As TiKV clusters pushed RocksDB into multi-terabyte, hundreds-of-thousands-of-SST territory, a single global mutex quietly became a 100 ms tail-latency tax. PingCAP’s engineers dissected RocksDB’s LogAndApply pipeline, peeled CPU-heavy work out of the lock, and turned a pathological bottleneck into a 100x latency win. Here’s how—and why this pattern should reshape how you think about concurrency in storage engines.
 )
)
Source: “How we optimize RocksDB in TiKV (Part 1) — The Battle Against the DB Mutex” by siddontang (Medium)
When TiKV launched nine years ago, betting on RocksDB felt obvious. A hardened LSM-tree engine, tuned in the wild at Meta and beyond, with a flexible architecture and strong performance profile—it was exactly the kind of substrate you’d want under a distributed transactional key-value store.
Then the workloads grew up.
Four terabytes here. Hundreds of thousands of SSTs there. Write-heavy ingestion pipelines. Skyrocketing concurrency. In that world, a subtle internal design choice in RocksDB—the notorious global DB mutex—stopped being an implementation detail and started dictating system behavior. At scale, it wasn’t just a lock. It was the lock.
This is the story of how the TiKV team went after that mutex, surgically moved work out of its critical path, and cut snapshot tail latency from ~100 ms down to sub-millisecond. The techniques are highly specific, but the lesson is not: if you’re building high-concurrency systems on battle-tested components, you still owe it a forensic look at every shared lock.
When a Proven Engine Becomes the Bottleneck
The tipping point came from a seemingly unremarkable production workload: continuous bulk ingestion into a TiKV cluster backed by RocksDB.
- Data size: ~4 TB
- SST files: 290,000+
- Symptom: p99 snapshot latency north of 100 ms. For a modern distributed KV store, that’s not a “noise” problem—it’s a systemic one.
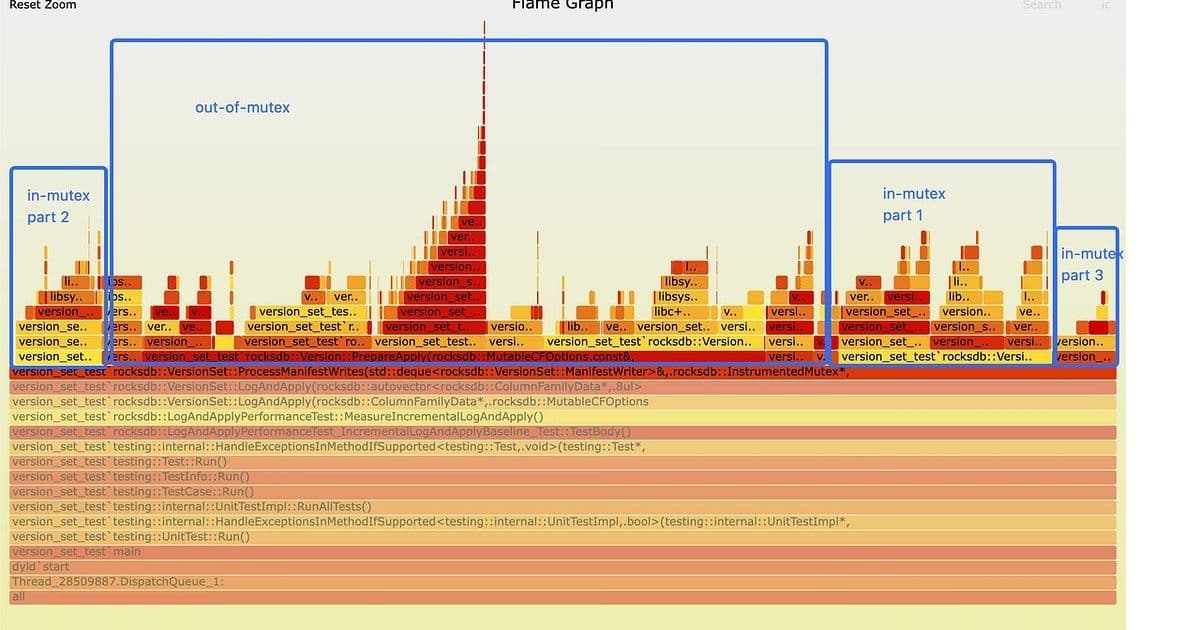
A local reproduction showed something more damning than slow disks or pathological compactions: severe contention on RocksDB’s global DB mutex, especially during the LogAndApply step that coordinates version edits.
This wasn’t a misconfiguration. It was architecture.
The Global DB Mutex: One Lock to Rule Them All
RocksDB exposes a clean API to its users, but internally it runs a busy city of shared structures, all guarded by a single lock:
- Version management: managing and switching between versions of the LSM-tree.
- MemTable lifecycle: switching and flushing in-memory structures.
- Column family operations: create, modify, drop.
- Compaction scheduling and metadata updates.
- Snapshot list maintenance.
- Write path coordination (WAL + write batches).
Different subsystems, one mutex. On a single-node, modestly sized deployment, this is simple and safe. On a distributed database node swimming in SST files and background work, it’s a pressure cooker.
The combustion point is LogAndApply.
Why LogAndApply Hurts at Scale
Every flush, every compaction, every ingestion that rewires SST file layouts goes through LogAndApply—a pipeline that updates RocksDB’s version set.
At a high level, LogAndApply is responsible for:
- Preparing version edits.
- Applying changes and generating the new LSM-tree file set.
- Maintaining version lists and reference counts.
- Ensuring consistency across snapshot and compaction views.
The expensive detail: its cost scales with the number of SST files.
In a small deployment, that’s fine. In a 4 TB instance with hundreds of thousands of SSTs, any operation that does a global merge or metadata walk under a single mutex becomes catastrophic. And that’s exactly what was happening: CPU-heavy work executed while holding the global DB mutex, serializing unrelated operations and exploding tail latency.
Dissecting the Critical Section
The TiKV team dissected LogAndApply into its lock-sensitive pieces:
SaveTo (Part 1):
- Merges version edits with the base LSM-tree file set.
- Performs merge-sort-like logic over large file metadata structures.
- This was the heavy hitter—done while holding the global mutex.
Unref ~Version (Part 2):
- Unlinks the old version from the global version list (must be under the mutex).
- But many of its internals, especially destroying the storage info, don’t inherently require the lock.
AppendVersion (Part 3):
- Appends the new version to the linked list, updates shared state.
- Intrinsically lock-bound—this is the part that must be serialized.
The core optimization question became: how much of this work can we legally eject from under the mutex without breaking consistency?
The Key Insight: Decouple What Must Be Locked from What’s Just Expensive
The breakthrough was recognizing that the heaviest structure in play—VersionStorageInfo—did not need to live and die under the mutex.
Originally, VersionStorageInfo behaved effectively as part of the Version object, whose lifecycle was tightly bound to the global version list and its lock. That design accidentally forced a large amount of CPU and memory work into the locked region.
TiKV’s engineers flipped this around:
- Heap-allocate
VersionStorageInfoinstead of embedding it directly. - Move the bulk of
SaveTo(the expensive merge logic over SST metadata) out of the mutex. - Use RocksDB’s environment scheduler to perform background cleanup of
VersionStorageInfo.
The lock now protects what it’s actually good at:
- Structural changes: linking/unlinking versions; ensuring consistent views.
- Brief, surgical updates to shared state.
The heavy, mechanical work—merging large metadata sets, managing storage info lifecycles—runs concurrently in the background, no longer serialized behind a global gate.
This is textbook critical-section engineering, but applied inside a widely trusted storage engine where many users simply assume the internals are “fast enough.”
The Payoff: From 100 ms to Sub-millisecond Tail Latency
Once these changes landed, the impact in TiKV’s snapshot performance was dramatic:
- Before: p999 latency for local async snapshots ≈ 100 ms.
- After: p999 slashed to under 1 ms.
That’s not tuning noise; that’s a two-orders-of-magnitude behavioral shift, purely from making less work run while the global DB mutex is held.
It also shifted an important mental model for the team: when your system depends on an embedded engine, you can’t treat its synchronization strategy as a black box. At real-world scale, locks are part of your API surface, whether documented or not.
Why This Matters Beyond TiKV
If you’re running or building:
- Cloud-native databases or storage engines,
- High-ingest analytics systems,
- Multi-tenant services sharing RocksDB or similar engines,
this optimization is more than a niche war story.
Key takeaways for practitioners:
- “Battle-tested” doesn’t mean “scale-proof”: Proven libraries often encode assumptions (like a single global mutex) that quietly fail at today’s concurrency and dataset sizes.
- Always profile inside dependencies: Flamegraphs and lock contention analysis across the storage stack are mandatory at terabyte scale, not optional.
- Critical sections are a design surface: Re-structuring data ownership (like splitting
VersionStorageInfofromVersion) can unlock concurrency without sacrificing correctness. - Think in terms of semantic locking: Guard invariants, not computations. If a task doesn’t change shared truth, it probably doesn’t belong under your heaviest lock.
Notably, some of these improvements have made their way upstream into RocksDB itself; others remain TiKV-specific but battle-hardened in large production clusters. Either way, the trickle-up effect is clear: real-world distributed systems pressure-test assumptions that core infrastructure must eventually adapt to.
From Lock Triage to Storage Reimagination
This mutex surgery is just one chapter in TiKV’s long-running optimization saga. Next steps in their journey include:
- Splitting the write mutex from the DB mutex to isolate hot paths.
- Rate limiting based on write amplification rather than naive throughput metrics.
- Instrumenting internals with precise performance flags to expose real bottlenecks.
And then there’s the more radical turn: TiDB X, a next-generation engine that discards RocksDB entirely in favor of an object-storage-native design—optimized from first principles for elasticity, cost, and cloud environments rather than retrofitted onto local disks.
Seen in that light, this global mutex story reads like a transitional artifact: the moment when a team pushed a legacy-optimized design to its edge, learned exactly where it cracked, and then used those scars to inform a new architecture.
For developers and architects, that’s the real lesson: don’t just patch your locks. Let your worst contention bugs tell you what your next system should look like.
Comments
Please log in or register to join the discussion