Discover how meticulous CUDA kernel optimization can push NVIDIA's Tensor Cores to their absolute limits. By evolving from naive implementations to sophisticated techniques like permuted shared memory and asynchronous pipelines, this journey achieves 93% of the RTX 4090's theoretical peak performance—matching cuBLAS efficiency.
The Tensor Core Imperative
In the era of NVIDIA's Ada architecture, harnessing Tensor Cores isn't just advantageous—it's essential for competitive performance. When tasked with optimizing a matrix multiplication kernel (M=N=K=4096, fp16 inputs, fp32 accumulation) for an RTX 4090, initial naive implementations delivered a dismal 17.8% of peak throughput. The goal? Match cuBLAS' 153.6 TFLOP/s—93% of the GPU's theoretical limit.
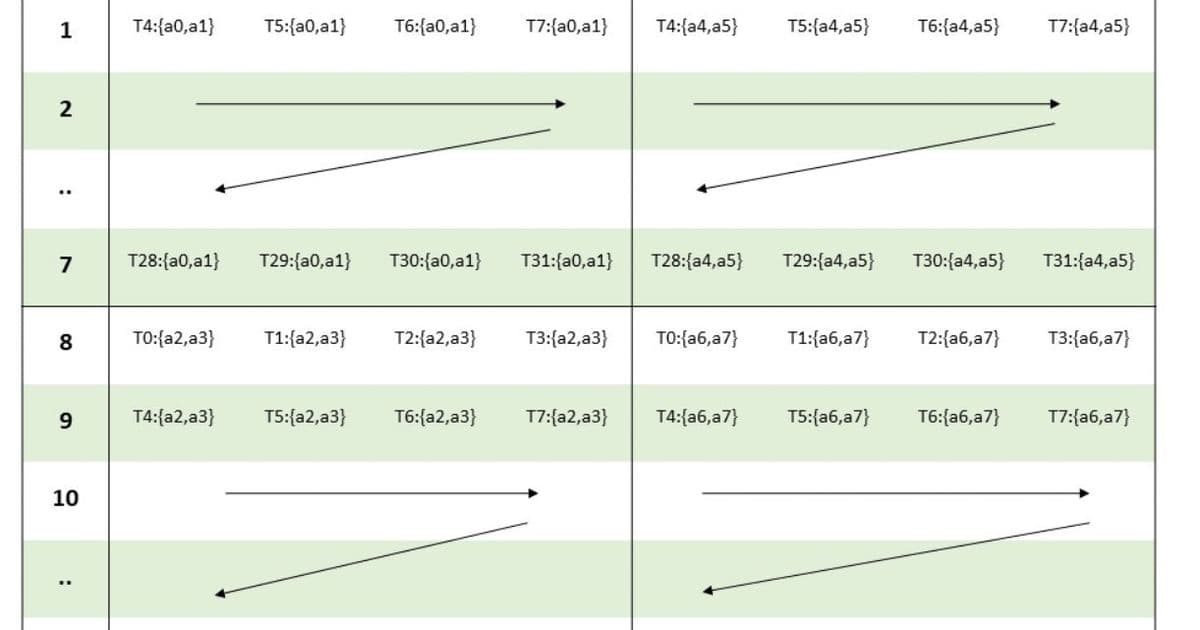
The Optimization Odyssey
Kernel 1.0: The Naive Approach
Our starting point used basic PTX mma instructions with unoptimized memory access. Each thread loaded individual 16-bit values, causing uncoalesced global loads and shared memory bank conflicts. At 29.4 TFLOP/s, it was outperformed even by non-Tensor Core kernels. Profiling revealed 31 cycles stalled per instruction on memory throttling.
The Breakthrough: Kernel 2.0
Two critical innovations changed everything:
- 128-bit Vectorized Loads: Operating on
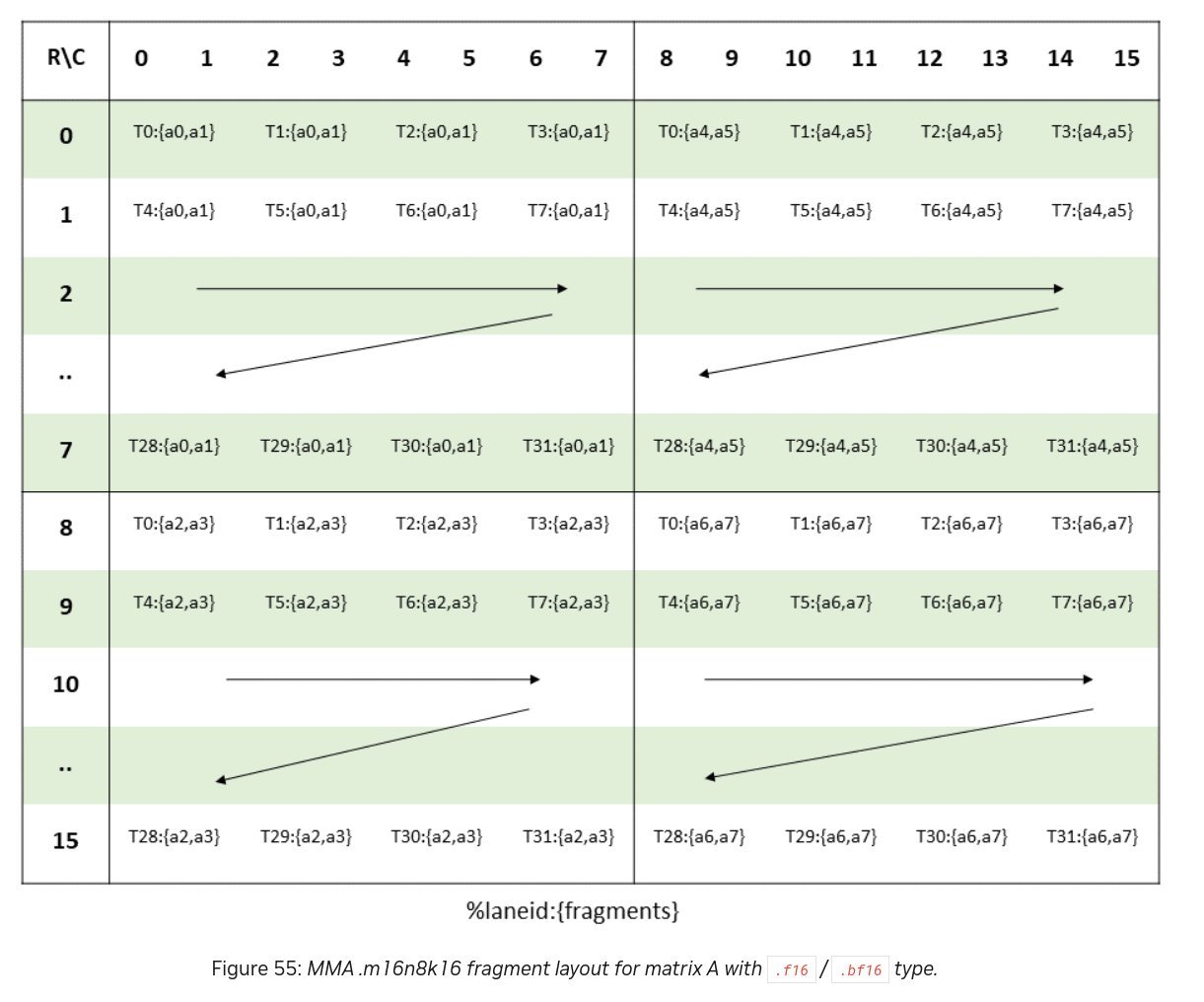
uint4vectors aligned with Tensor Core's 8x8x128b computation blocks - Permuted Shared Memory Layout: Using XOR-based indexing (
storeCol = (laneID % 8) ^ (laneID / 8)) to eliminate bank conflicts duringldmatrixoperations
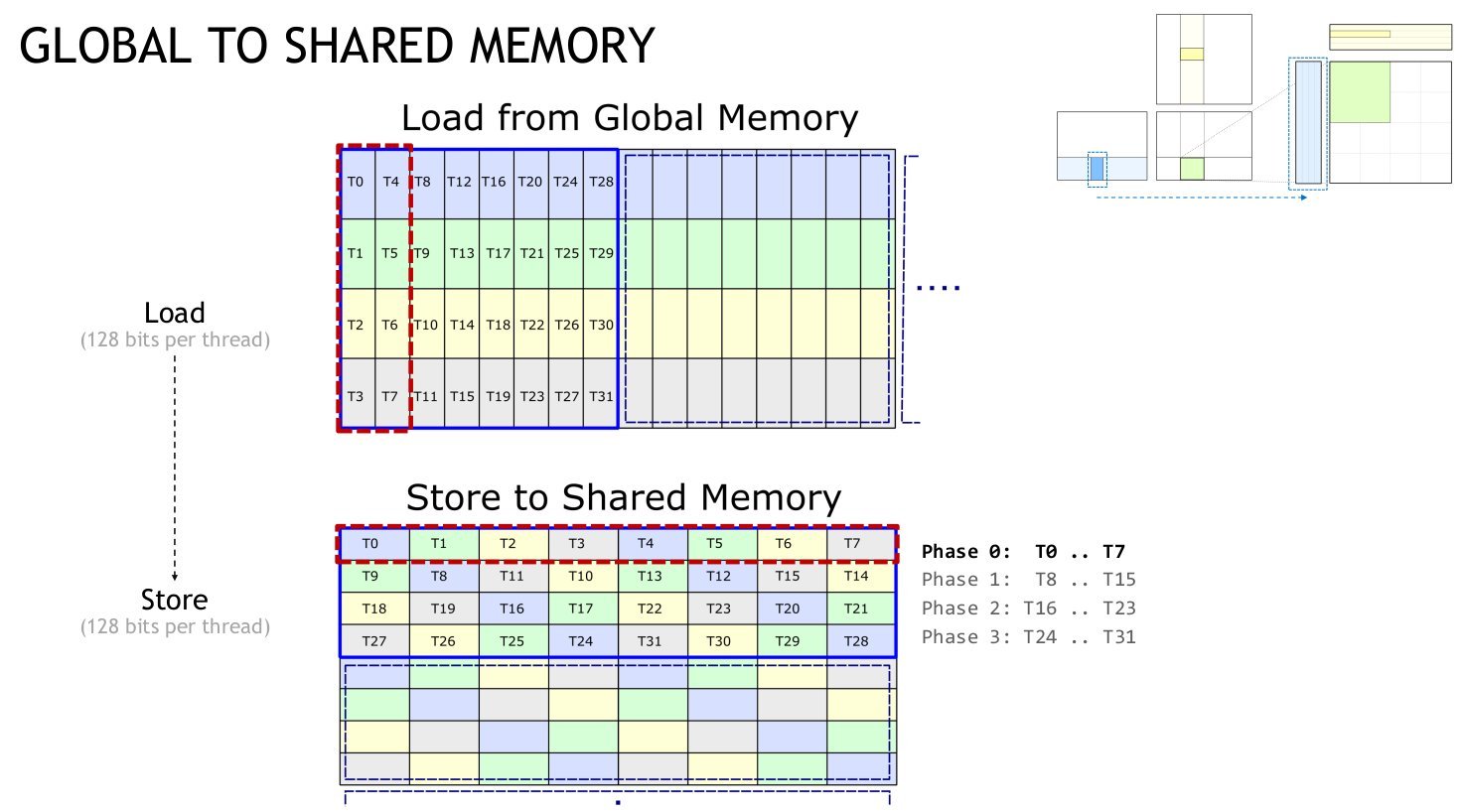
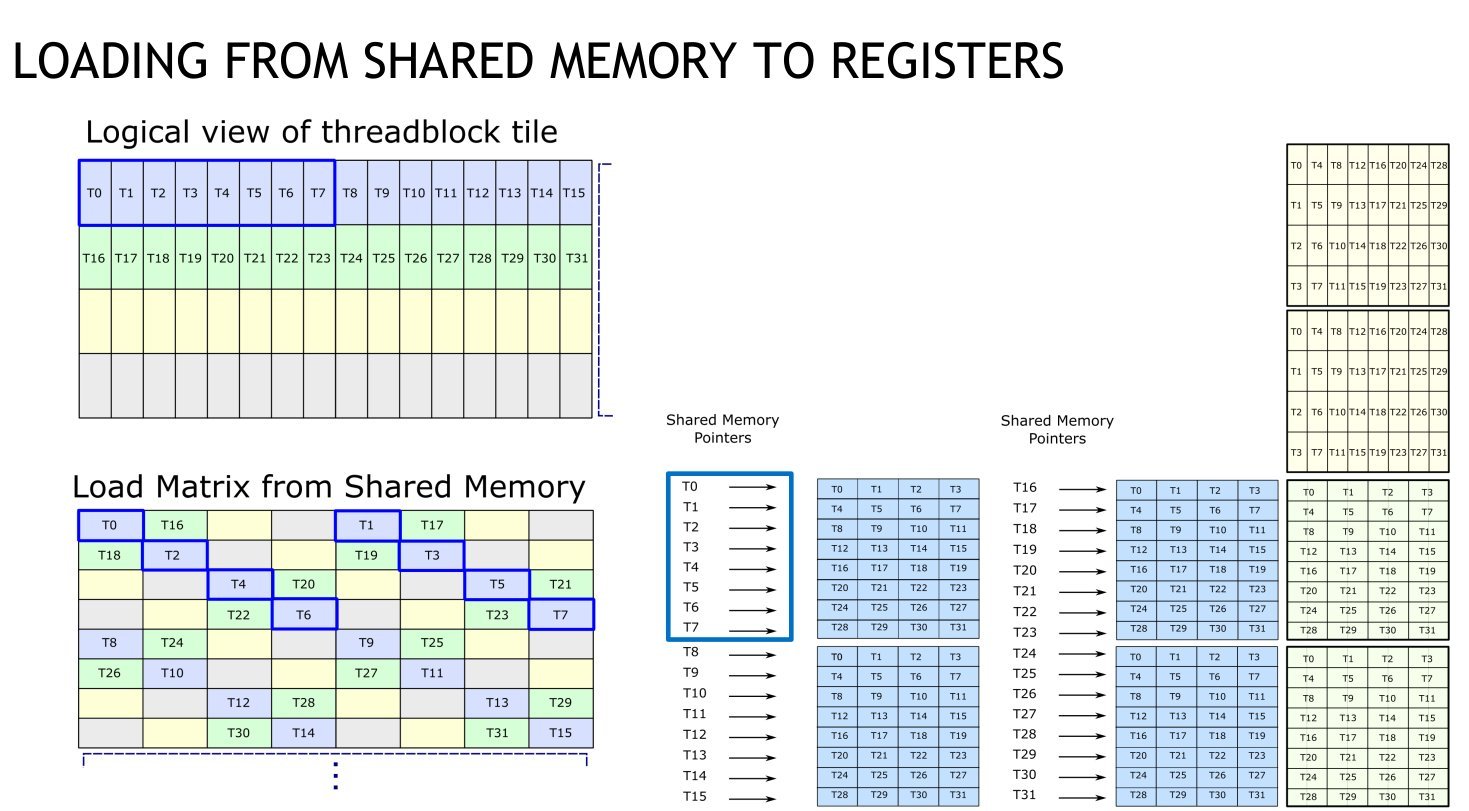
The permuted layout ensured each 8-thread phase accessed conflict-free banks. Combined with warp-wide ldmatrix PTX instructions, throughput soared to 127.3 TFLOP/s—a 4.3x improvement. Register tweaks (Kernel 2.1) pushed this to 133.4 TFLOP/s.
Kernel 3.0: Asynchronous Warfare
Despite progress, barrier stalls persisted. Enter cp.async—PTX instructions enabling asynchronous copies from global to shared memory. We implemented a 3-stage pipeline:
__device__ void cp_async(uint4 *dst, const uint4 *src) {
asm volatile("cp.async.cg.shared.global.L2::128B [%0], [%1], %2;\n"
:: "r"(__cvta_generic_to_shared(dst)), "l"(src), "n"(16));
}
Circular buffers in shared memory allowed concurrent computation and data movement. Though initially a marginal gain, combining this with 4x tiling in Kernel 3.1 (processing 128x128 output tiles per thread block) was revolutionary.
The Triumph: 153.6 TFLOP/s
Kernel 3.1 achieved parity with cuBLAS at 895 μs—93% of the RTX 4090’s peak. Warp state analysis revealed the bottleneck had shifted: 36-cycle stalls waiting for Tensor Core availability, confirming near-optimal utilization. Surprisingly, Nsight metrics showed only 47.3% Tensor Core utilization, suggesting tooling inaccuracies in latency modeling.
Why This Matters Beyond Benchmarks
- Memory Hierarchy Mastery: Permuted layouts resolve bank conflicts endemic to Tensor Core workflows
- Async Overheads:
cp.asyncrequires careful staging to offset increased shared memory pressure - Precision Pitfalls: Direct accumulation in
mmacaused rounding errors—external FP32 accumulation corrected this at 10μs cost
As one CUDA developer noted: "Optimizing for Ada isn't about raw ops—it's about orchestrating data movement to feed the tensor core beast."
The Path Forward
While tailored to specific dimensions, these techniques reveal universal principles: vectorization alignment, conflict-free shared memory, and pipelining are non-negotiable for modern GPU kernels. The battle for performance now shifts to managing the tension between occupancy and register pressure—a challenge for next-generation architectures.
Code and benchmarks available on GitHub.
Source: Sam Patterson, spatters.ca/mma-matmul (CC BY 4.0)
Comments
Please log in or register to join the discussion