
Today's AI agents possess remarkable reasoning skills but suffer from crippling amnesia, forgetting interactions after each session. We dissect the critical challenge of engineering memory into LLMs—exploring short-term vs. long-term systems, explicit vs. update strategies, and the hard problems of relevance and bloat. Discover why solving memory isn't just about storage, but building a smarter cognitive architecture.
Imagine hiring a brilliant co-worker: they reason, write, and research with superhuman skill. But every morning, they forget everything they ever learned. This is the stark reality for most AI agents today. Despite advances in reasoning and tool use, their inherent statelessness—the inability to remember past interactions, preferences, or learned skills—remains a critical limitation. As Phil Schmid highlights in his analysis, memory isn't a luxury; it's the missing cornerstone for truly intelligent agents.
The Context Bottleneck
LLMs process information within a constrained context window. Context Engineering—the art of filling this space with precisely the right tools and information at the right time—is paramount. As Schmid notes, it's a "delicate balance." Too little context cripples the agent; too much inflates costs and drowns signal in noise. The most potent source for that "right information"? The agent's own accumulated experience.
 The context window acts as the agent's fleeting working memory—limited but critical for immediate tasks.
The context window acts as the agent's fleeting working memory—limited but critical for immediate tasks.
Architecting Recall: Short-Term vs. Long-Term Memory
Since LLMs lack innate memory, it must be deliberately engineered:
- Short-Term (Working) Memory: The context window itself. It holds system instructions, recent chat history, active tools, and immediate task data. It's fast, volatile, and rebuilt for every LLM call.
- Long-Term (Persistent) Memory: External storage (e.g., vector DBs) enabling recall across sessions. This is where true learning and personalization reside. Schmid breaks it further:
- Semantic: Facts & preferences ("User prefers Python")
- Episodic: Past events/interactions ("Last summary was too long")
- Procedural: Internalized task rules ("How to format reports")
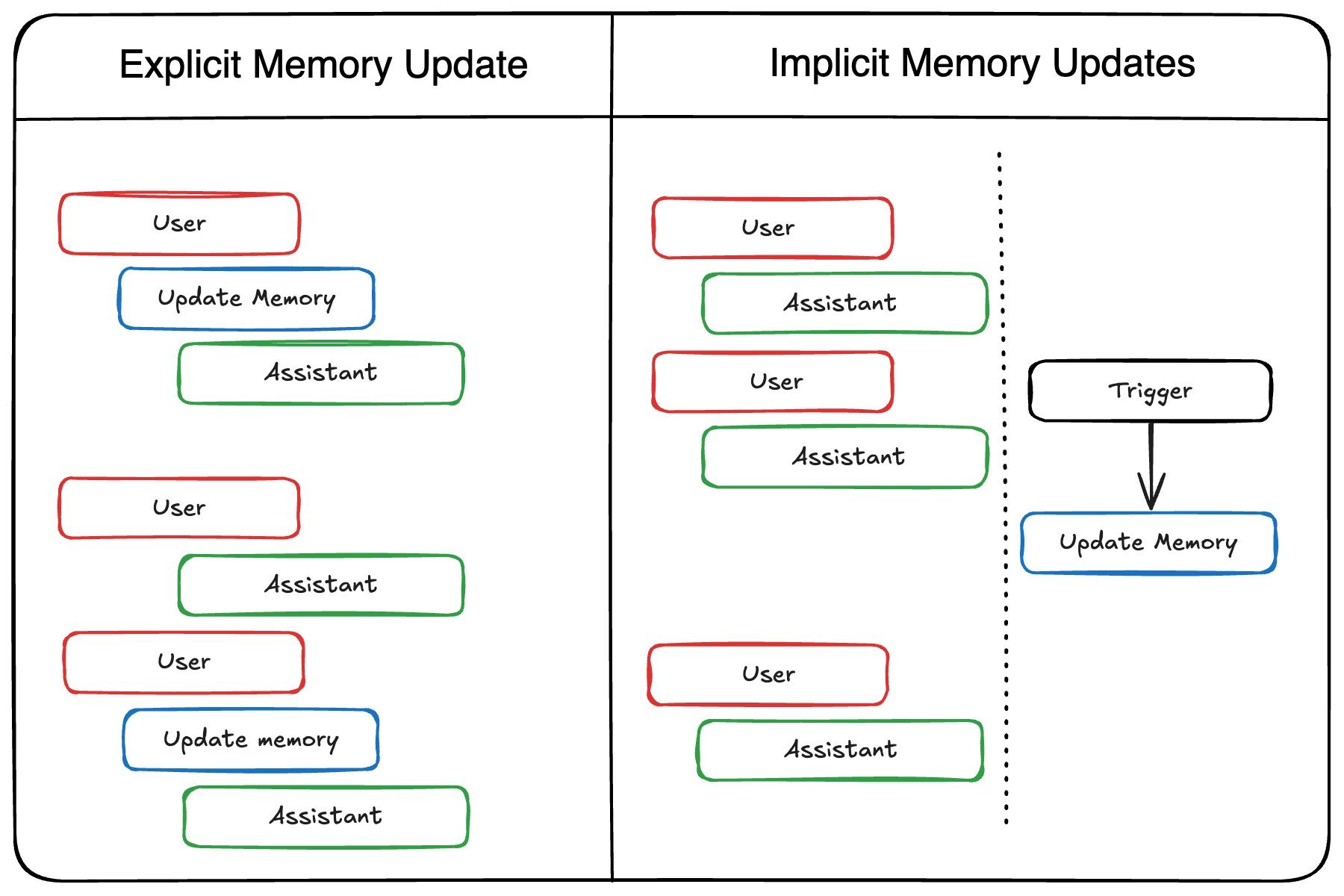
Updating Memory: Explicit vs. Implicit Strategies
How should agents write to memory?
| Strategy | Pros | Cons |
|---|---|---|
| Explicit (During interaction) | Real-time updates, transparent | Adds latency, complicates agent logic |
| Implicit (Background process) | No user delay, cleaner separation | Stale data risk, requires async design |
The Hard Problems: Relevance, Bloat, and Forgetting
Implementing memory isn't trivial. Key hurdles include:
- Relevance: Retrieving outdated or irrelevant memories pollutes the context, degrading performance.
- Bloat: Storing everything makes retrieval costly and ineffective—"remembering nothing useful."
- The Need to Forget: Information decays. Agents need eviction strategies to discard noise without losing critical context.
Worse, feedback loops are delayed. Flaws in memory design only surface after weeks or months, making iteration arduous.
Tools and the Path Forward
Frameworks like LangGraph, Mem0, Zep, and ADK are emerging to simplify memory integration. Schmid himself built a preference-remembering chatbot using Mem0 and Gemini 1.5 Flash. But as he argues, the future demands more than bigger databases:
"We will not just need bigger hard drives, but a smarter brain."
The real breakthrough lies in systems that intelligently manage what to remember, when to recall it, and crucially—what to let go.
Source analysis and concepts derived from Phil Schmid's research at philschmid.de, incorporating insights from Mem0, LangChain, and industry discourse.
Comments
Please log in or register to join the discussion