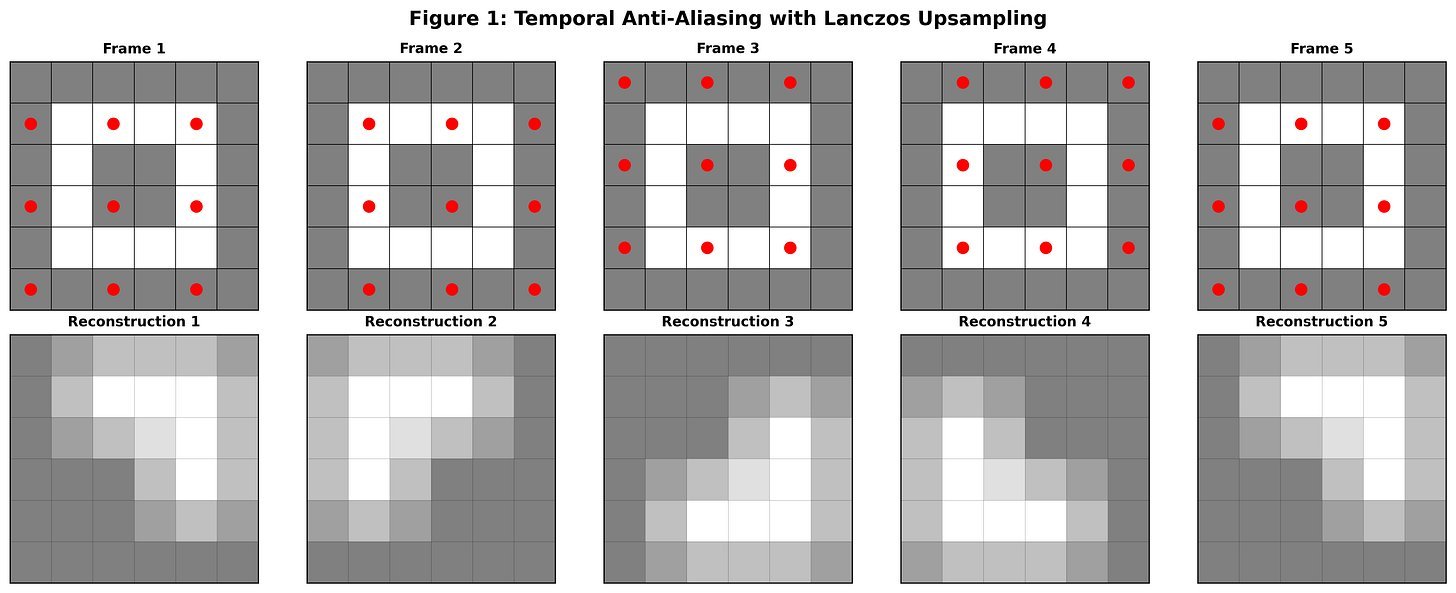
FSR 2 lives squarely in the Temporal Anti-Aliasing (TAA) family:
- Each frame renders at a lower resolution.
- Sample positions jitter over time (e.g., using a Halton sequence).
- History is accumulated across frames to reconstruct higher-frequency detail.
On static scenes, this works beautifully: multiple noisy, undersampled frames fuse into a richer image. But the real world isn’t static, and that’s where things bend.
The pipeline leans on:
- Motion vectors from the engine to reproject previous frames.
- Depth to disambiguate overlapping geometry.
- Heuristics to decide when to trust history vs. current frame (e.g., around edges, transparencies, particles, and disocclusions).
Those heuristics are the weak link.
When they misfire, you see:
- Smearing around fast motion.
- Shimmering edges and temporal instability.
- Ghosting when history is over-trusted.
DLSS pulled ahead by learning these decisions from data instead of encoding them manually. FSR 4 follows that trajectory—but with a twist.
Step 2: FSR 4’s Core Idea – Predict the Filter, Not the Pixels
FSR 4 is architected in three conceptual stages:
- Feature engineering (motion-aware reprojection, depth, and recurrent state handling).
- A small neural network that runs at output resolution.
- A filtering/upscaling stage driven by the network’s outputs.
The critical design decision: FSR 4 is a Kernel Prediction Network (KPN).
Instead of directly hallucinating high-resolution RGB pixels, the network outputs parameters for how to filter and blend existing data. For each output pixel, the network predicts:
- An oriented Gaussian kernel (height, width, orientation/tilt).
- A temporal blending factor controlling how much history to trust.
- Four recurrent state values that persist across frames.
This is a subtle but powerful choice:
- It constrains the model to operate within a physically and perceptually meaningful space.
- It lets the engine retain control of raw content (rasterized color, motion vectors, depth), with the network as an advisor, not an autocrat.
- It makes the behavior debuggable in ways fully learned pipelines aren’t.
The oriented Gaussian is particularly important. A naïve, symmetric kernel will happily smear thin geometry—cables, fences, specular highlights—into oblivion. An oriented Gaussian can align along edges, preserving detail with far less ringing and blur.
The temporal factor solves the age-old TAA problem:
- Stable, trackable surfaces: crank up history usage.
- Rapid change, particles, disocclusions: fall back to spatial reconstruction and ignore misleading history.
Crucially, the network isn’t guessing in the dark. It’s fed a curated, low-bandwidth feature set.
Step 3: The Network That Fits in a Millisecond
By modern AI standards, the FSR 4 network is comically small. By real-time graphics standards, it’s elegant.
Per output pixel, the inputs are:
- The four recurrent values from the previous frame (already warped to match motion; more on that next).
- A grayscale version of the current frame (naively upscaled to target resolution).
- A grayscale version of the previous output frame.
- A scalar measuring local colorfulness.
Outputs (per pixel):
- 3 values → oriented Gaussian kernel parameters.
- 1 value → temporal blending factor.
- 4 values → next-frame recurrent state.
Architecturally:
- Roughly 39 layers in a U-Net-like encoder–decoder.
- 3×3 convolutions, aggressive strides/downsampling to keep it light.
- Around 100K parameters—10x smaller than many early “mobile-grade” CNNs.
- Implemented via ONNX → HLSL using AMD’s ML2Code toolchain.
- Manually kernel-fused by AMD engineers so that preprocessing and parts of the filter logic execute inside early and mid-pipeline ML kernels.
This is the antithesis of the “just throw a giant transformer at it” mindset.
For developers, it’s a reminder: on the GPU, every microsecond is political. This network exists because it respects the frame.
The Clever Bit: Reprojecting Recurrent Memory
The most intriguing innovation revealed in the leaked code isn’t the U-Net. It’s what AMD does with recurrence.
Temporal neural networks typically learn how to track motion implicitly: they see successive frames and infer how features move. But in games, we already know how things move—engines provide motion vectors.
FSR 4 exploits that “free prior” directly:
- Alongside reprojecting color and depth from previous frames, FSR 4 also reprojects the four per-pixel recurrent state values using the motion vectors.
Effectively, AMD is saying to the network:
“Don’t waste capacity learning motion tracking. We’ll move your memory for you.”
This does three important things:
- Compresses the model: less capacity wasted on learning motion dynamics.
- Improves temporal stability: recurrent features follow objects instead of smearing in screen space.
- Tightens integration with the engine: the network becomes a temporal refinement layer on top of explicit motion, not a blind video model.
To date, this approach—motion-vector-guided reprojection of recurrent neural features in a shipping real-time graphics product—has been rarely, if ever, documented in public pipelines. It’s the kind of hybrid systems thinking that feels obvious in hindsight and yet is conspicuously missing from most academic super-res baselines.
For graphics and ML engineers, it’s a pattern worth stealing.
Why FSR 4 Still Breaks (and Why That’s Not a Failure)
Even with this architecture, FSR 4 inherits a key vulnerability shared by DLSS: dependence on motion vectors and engine metadata.
FSR 4 struggles when:
- Particle systems, volumetrics, UI, or in-world screens don’t expose reliable motion.
- Shaders break the expected relationship between geometry, depth, and perceived motion.
When motion vectors lie—or don’t exist—the network must fall back to spatial-only reconstruction and conservative temporal blending. The artifacts are familiar: blur, ghosting, or instability.
The important nuance for practitioners:
- These failures are not evidence that “AI upscaling doesn’t work.”
- They are evidence that the boundary between engine semantics and neural reconstruction is now the primary design surface.
For engine developers, the direction is clear: better motion vectors, better separation of transparent/animated/UFx layers, and explicit annotation of non-reconstructable content will directly improve upscaler quality. The smarter your metadata, the smarter FSR 4 (and DLSS, and XeSS) can be.
Strategic Signal: A New Contract Between Engines and AI
Beyond the hype of an accidental leak, FSR 4’s design telegraphs three larger industry trends.
- Hybrid > End-to-End
The bitter lesson says general methods plus compute beat hand-engineering. FSR 4 quietly amends it for real-time graphics:
General methods plus domain priors plus ruthless efficiency beat both naïve heuristics and unconstrained deep nets.
FSR 4 encodes:
- Engine-provided motion and depth as hard structure.
- A tiny learned core handling the ambiguities humans were bad at hand-tuning.
This is likely the shape of many future real-time ML systems: expert priors for structure, learned modules for judgment.
- Tooling as Differentiator
AMD’s ML2Code pipeline, manual kernel fusion, and architecture tuned for HLSL are not side notes. They’re competitive levers.
If upscalers, denoisers, and frame generators are all small, specialized networks glued to traditional pipelines, then vendors win or lose on:
- How efficiently they can compile and fuse ML into shader code.
- How well they expose this functionality to engines without locking platforms.
- Openness vs. Lock-In Is Back on the Table
Earlier FSR versions derived real momentum from being open and cross-vendor. FSR 4, as shipped, is closed and RDNA 4–tied—until the leak exposed an INT8 variant for older GPUs.
For studios and platform architects, that tension matters:
- Proprietary, opaque tech can deliver short-term wins but raises long-term risk and integration friction.
- Transparent designs, even if not fully open-source, help engine teams reason about behavior, debug artifacts, and plan for cross-hardware consistency.
Ironically, the leak gave the community what AMD’s marketing did not: a credible technical story.
Where This Leaves Developers—and Why It’s Worth Paying Attention

If you build engines, renderers, or graphics tooling, FSR 4’s leaked internals are more than gossip. They’re a roadmap.
Practical takeaways:
- Treat motion vectors as first-class API, not an afterthought. Your upscaler is only as good as your motion semantics.
- Expect more vendor tech to reuse this pattern: tiny KPNs, explicit temporal state, and motion-vector-guided recurrent features.
- Don’t wait for monolithic “AI renderers” to replace your pipeline. The near-term gains are in splicing specialized networks into well-understood stages.
And if you’re a vendor or tools maker, the message is sharper:
- The market is watching how you balance proprietary advantage with ecosystem trust.
- The FSR 4 leak briefly showed how powerful that transparency can be—both in community adoption and in elevating the technical conversation beyond buzzwords.
Real-time graphics is entering an era where AI is neither the magic wand nor the enemy of craftsmanship. In FSR 4, exposed by a single errant push, we see something more mature: a careful collaboration between decades of rendering wisdom and just enough neural computation to matter.
That, more than the leak itself, is the story worth remembering.
Comments
Please log in or register to join the discussion