Ryan Fleury argues that traditional approaches to parallelism, like job systems and parallel loops, add unnecessary complexity and obscure debugging. By flipping the script—writing code multi-core by default, inspired by GPU shaders—developers can unlock simpler, more efficient performance scaling. This paradigm shift leverages concepts like lane indexing and synchronization to make parallelism intuitive and universally applicable.
For decades, programmers have treated multi-core execution as an optimization—a complex layer bolted onto fundamentally single-threaded code. But as core counts soar into the dozens, this mindset leaves massive performance untapped. In a provocative article, developer Ryan Fleury challenges this orthodoxy, advocating for a radical inversion: multi-core by default. Instead of scaling up from single-threaded logic, we should design code assuming concurrent execution from the start, drawing inspiration from an unlikely source—GPU shaders.
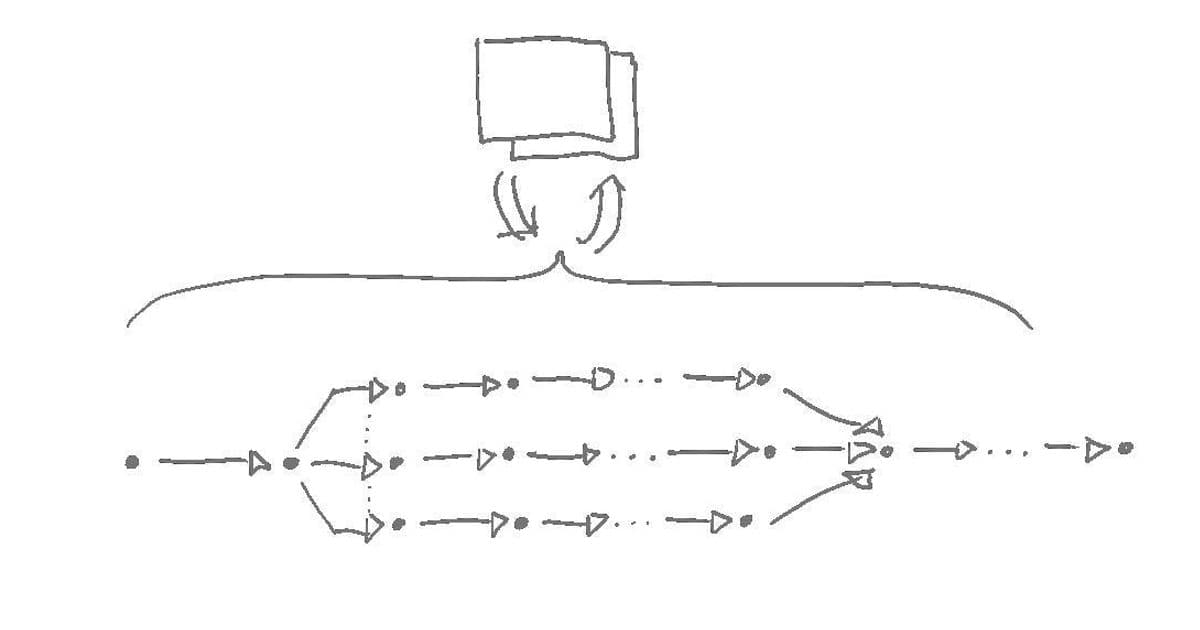
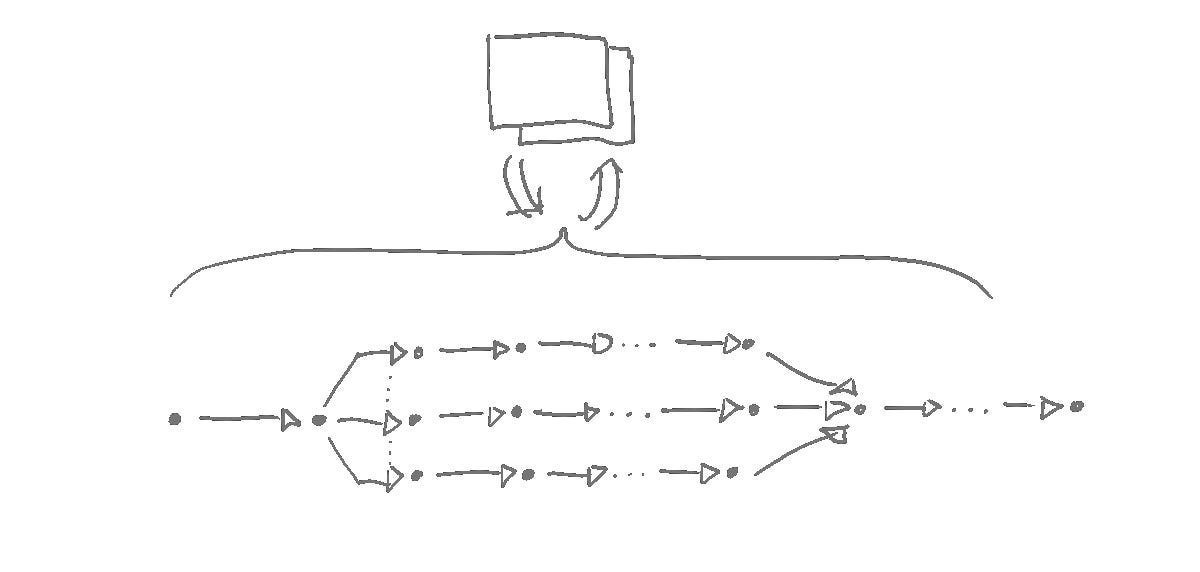 Main article image illustrating the shift from serial to parallel execution paradigms. (Source: Ryan Fleury)
Main article image illustrating the shift from serial to parallel execution paradigms. (Source: Ryan Fleury)
The Burden of Bolted-On Parallelism
Traditional parallelism tools like parallel for loops and job systems promise easy speedups but introduce hidden costs. As Fleury notes, these approaches scatter control flow across threads and time, fracturing debugging contexts and demanding intricate setup for every parallel task. Consider summing an array:
// Single-core sum
S64 sum = 0;
for(S64 idx = 0; idx < values_count; idx += 1) {
sum += values[idx];
}
Parallelizing this via a job system explodes complexity:
// Job system setup (simplified)
SumParams params[NUMBER_OF_CORES];
Thread threads[NUMBER_OF_CORES];
for(S64 core_idx = 0; core_idx < NUMBER_OF_CORES; core_idx += 1) {
// Configure per-core ranges, launch threads...
}
// Join threads, combine results...
This isn’t just verbose—it decouples the logic from its execution context, turning simple loops into fragmented, hard-to-trace workflows. Worse, job systems often evolve into dependency-heavy behemoths, where tasks spawn unpredictably, complicating resource lifetimes and state management.
The GPU Inspiration: Parallelism as First-Class Citizen
Fleury’s epiphany came from GPU programming, where shaders execute across thousands of cores by default. Each shader instance (e.g., per pixel or vertex) operates independently, with parallelism handled implicitly. CPU code, he realized, can adopt this model:
void EntryPoint(void *params) {
S64 thread_idx = (S64)params;
// All threads run this code concurrently
Rng1U64 range = LaneRange(values_count); // Distribute work uniformly
S64 thread_sum = 0;
for (U64 idx = range.min; idx < range.max; idx += 1) {
thread_sum += values[idx];
}
// Synchronize and combine results
AtomicAddEval64(&global_sum, thread_sum);
LaneSync();
}
Here, LaneRange() automatically partitions work across cores, while LaneSync() handles barriers. This mirrors GPU simplicity: threads ("lanes") execute the same code path with minimal boilerplate.
Key Advantages Over Traditional Models
- Debugging Clarity: With homogeneous lanes and preserved call stacks, inspecting one thread reveals the state of all. No more tracing job dependencies across disconnected contexts.
- Effortless Scaling: Code written this way runs on 1 core or 64 without structural changes. Set
LaneCount()to 1 for trivial tasks—no refactoring needed. - Resource Simplicity: Data lifetimes align with thread execution, avoiding the allocator gymnastics of job systems. Shared state uses atomic ops or broadcasts via
LaneSyncU64().
Handling Real-World Complexity
Non-uniform workloads? Fleury outlines strategies:
- Dynamic Task Stealing: For variable-cost tasks, use atomic counters to let lanes grab work on-demand:
S64 task_idx = AtomicIncEval64(&task_counter) - 1; if (task_idx < task_count) { /* Execute task */ } - Algorithm Redesign: When tasks are few but heavy, swap algorithms. Fleury replaced a parallelized comparison sort with a radix sort, distributing passes uniformly across lanes.
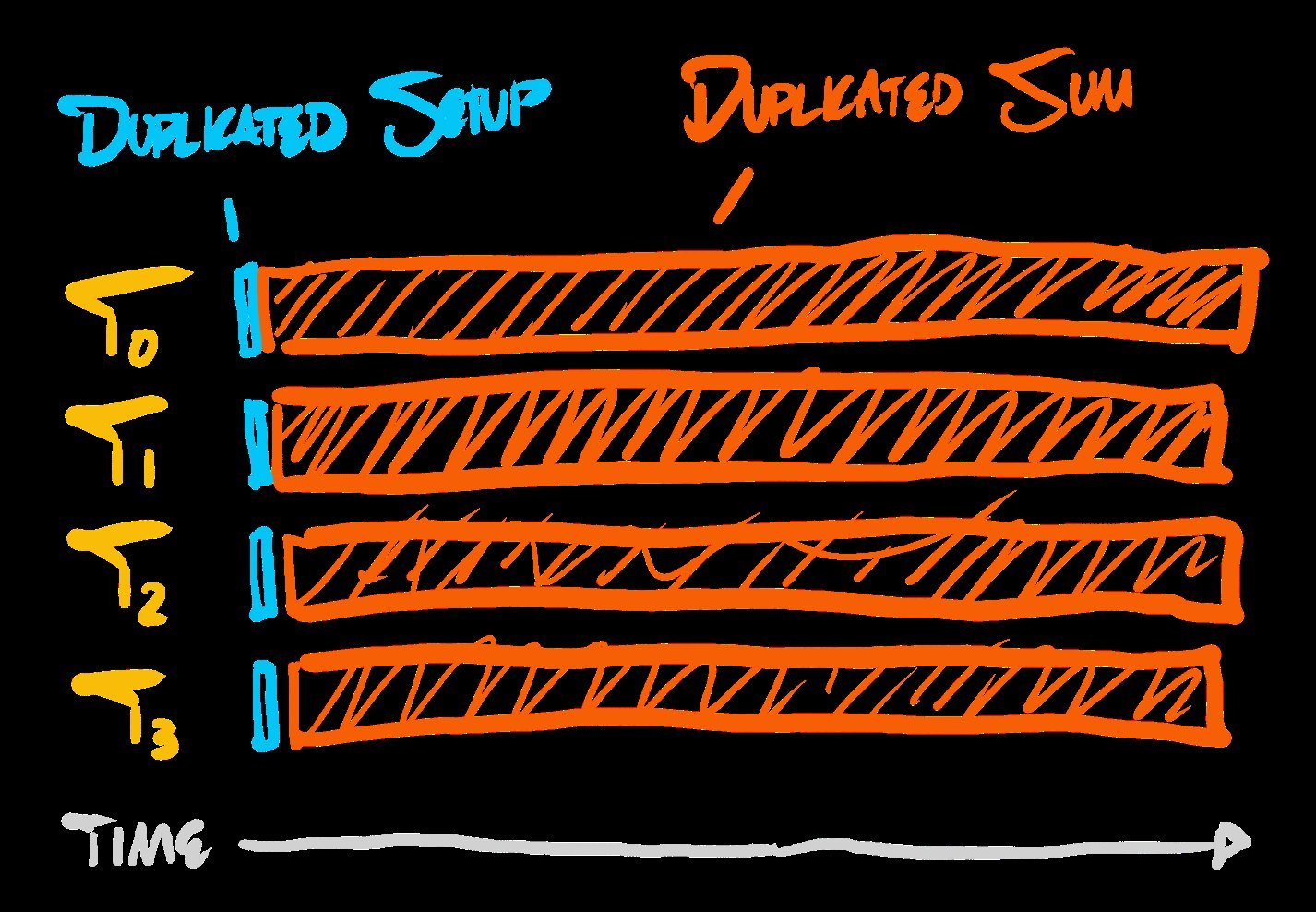 Work distribution profile showing uniform core utilization with radix sort. (Source: Ryan Fleury)
Work distribution profile showing uniform core utilization with radix sort. (Source: Ryan Fleury)
Implementing the Paradigm
Fleury’s base layer provides three pillars:
LaneIdx()/LaneCount(): Identify position and group size.LaneSync(): Barrier synchronization.LaneRange(count): Uniformly partitions workloads.LaneSyncU64(&var, src_lane): Broadcasts data across lanes without global statics.
This toolkit turns file reading—often a serial bottleneck—into parallel I/O:
if (LaneIdx() == 0) values = Allocate(...); // Allocate on lane 0
LaneSyncU64(&values, 0); // Broadcast pointer
Rng1U64 byte_range = ... // Compute lane's byte range
FileRead(file, byte_range, values + range.min); // Parallel read
Beyond Theory: A New Default
Fleury’s approach isn’t just for niche optimizations. By treating multi-core as the baseline, programmers eliminate the cognitive tax of "going parallel," making concurrency a natural part of the development flow. As he concludes, "Code becomes strictly more flexible—at the low level—than its single-core equivalent." For an industry drowning in underutilized hardware, this isn’t just elegant—it’s essential.
Source: Adapted from Ryan Fleury’s original article, Multi-Core By Default.
Comments
Please log in or register to join the discussion