
Hugging Face introduces the Retrieval Embedding Benchmark (RTEB), a hybrid evaluation framework designed to solve the generalization gap plaguing existing benchmarks. By combining open datasets for transparency with private datasets to prevent overfitting, RTEB delivers reliable accuracy measurements for real-world applications like RAG and enterprise search. This community-driven standard covers 20 languages and critical domains including legal, healthcare, and finance.
The performance of retrieval-augmented generation (RAG), AI agents, and recommendation systems hinges on one critical component: the accuracy of embedding models in finding relevant information. Yet developers face a persistent challenge—how do you truly measure a model's ability to generalize to unseen data? Existing benchmarks often fall short, creating a dangerous gap between reported scores and real-world performance.
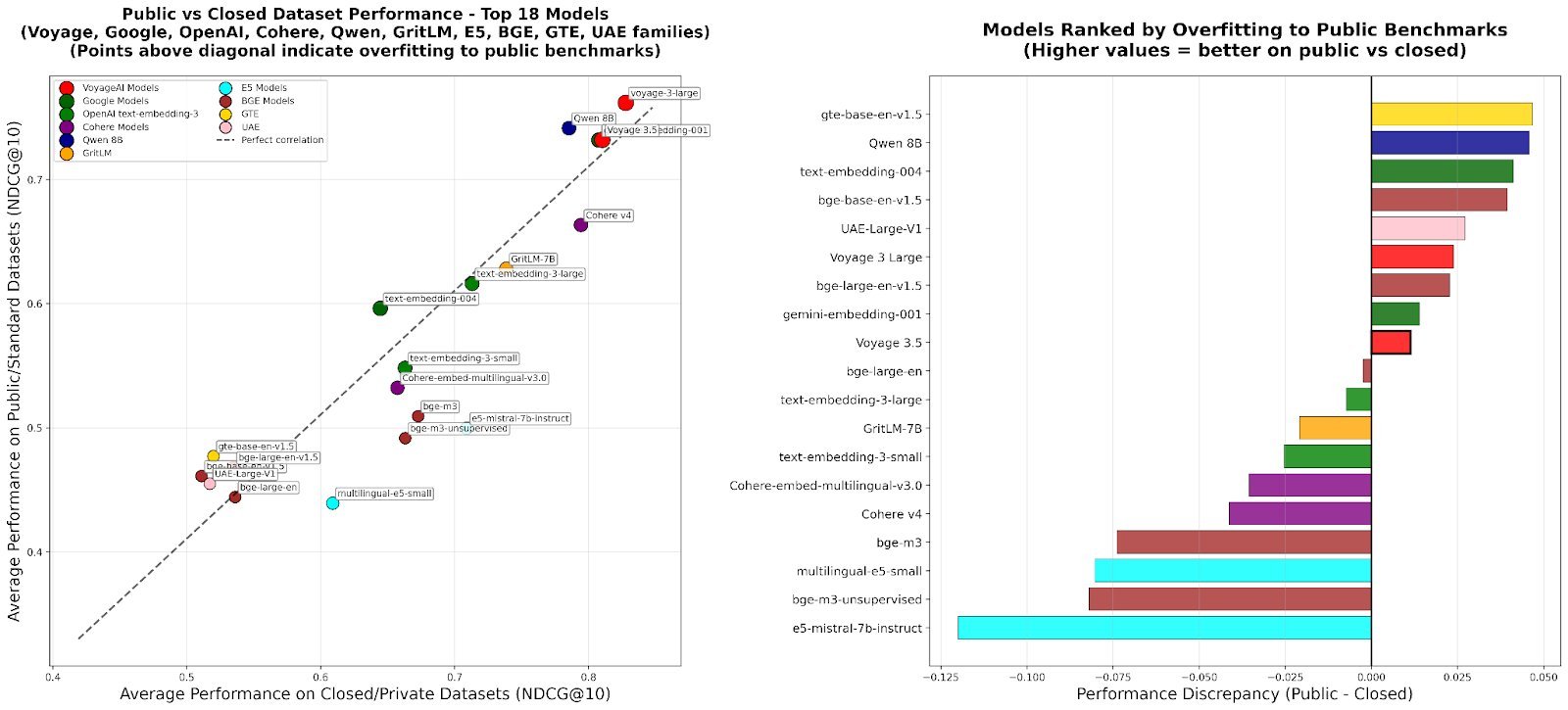 Performance Discrepancy Between Public and Closed Datasets highlights the core problem RTEB solves.
Performance Discrepancy Between Public and Closed Datasets highlights the core problem RTEB solves.
Why Current Benchmarks Fail
Traditional evaluation suffers from two critical flaws:
- The Generalization Gap: Models are often trained or fine-tuned on data overlapping with public benchmarks, leading to inflated scores that don't reflect true capability. As illustrated by Chung et al. (2025), models can excel on known benchmarks while faltering on novel tasks.
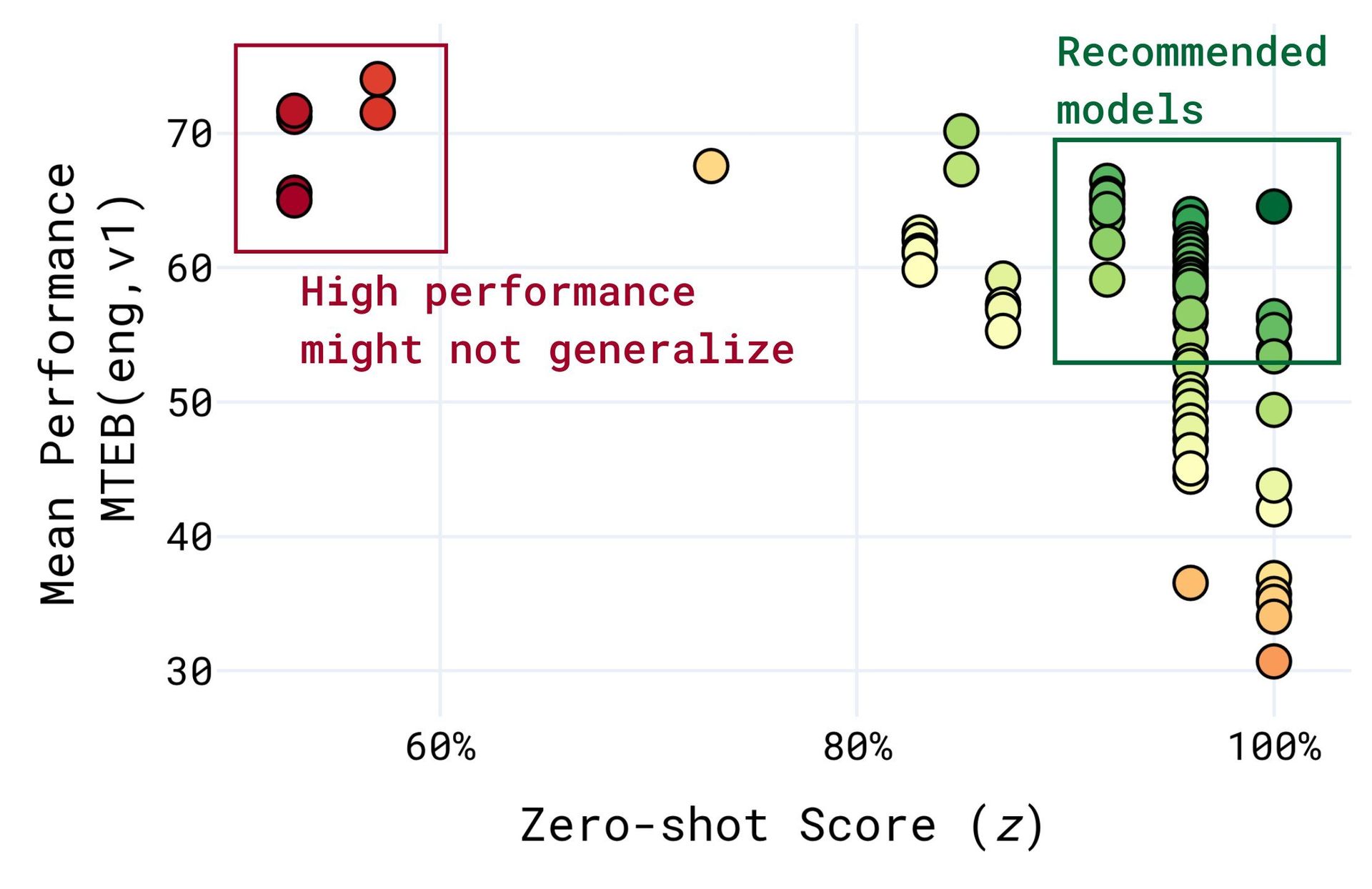 From Chung et al. (2025): Models optimized for specific benchmarks may not generalize.
From Chung et al. (2025): Models optimized for specific benchmarks may not generalize. - Misaligned Real-World Relevance: Many benchmarks rely on repurposed academic or QA datasets, lacking the complexity and domain-specific nuances (legal jargon, financial terminology, medical contexts) encountered in production systems. Domain-specific benchmarks are often too narrow for general-purpose model evaluation.
Introducing RTEB: A Hybrid Solution
RTEB tackles these issues head-on with a novel architecture:
- Open Datasets (Transparency & Reproducibility):
- Fully public corpora, queries, and relevance labels (e.g., AILACasedocs, FinanceBench, HumanEval).
- Enables community verification and reproducibility.
- Private Datasets (True Generalization Test):
- Held confidentially by MTEB maintainers to prevent targeted optimization.
- Includes datasets like
_GermanLegal1,_EnglishFinance4, and_GermanHealthcare1. - Descriptive statistics and sample triplets are provided for transparency.
- Key Insight: A significant performance drop between open and private datasets signals overfitting – a clear signal to the community.
Built for the Real World
RTEB prioritizes practical utility:
- Multilingual: Covers 20 languages, including English, Japanese, German, French, Bengali, and Finnish.
- Domain-Focused: Targets critical enterprise sectors:
- Legal: Supreme Court cases (India), statutes, multilingual legal documents.
- Healthcare: Real medical Q&A pairs (ChatDoctor), expert-verified dialogues.
- Finance: Financial report analysis (FinQA), personal finance queries.
- Code: Function retrieval (HumanEval, APPS, DS1000).
- Efficient & Meaningful: Datasets are curated to be large enough for statistical significance (>1k docs, >50 queries) without excessive computational cost.
- Retrieval-First Metric: Uses NDCG@10, the industry standard for ranking quality.
Launching in Beta: A Call to the Community
RTEB is now available on the Hugging Face MTEB leaderboard's new Retrieval section. Its launch as a beta underscores its nature as a community-driven effort. Hugging Face actively seeks:
- Feedback on the benchmark design and datasets.
- Suggestions for new high-quality datasets (especially in underrepresented languages like Chinese, Arabic, or low-resource languages).
- Vigilance in identifying dataset issues.
Acknowledging Limitations & The Path Forward
RTEB is a significant step, but not the final one. Current limitations guide future development:
- Scope: Focuses on realistic retrieval, excluding highly synthetic tasks (planned for future).
- Modality: Text-only for now; multimodal (text-image) retrieval is a future goal.
- QA Repurposing: ~50% of datasets originate from QA tasks, potentially favoring lexical matching over deep semantic understanding. New retrieval-native datasets are needed.
- Language Expansion: Continuous effort required for broader coverage.
- Private Dataset Integrity: Strict protocols ensure MTEB maintainers do not train models on private data, preserving fairness.
The ultimate goal is clear: Establish RTEB as the trusted, application-focused standard for evaluating retrieval models – moving beyond artificial benchmarks to measure real-world readiness. Evaluate your models on the RTEB leaderboard and contribute to building a more reliable future for retrieval AI.
Source: Based on the original announcement "Introducing RTEB: A New Standard for Retrieval Evaluation" by Frank Liu, Kenneth C. Enevoldsen, Solomatin Roman, Isaac Chung, Tom Aarsen, and Zoltán Fődi, published on the Hugging Face Blog, October 1, 2025.
Comments
Please log in or register to join the discussion