
Local-first architecture promises offline capabilities and cloud-like collaboration, but implementing complex features like full-text search reveals daunting tradeoffs. After two years building the Fika app, one developer's quest for seamless client-side search exposed crushing memory demands, indexing delays, and syncing nightmares—forcing a rethink of when 'local-first' is truly worth the cost. This deep dive uncovers the hard-won lessons behind balancing user experience with developer sanity.

The allure of local-first applications is undeniable: instant offline access, zero-latency interactions, and user-controlled data. Yet beneath this utopian vision lies a labyrinth of technical compromises that intensify as apps scale. For Paolo Armentano, creator of the local-first content curation app Fika, the struggle crystallized around one critical feature—full-text search. His two-year odyssey, documented in a candid blog post, reveals why developer experience (DX) in local-first systems degrades sharply with complexity, especially when wrestling with 100 million characters of user data.
The Search Imperative: Speed, Offline, and Relevance
Fika—built on Replicache for syncing, Postgres as the source of truth, and Cloudflare Workers for server logic—needed search that could handle ~10k entities (stories, feeds, posts) per user. Armentano's requirements were uncompromising:
- Recall-driven results: High relevance via algorithms like BM25.
- Fuzziness: Tolerance for typos and word variations.
- Highlighting: Clear context for matches.
- Hybrid search: Combining keyword and semantic vector results.
- Local-first execution: Instant, offline-capable queries without server round-trips.
"Other bookmark managers like Raindrop struggle offline because they’re cloud-bound," he notes. "This was Fika’s differentiation."
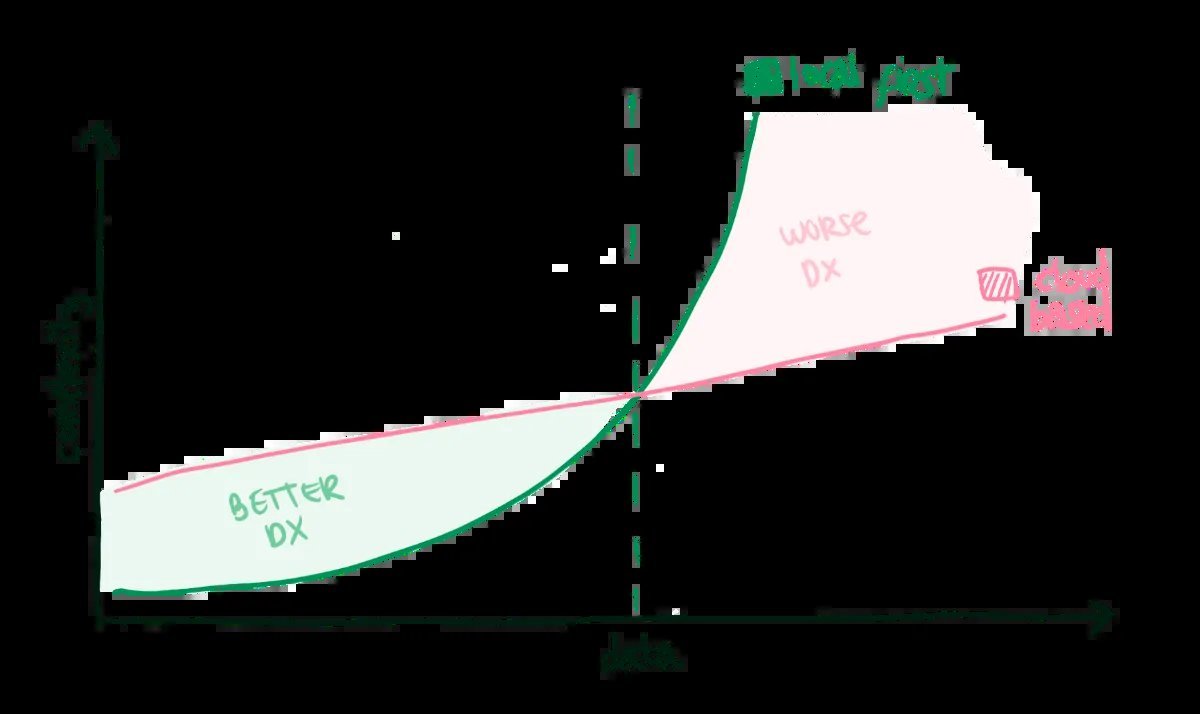
Four Architectures, Four Lessons in Tradeoffs
Attempt 1: Postgres Simplicity → Relevance Fail
Armentano’s first try leaned on Postgres’s built-in full-text search. "Postgres can do everything out of the box, right? I drank the Kool-Aid," he admits. But reality bit hard: unaccent function immutability issues, archaic ranking (ts_rank instead of BM25), and mediocre results. "Vanilla Postgres search relevance just wasn’t great."
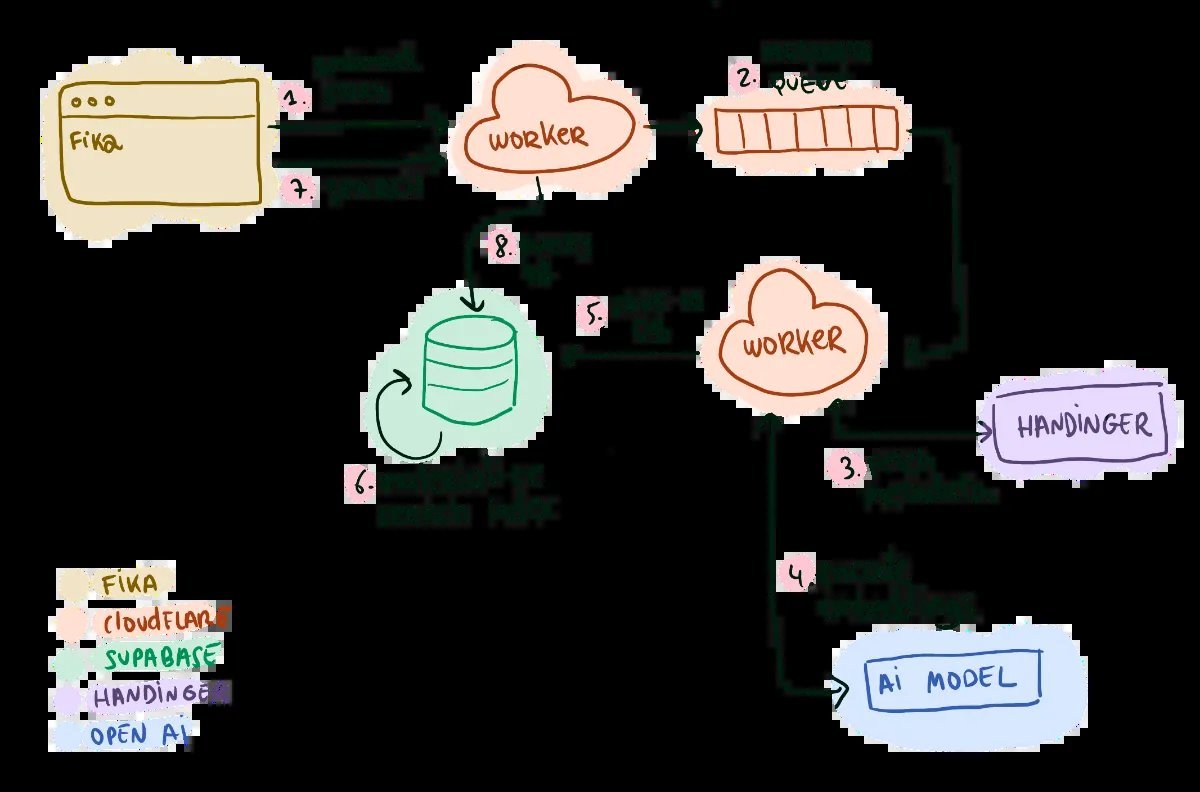 Caption: Server-centric Postgres architecture proved brittle for modern search demands.
Caption: Server-centric Postgres architecture proved brittle for modern search demands.
Attempt 2: Typesense Server-Side → Latency Penalty
Switching to Typesense, an open-source search engine, solved relevance with minimal DX friction. Updates synced from Postgres to Typesense, delivering fast, accurate results. But it remained server-dependent—meaning no offline support and inherent network latency. "For a user on a spotty connection, even 100ms delays undermine the local-first promise," Armentano explains.
 Caption: Typesense offered better relevance but couldn't eliminate server reliance.
Caption: Typesense offered better relevance but couldn't eliminate server reliance.
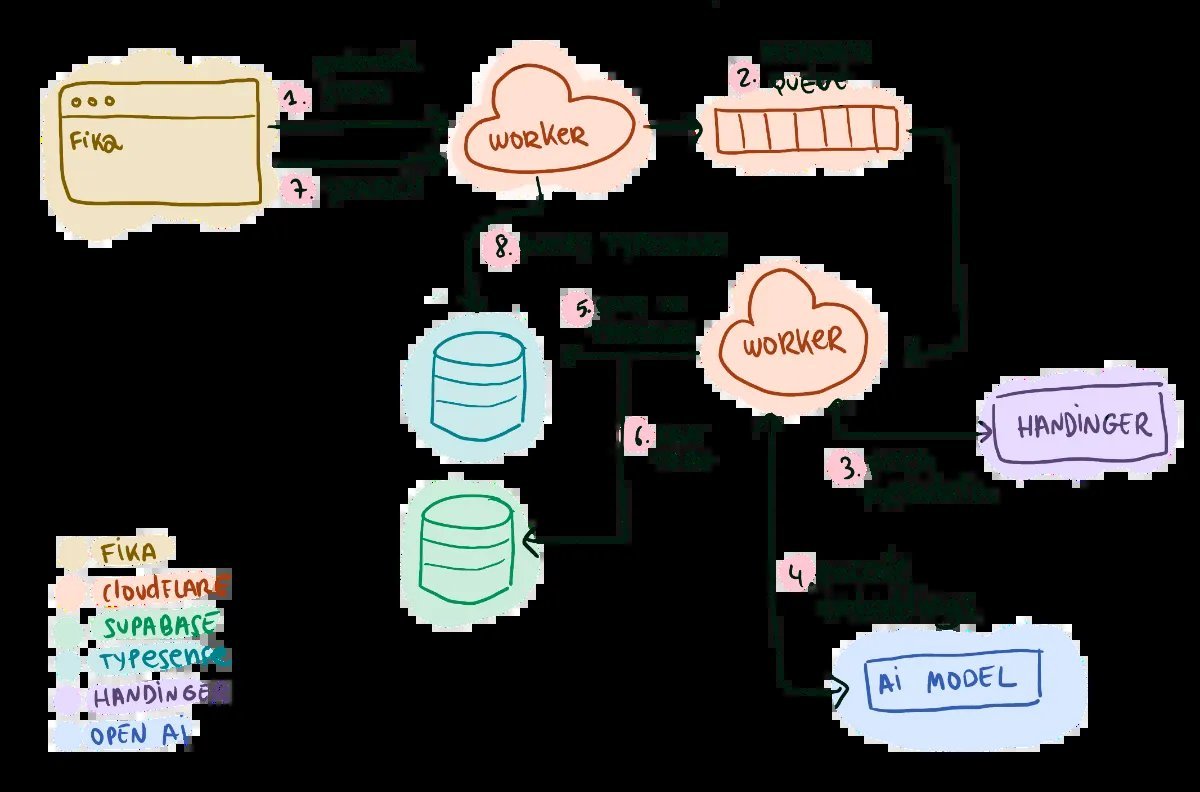
Attempt 3: Orama Client-Side → Memory and Indexing Overload
Enter Orama, a TypeScript-based in-memory search engine running in-browser. It delivered true local search with hybrid capabilities, but scaling to Fika’s data volume exposed brutal constraints:
- Memory bloat: ~300MB RAM consumed for index structures.
- Slow cold starts: 9-second index rebuilds on mobile devices.
- Sync complexity: A secondary Replicache instance for text blobs increased transaction conflicts.
- Vector search impracticality: Syncing embeddings ballooned to ~500MB of JSON.
"Opaque semantic matches can sabotage user trust. Why did searching for 'bread' return an AI paper about croissants? With keywords, results are transparent," Armentano observes, leading him to abandon hybrid search.
 Caption: Orama enabled offline queries but devoured resources and slowed startups.
Caption: Orama enabled offline queries but devoured resources and slowed startups.
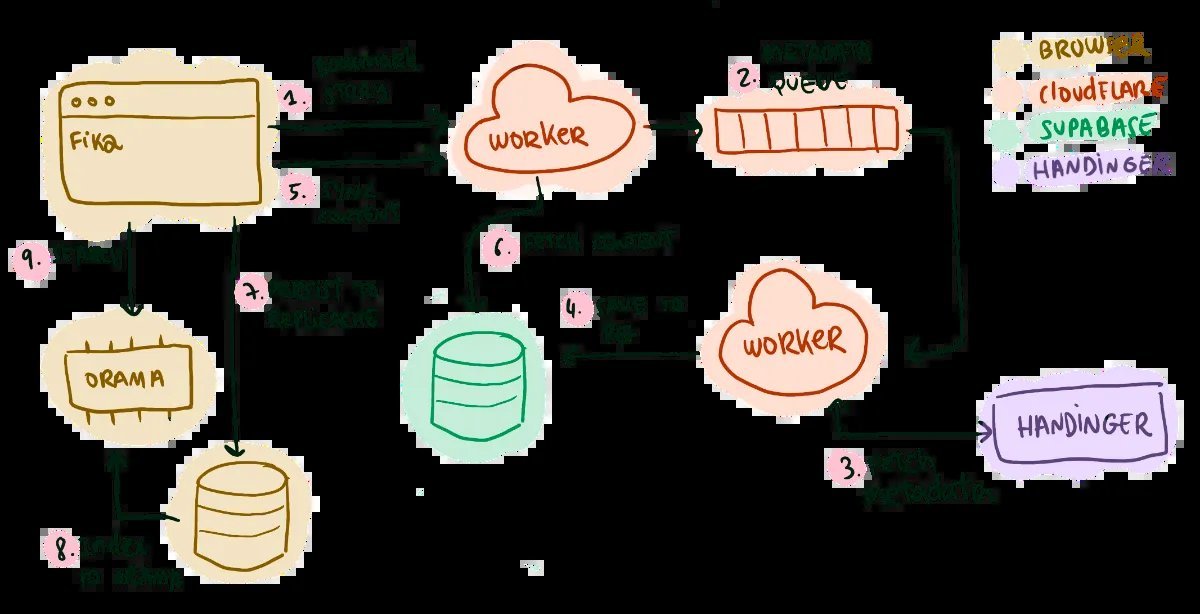
Final Solution: FlexSearch Persistence → Pragmatic Balance
A breakthrough came with FlexSearch’s 2025 update, adding IndexedDB-backed persistent indexes. This enabled:
- Disk-based indexing: Near-zero search latency after initial sync, with lazy loading.
- Memory efficiency: Minimal runtime overhead (~10x reduction vs. Orama).
- Incremental updates: Using Replicache’s
experimentalWatchto sync only changed documents.
Cold starts still take minutes for full indexing, but searches are instant thereafter. "The tradeoff—complexity in exchange for offline speed—is now justified," says Armentano.
The Local-First Verdict: When the Juice Is Worth the Squeeze
Armentano’s journey underscores that local-first isn’t a free lunch. As data volume grows, DX plummets under device constraints: memory limits, CPU variability, and storage quirks. He advises adopting it only when:
- Values align: User data ownership and offline resilience are non-negotiable.
- Performance profiles fit: Long sessions justify upfront indexing costs.
- Collaboration is core: Real-time sync is intrinsic to the app’s function.
"Cloud-centric apps avoid these headaches by pushing state to servers," he concedes. "But when local-first clicks—like Fika’s now-instant searches—it feels like magic. Just pack patience, coffee, and a calculator."
Source: Fika Blog
Comments
Please log in or register to join the discussion