
As AMD GPUs match and even surpass NVIDIA's performance in raw specs, a critical software gap remains. Researchers from Stanford's Hazy Research group introduce HipKittens, a collection of programming primitives that unlocks the true potential of AMD's CDNA architecture, paving the way for a more diverse and competitive AI hardware landscape.
The AI revolution is compute-hungry, with researchers constantly pushing the boundaries of what's possible with neural networks. For years, this quest for performance has been dominated by a single hardware provider, leaving significant potential on the table. But a shift is underway. AMD GPUs are now offering state-of-the-art speeds and feeds, with raw specifications that often surpass their NVIDIA counterparts. Yet, this performance remains largely untapped due to a critical gap: mature software ecosystems.

"AI is compute hungry. So we've been asking: How do we build AI from the hardware up? How do we lead AI developers to do what the hardware prefers?" This question drives the work of researchers from Stanford's Hazy Research group, who have introduced HipKittens (HK), an opinionated collection of programming primitives designed to help developers realize the full capabilities of AMD hardware.
The AMD Landscape: What's Different?
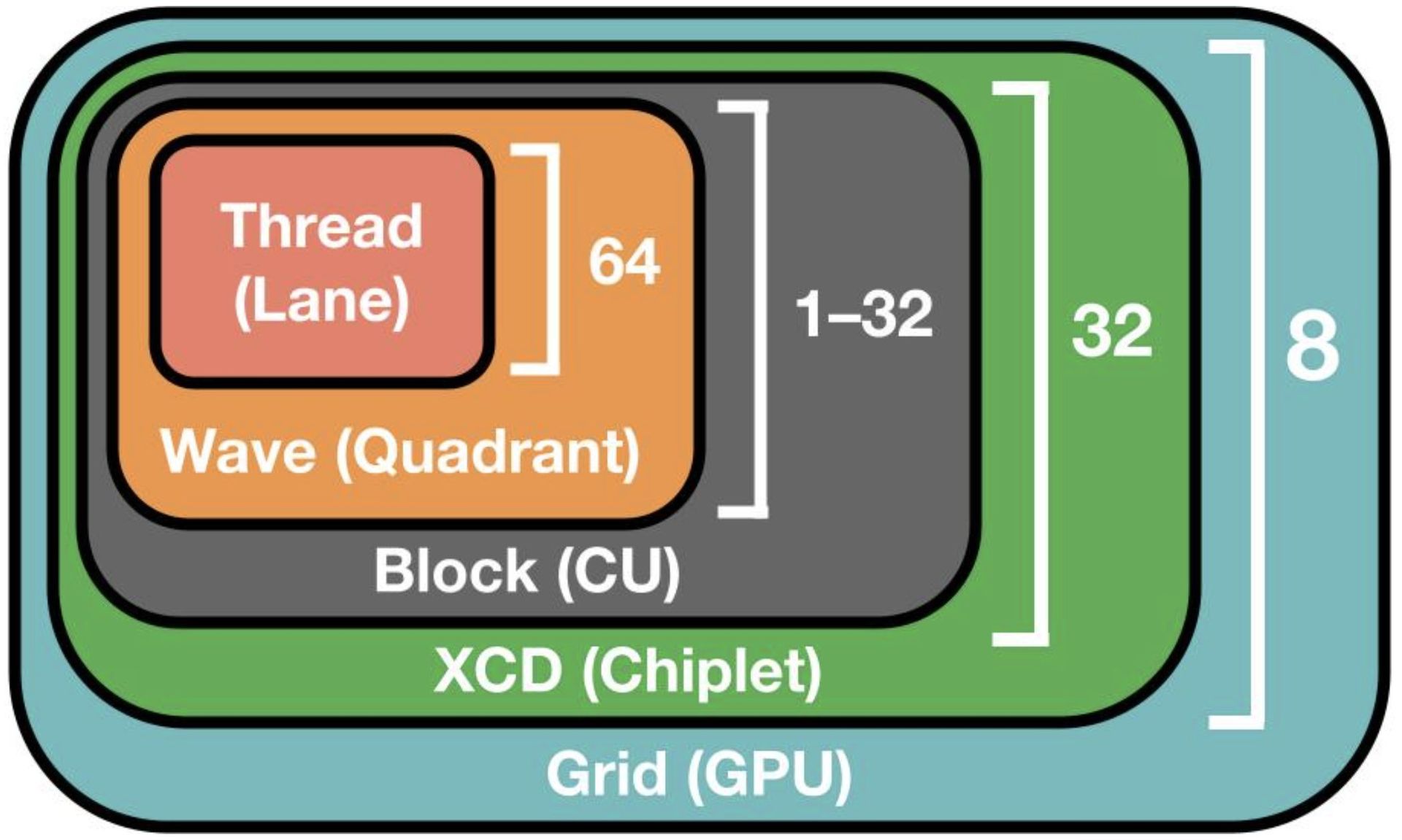
To understand why AMD GPUs have been underutilized, we must first appreciate their architectural differences. An AMD MI355X GPU, for example, features 256 processors called "compute units" (CUs), with each CU containing four SIMDs. A 64-thread "wave" (contrasting with NVIDIA's 32-thread warp) occupies a single SIMD.
The hardware specifications tell an intriguing story:
| Spec | NVIDIA B200 SXM5 | AMD MI355X OAM |
|---|---|---|
| B16 matrix/tensor | 2.2 PFLOPs | 2.5 PFLOPs |
| MXFP8 matrix/tensor | 4.5 PFLOPs | 5.0 PFLOPs |
| MXFP6 matrix/tensor | 4.5 PFLOPs | 10.1 PFLOPs |
| MXFP4 matrix/tensor | 9.0 PFLOPs | 10.1 PFLOPs |
| Memory capacity | 180 GB | 288 GB |
| Memory bandwidth | 8.0 TB/s | 8.0 TB/s |
Table 1: Hardware overview. Peak memory and compute speeds for the latest generation GPU platforms.
AMD GPUs excel in several areas: they offer 2x larger register files per processor, 60% more processors per GPU (256 CUs vs. 160 SMs), and fine-grained matrix core instructions. However, they lack several features that NVIDIA developers have come to rely on:
- Asynchronous matrix multiplication instructions (wgmma, tcgen05)
- Register reallocation (waves sharing registers)
- Tensor memory acceleration
- First-class mbarrier primitives
Perhaps most significantly, AMD is leading the transition to chiplet architectures. The MI355X integrates eight chiplets (XCDs), each with its own L2 cache, creating a disaggregated memory hierarchy that presents unique optimization challenges.
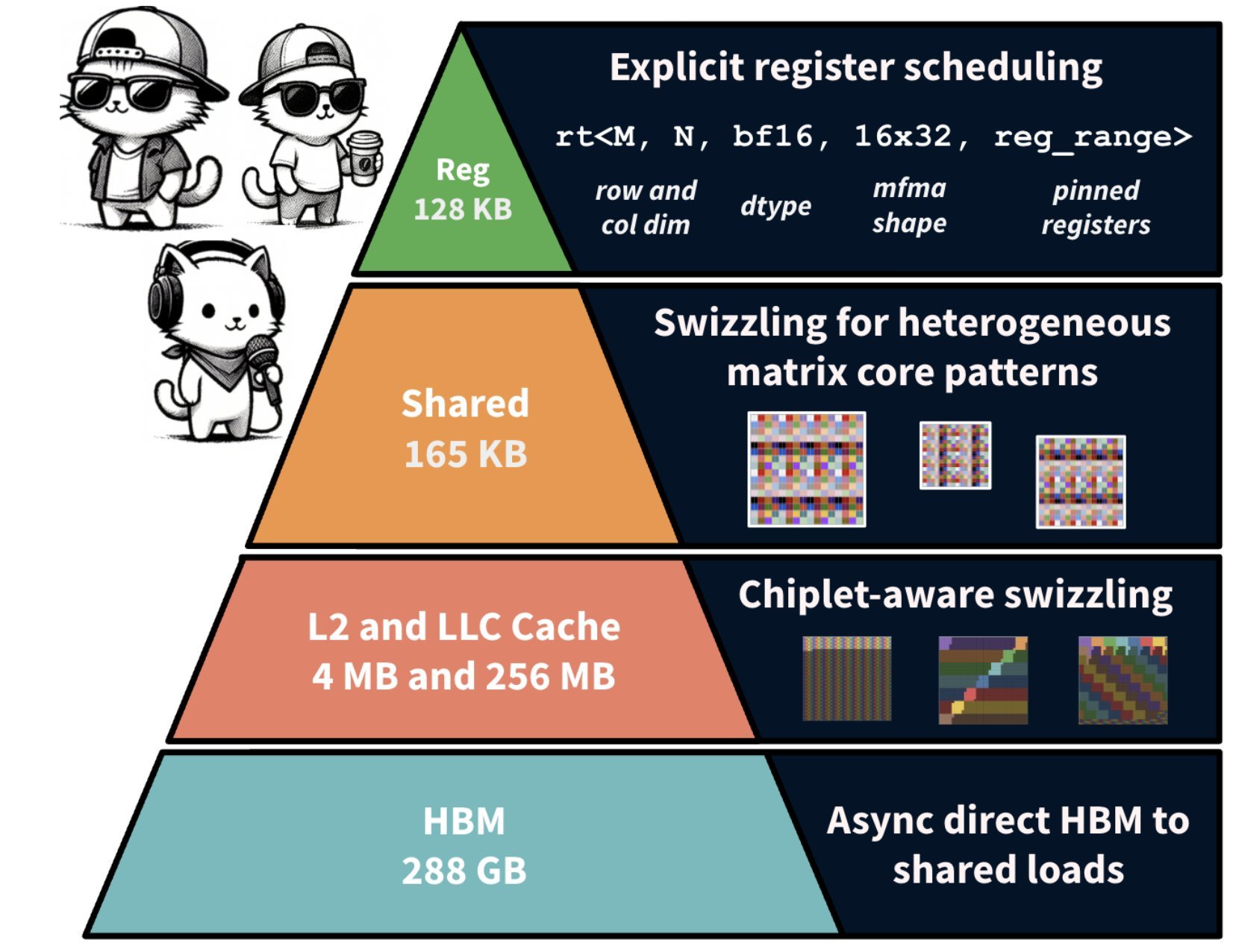
The Three Pillars of HipKittens
HipKittens addresses AMD's architectural idiosyncrasies through three key insights:
1. Optimized Memory Access Patterns
Memory optimization is crucial on any GPU, but AMD's layouts, HIPCC compiler limitations, and undocumented instruction behaviors create new challenges.
"A core tenant of HK and TK is to give developers full control over register allocation by remaining C++ embedded," the researchers explain. "Compilers like Triton prevent register management altogether, but surprisingly we find that even the HIPCC compiler imposes severe limitations."
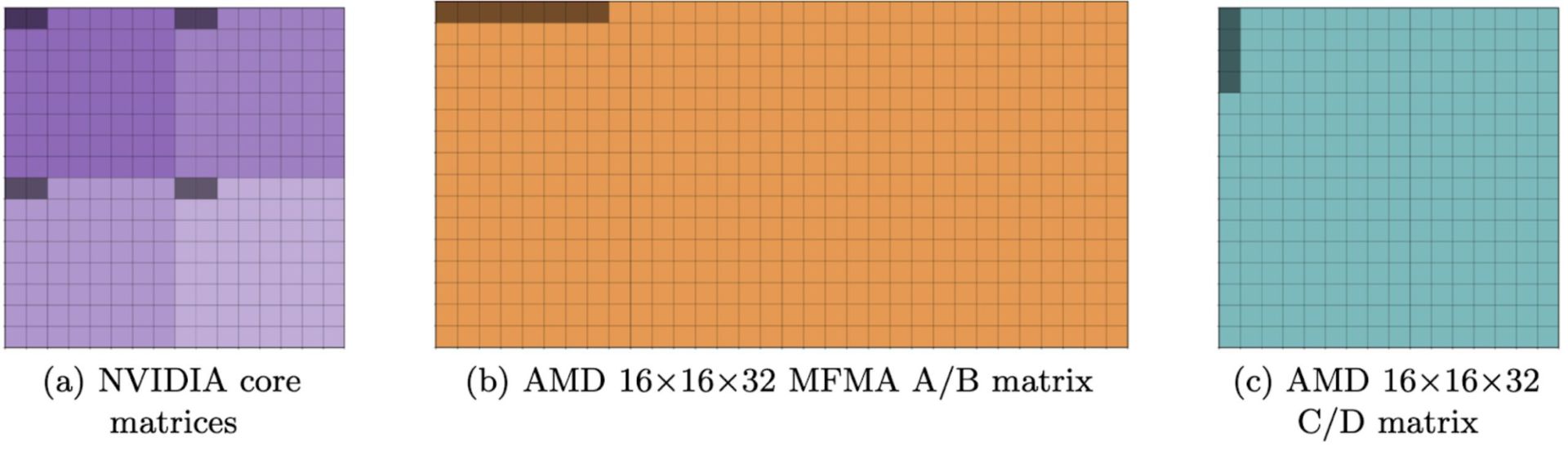
One critical issue is AMD's register file structure. When a single wave is mapped per SIMD, the 512 registers are divided into 256 accumulator general purpose registers (AGPRs) and 256 vector general purpose registers (VGPRs). While AGPRs can serve as inputs for MFMA instructions, the HIPCC compiler cannot generate code that utilizes them effectively, forcing inefficient register-to-register transfers.
AMD's matrix core layouts also differ significantly from NVIDIA's. While NVIDIA layouts follow a regular pattern composed of an underlying "core matrix" structure, AMD layouts vary considerably based on data type and matrix shape.
"We show that it's not possible to use a single swizzle pattern for all layouts," the researchers note. "Sometimes we want to use multiple matrix shapes within the same kernel, meaning our swizzle pattern needs to be compatible with multiple types of layouts concurrently."
2. AMD-Centric Wave Scheduling
The dominant paradigm for achieving high occupancy on NVIDIA GPUs is wave specialization, where producer waves focus on memory movement while consumer waves focus on computation. This strategy underpins state-of-the-art AI kernels like FlashAttention-3 and COMET.
However, wave specialization struggles on AMD due to the lack of register reallocation. On the MI355X, registers are statically divided across all waves. Producer waves that only need a few registers for address calculation are allocated more than they need, while consumer waves cannot recoup those registers, forcing them to either spill registers to scratch memory or run at lower arithmetic intensity.
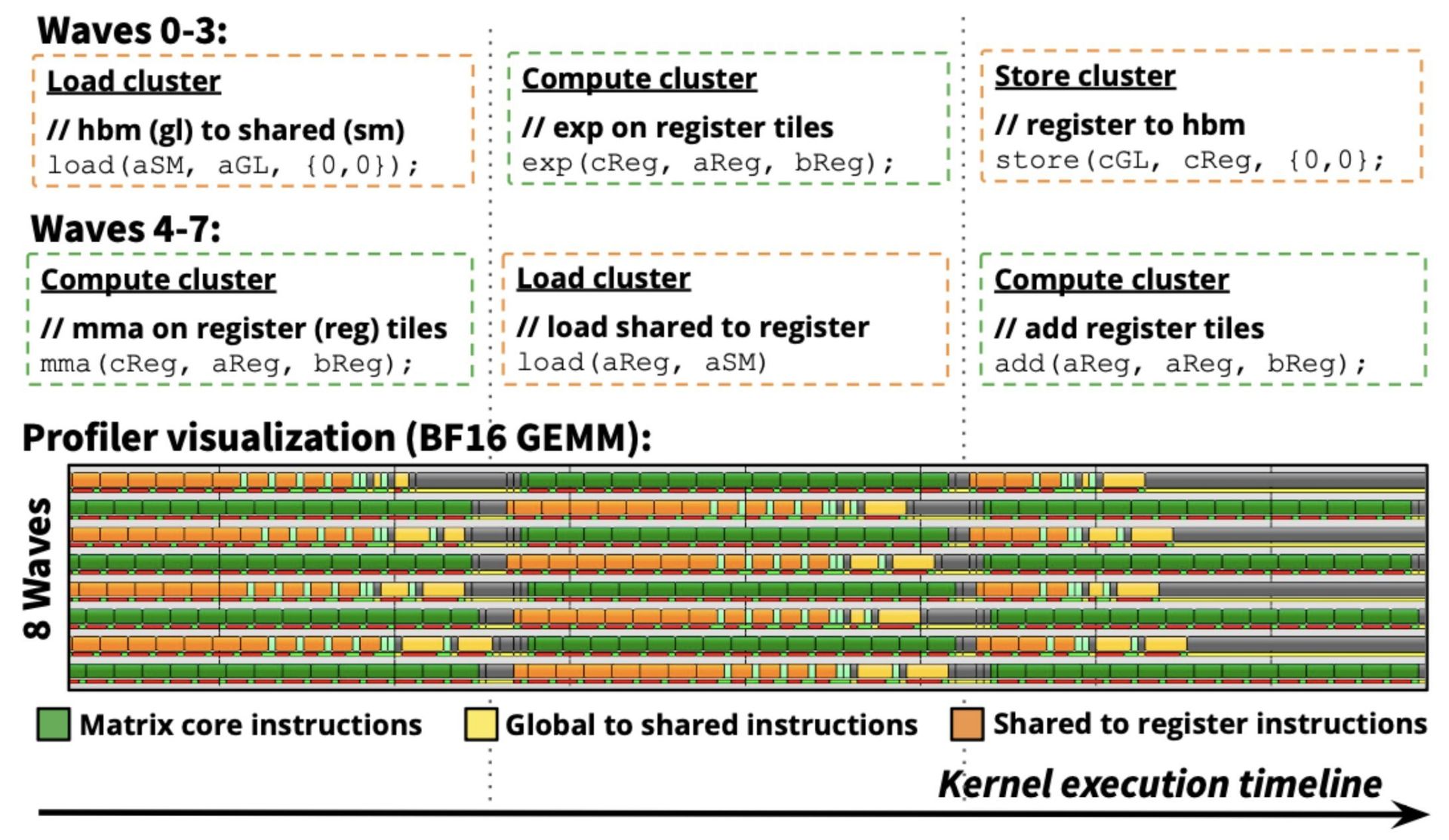
Through extensive benchmarking, the researchers identified two scheduling patterns that consistently yield high performance on AMD GPUs:
- 8-wave ping-pong: Assigning two waves per SIMD that alternate between memory and compute clusters
- 4-wave interleave: Assigning one wave per SIMD that finely switches between memory and compute operations
"These two patterns tradeoff programmability and performance, where 8-wave and its large tile primitives lead to compact code and 4-wave fine-grained interleaving expands code size," the team explains. "Surprisingly, the 8-wave schedule is sufficient to achieve SoTA-level performance on GEMMs and attention forwards."
3. Chiplet-Aware Grid Scheduling
As GPUs move toward chiplet-based architectures, memory locality becomes increasingly complex. On AMD's MI355X with its eight XCDs, thread blocks are scheduled in a round-robin fashion, meaning the grid schedule directly affects cache effectiveness.
"Even perfectly tuned kernels can lose bandwidth if their grid layout is cache-unfriendly," the researchers warn.
HipKittens addresses this by introducing a chiplet-aware scheduling strategy that reorganizes the grid launch order to better exploit locality at both the L2 (per-chiplet) and LLC (shared) cache levels. By grouping thread blocks that operate on nearby regions of the output matrix, the system naturally promotes reuse of overlapping input data tiles across cache hierarchies.
Putting It All Together: Code in Action
The power of HipKittens becomes evident when examining actual kernels. Here's a glimpse into the hot loop of their attention forwards pass kernel, which uses the 8-wave ping-pong schedule:
#pragma unroll
for (int j = 3; j < num_tiles - 1; j += 2) {
// Cluster 0: Compute
zero(att_block[1]);
swap_layout_and_transpose(k_reg_transposed, k_reg);
mma_AtB(att_block[1], k_reg_transposed, q_reg_transposed, att_block[1]);
// Cluster 1: Memory
G::load<1, false>(k_smem[1], g.Kg, {batch_idx, j, head_idx_kv, 0});
load(v_reg, v_smem[0]);
// Additional clusters follow, alternating between compute and memory...
}
Similarly, their BF16 GEMM kernel demonstrates the same ping-pong pattern, with waves alternating between compute clusters and memory clusters to maximize throughput.
The Path to Multi-Silicon AI
HipKittens delivers competitive performance on AMD CDNA3 and CDNA4 through these three key insights. The researchers' kernels consistently achieve peak performance among AMD baselines across workloads and even compete with peak Blackwell kernels.
"We believe that the HIPCC register scheduling is one of the most important areas for improvement in AMD's kernel software stack," they note.
The ultimate vision is a more diverse and competitive AI hardware landscape. "Realizing AI's full potential requires diverse, open hardware," the team argues. "Today, that means making AMD GPUs truly accessible. We want more AI in the world. AI has relied on and innovated on a single hardware provider, but we need to be able to use and experiment with all the compute we can."
As the AI industry continues its relentless pursuit of performance, innovations like HipKittens are crucial for unlocking the potential of alternative hardware architectures. The future of AI isn't monolithic—it's multi-silicon, and with the right software tools, we're beginning to surf toward that horizon.
Comments
Please log in or register to join the discussion