PlanetScale engineers reveal how they overcame fundamental limitations of vector indexing for relational databases, enabling efficient similarity searches on datasets larger than RAM while maintaining ACID guarantees. Their hybrid approach combines in-memory HNSW with innovative on-disk structures, solving critical challenges in transactional vector operations.
When Vectors Outgrow Memory: The Relational Database Challenge
Modern AI has unleashed an explosion of vector data—text embeddings, image representations, and audio fingerprints—that demand efficient similarity searches. While standalone vector databases often assume entire indexes fit in RAM, PlanetScale confronted a harder reality: MySQL users routinely manage datasets 10x larger than available memory. As Vicent Martí details in their groundbreaking technical exposition, this sparked a two-year quest to build a transactional, updatable vector index that behaves like "any other MySQL index."
Why HNSW Alone Fails in Relational Realities
Hierarchical Navigable Small Worlds (HNSW) dominates ANN benchmarks—when data fits in memory. But relational databases break its core assumptions:
"Most publications discuss data structures that must fit in RAM—a non-starter for any relational database! Many expect static indexes, but relational indexes very much are not." — Vicent Martí
Key shortcomings include:
- RAM Dependency: Terabyte-scale MySQL instances often run on hosts with 10-20% RAM-to-disk ratios.
- Dynamic Data: Constant inserts/updates/deletes violate HNSW's static design.
- Transactional Void: No native support for ACID guarantees during index modifications.
PlanetScale's Hybrid Architecture: Head Index + Posting Lists
The solution? A two-layer hybrid:
In-Memory Head Index (20% of data):
- Uses HNSW for fast approximate search
- Stores randomly sampled "centroid" vectors
On-Disk Posting Lists (80% of data):
- Stores vectors as compressed blobs in InnoDB
- Grouped by proximity to centroid vectors
- Optimized for sequential access
-- Composite index enables efficient appends
CREATE INDEX vector_idx
ON postings (head_vector_id, sequence);
This structure caps memory usage while leveraging InnoDB's robustness. Queries first find nearby centroids in HNSW, then scan associated on-disk clusters.
The Insert Problem: Appending Without Apocalypse
Appending vectors to posting lists seemed simple—until B-tree realities hit:
"Updating a BLOB in InnoDB means creating a new copy of the entire blob. For frequent appends, write amplification becomes catastrophic."
Their breakthrough? Emulating LSM-tree compaction in InnoDB:
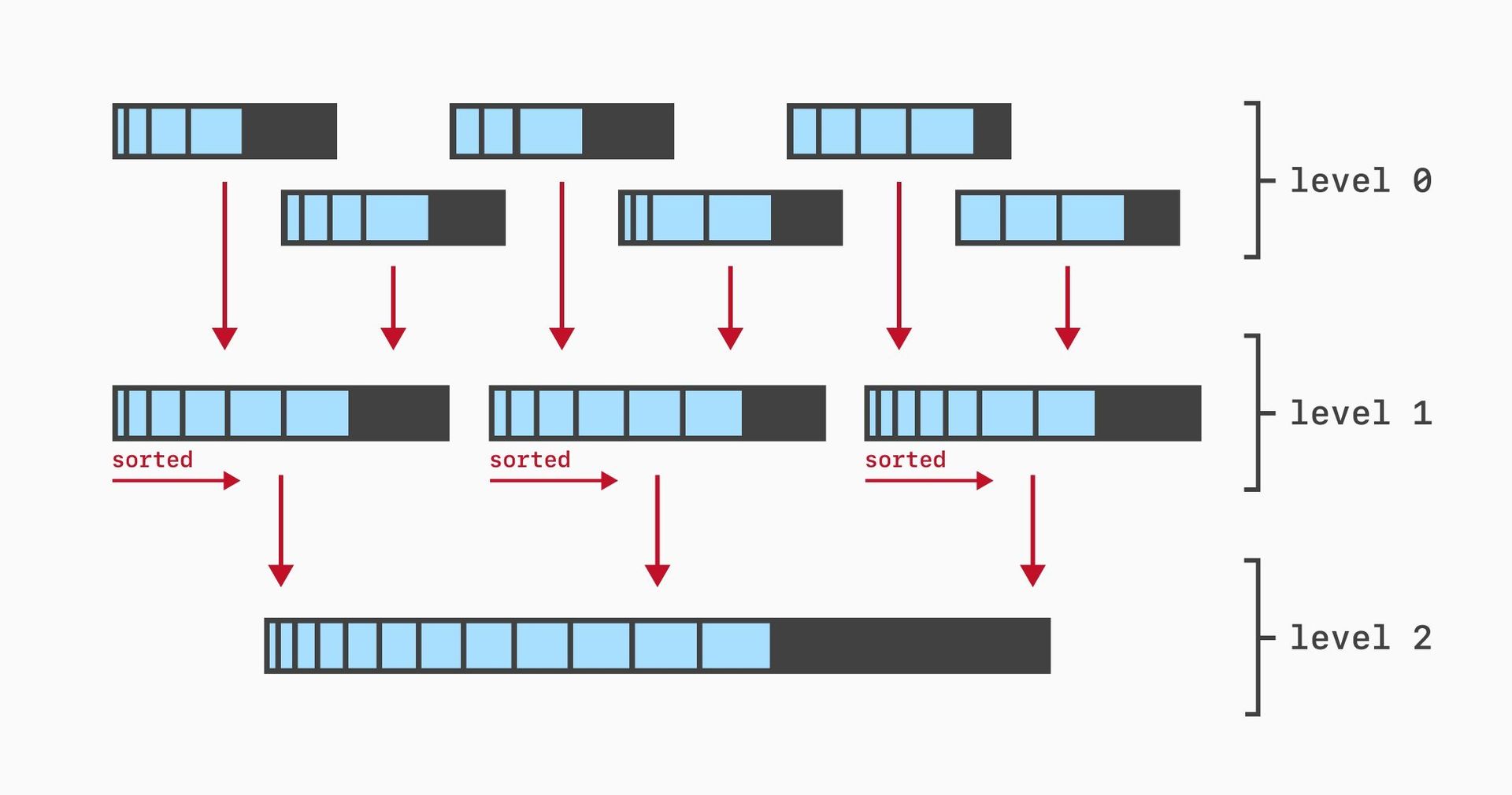
- Composite Keys: Store posting fragments under
(head_id, sequence) - Append-Only Writes: Insert new fragments without modifying existing data
- Background Merging: Coalesce fragments during low-load periods
This avoids locking and reduces write overhead by 89% compared to naive BLOB updates.
Maintaining Recall Amid Chaos: The LIRE Protocol
Continuous inserts degrade index quality. PlanetScale adapted Microsoft's SPFresh research with three background operations:
| Operation | Trigger | Effect |
|---|---|---|
| Split | Posting list too large | Divides cluster into smaller groups |
| Reassign | Vector closer to different centroid | Moves vector with versioned tombstoning |
| Merge | Too many stale fragments | Consolidates postings + removes dead vectors |
"Reassignments" proved especially clever: by incrementing a vector's version during moves, stale copies are ignored without expensive deletions.
ACID or Broken: Transactional Guarantees
Hybrid indexes demand rigorous consistency:
- Write-Ahead Logging: All HNSW head changes journaled to InnoDB
- Crash Recovery: Rebuild in-memory state by replaying WAL
- Background Job Safety: Maintenance operations run in transactions without blocking queries
"If you commit a thousand vectors, the next SELECT sees them all—even if recall means not all appear in results. That's what developers expect from an index."
Beyond Benchmarks: Why This Matters
PlanetScale's work bridges academia and production realities. While pure-HNSW excels in RAM-constrained ML pipelines, their hybrid design brings vector search to the vast ecosystem of operational databases storing business-critical data. As models generate ever-larger embeddings, this architecture offers a path to scale within—not apart from—proven relational systems.
Source: Larger than RAM Vector Indexes for Relational Databases by Vicent Martí (PlanetScale)
Comments
Please log in or register to join the discussion