From AlexNet's seismic impact to Transformers' rise and the mysteries of double descent, we analyze the 10 papers that defined AI's most explosive decade. Discover how initialization quirks, architectural innovations, and paradigm shifts reshaped technology's trajectory.
The Architectural Revolution: 2010-2019's Defining AI Papers

The 2010s witnessed deep learning's metamorphosis from academic curiosity to world-changing technology. Fueled by GPU acceleration and massive datasets, breakthroughs in computer vision, NLP, and reinforcement learning redefined what machines could achieve. This analysis distills the decade's pivotal research—papers that solved existential problems like vanishing gradients, enabled unprecedented scale, and revealed surprising new behaviors.
2010: Taming the Chaos of Deep Networks
Understanding the difficulty of training deep feedforward neural networks (Glorot & Bengio) diagnosed why deep networks faltered. Their solution—Xavier initialization—mathematically stabilized weight initialization by scaling variance relative to layer connections. This prevented activations from exploding or vanishing during training. The paper also proposed SoftSign activations, though ReLU would soon dominate.
 Visualizing activation stability with proper initialization
Visualizing activation stability with proper initialization
2011: The ReLU Revolution
Deep Sparse Rectifier Neural Networks (Glorot et al.) championed ReLU activations (max(0,x)), solving the vanishing gradient problem that plagued sigmoids. Though simple, ReLU enabled deeper networks by maintaining stronger gradients. Later variants (Leaky ReLU, ELU, GELU) addressed "dying neuron" issues, with GELU becoming crucial for Transformers.
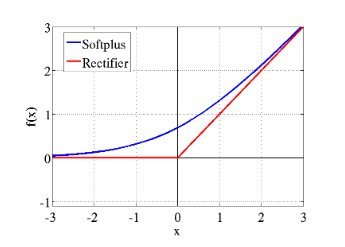 ReLU's linearity (orange) vs. Softplus's smooth curve
ReLU's linearity (orange) vs. Softplus's smooth curve
2012: The Big Bang Moment
ImageNet Classification with Deep Convolutional Neural Networks (Krizhevsky et al.)—AlexNet—ignited the deep learning explosion. Its 8-layer GPU-accelerated architecture slashed ImageNet error by 10.8%, proving deep CNNs' superiority. Combined with ImageNet's scale, this victory shifted AI's focus toward data and compute.
"AlexNet didn't just win ILSVRC 2012—it redefined the playing field. Suddenly, everyone needed GPUs and big data."
2013-2014: New Frontiers Emerge
- word2vec (Mikolov et al.) turned words into semantic vectors via context prediction, becoming NLP's universal representation.
- DQN (Mnih et al.) mastered Atari games through deep reinforcement learning, showing RL could handle high-dimensional states.
- GANs (Goodfellow et al.) launched the generative AI era via adversarial training, though later refinements like Wasserstein GAN stabilized training.
- Attention mechanisms (Bahdanau et al.) replaced fixed-length context in translation, foreshadowing Transformers.
- Adam optimizer (Kingma & Ba) became the default for adaptive, low-tuning-requirement training.
2015: Engineering Depth and Stability
Deep Residual Learning (He et al.) solved deep network degradation via skip connections. By letting layers learn residual functions (output = input + transformation), ResNet enabled 100+ layer networks—critical for modern vision models.
Batch Normalization (Ioffe & Szegedy) accelerated convergence by standardizing layer inputs, mitigating internal covariate shift. Disputed theoretically but indispensable practically.
2016-2017: Superhuman and Scalable
AlphaGo (Silver et al.) defeated Lee Sedol using policy/value networks and MCTS, demonstrating deep RL's strategic prowess. Later, AlphaGo Zero mastered Go without human data.
Transformers (Vaswani et al.) replaced RNNs with self-attention, enabling parallelization and scale. Neural Architecture Search (Zoph & Le) automated model design, pushing state-of-the-art efficiency.
2018: The Language Explosion
BERT (Devlin et al.) revolutionized NLP via bidirectional context and masked language modeling. Its pretrain-finetune paradigm enabled transfer learning dominance, inspiring GPT-2, XLNet, and Transformer-XL.
2019: Peering Into the Black Box
Deep Double Descent (Belkin et al.) challenged classical bias-variance tradeoffs, showing test error can decrease as models grow past overfitting capacity. The Lottery Ticket Hypothesis (Frankle & Carbin) revealed sparse trainable subnetworks within larger models, reshaping pruning approaches.
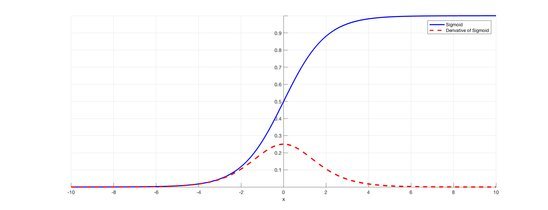 Sigmoid's vanishing derivative (dashed) vs. ReLU's constant gradient
Sigmoid's vanishing derivative (dashed) vs. ReLU's constant gradient
The Unanswered Questions
While architectures and scale drove progress, the 2010s exposed deep learning's empirical nature. Initialization, normalization, and optimization often succeeded without complete theoretical grounding. As we enter the 2020s, understanding why these methods work—through lenses like double descent and lottery tickets—may unlock robustness, efficiency, and generalization beyond today's limits.
Source: Adapted from Leo Gao's "The Decade of Deep Learning" (leogao.dev), with additional technical context and analysis.
Comments
Please log in or register to join the discussion