
Outerbounds introduces workload-aware autonomous inference, outperforming traditional LLM APIs like AWS Bedrock and Together.AI in speed and cost-efficiency for large-scale tasks. Benchmarks reveal 7x faster completion times and superior cost-performance for dense models and massive contexts, signaling a paradigm shift for AI agents and batch processing.
As AI systems evolve beyond interactive chatbots to autonomous agents processing terabytes of data, traditional LLM inference APIs are hitting fundamental limitations. Outerbounds' new workload-aware inference approach—co-locating models with schedulers and dedicated compute—shatters the status quo for non-interactive workloads. Here’s why this matters for engineers building the next generation of AI applications.
The Autonomous Inference Gap
Most LLM APIs (OpenAI, AWS Bedrock, Together.AI) optimize for real-time dialogue: low latency, small token volumes. But autonomous use cases—analyzing 10 years of SEC filings or cross-referencing research papers—demand different metrics: total task completion time and cost-per-million-tokens at scale. Traditional "batch" APIs fall short, offering only 24-hour turnaround with 50% discounts, lacking optimization for throughput.
 The shift from human-in-the-loop to autonomous inference requires fundamentally different infrastructure.
The shift from human-in-the-loop to autonomous inference requires fundamentally different infrastructure.
How Workload-Aware Inference Wins
Outerbounds’ solution combines two core components:
- Intelligent Scheduler: Dynamically provisions resources based on prompt volume and model requirements
- Dedicated Compute Pools: Leverages Nebius’ on-demand H100 GPUs, avoiding noisy-neighbor throttling
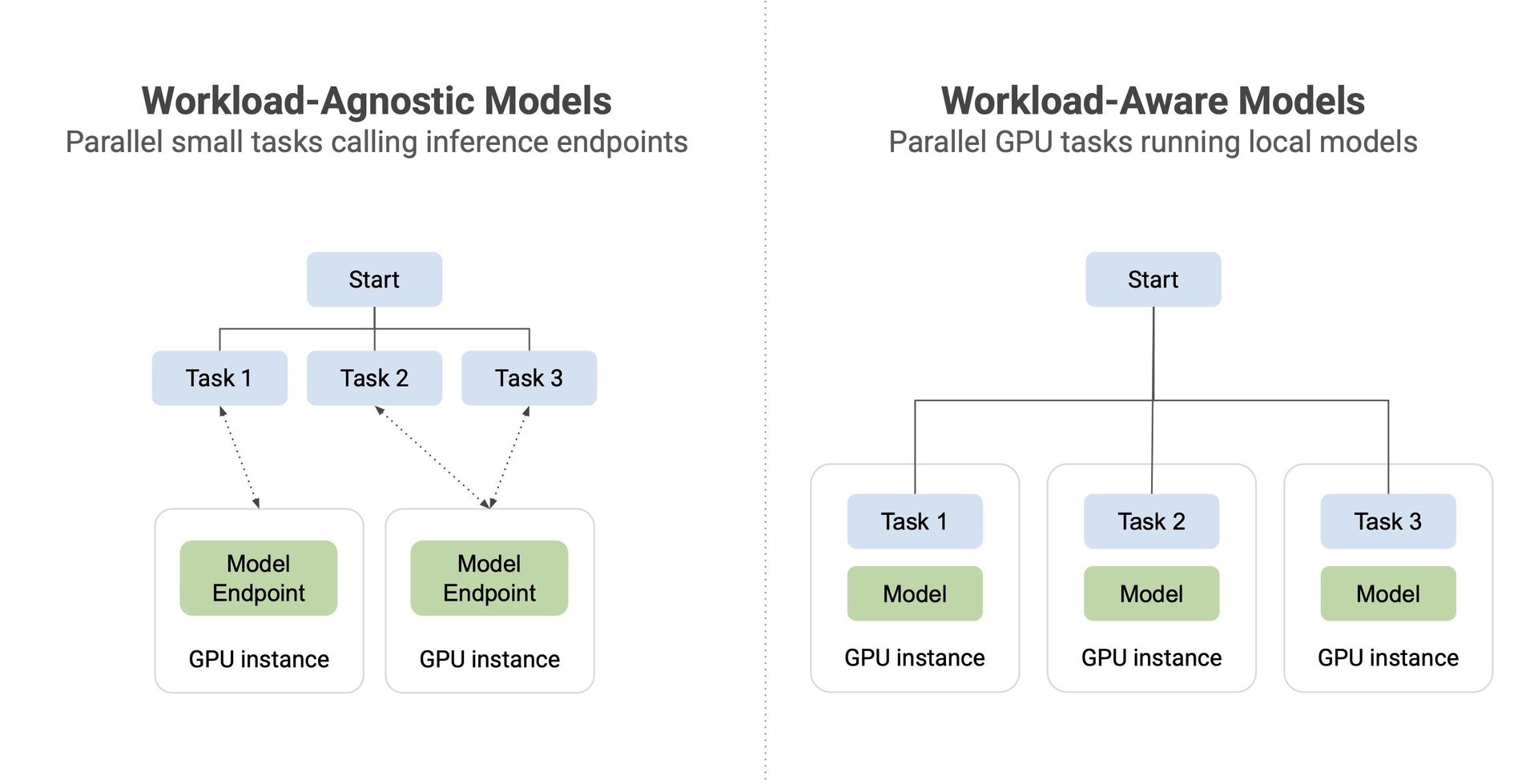 Workload-aware vs. workload-agnostic architecture. Co-location enables optimizations impossible in decoupled systems.
Workload-aware vs. workload-agnostic architecture. Co-location enables optimizations impossible in decoupled systems.
This architecture enables:
- Predictable scaling: Pre-provisioned resources eliminate rate limits
- Faster iteration: Sub-minute instance teardown post-task
- Cost control: Pay only for precise GPU-seconds used
Benchmark Breakdown: Shattering Myths
Testing across three critical scenarios reveals striking advantages:
1. Small Models (Llama 3.1 8B / Qwen3 4B) For trivial tasks (1k prompts, 1-word outputs), AWS Bedrock excels—but Outerbounds achieves 21ms p90 latency, enabling billions of prompts at scale.
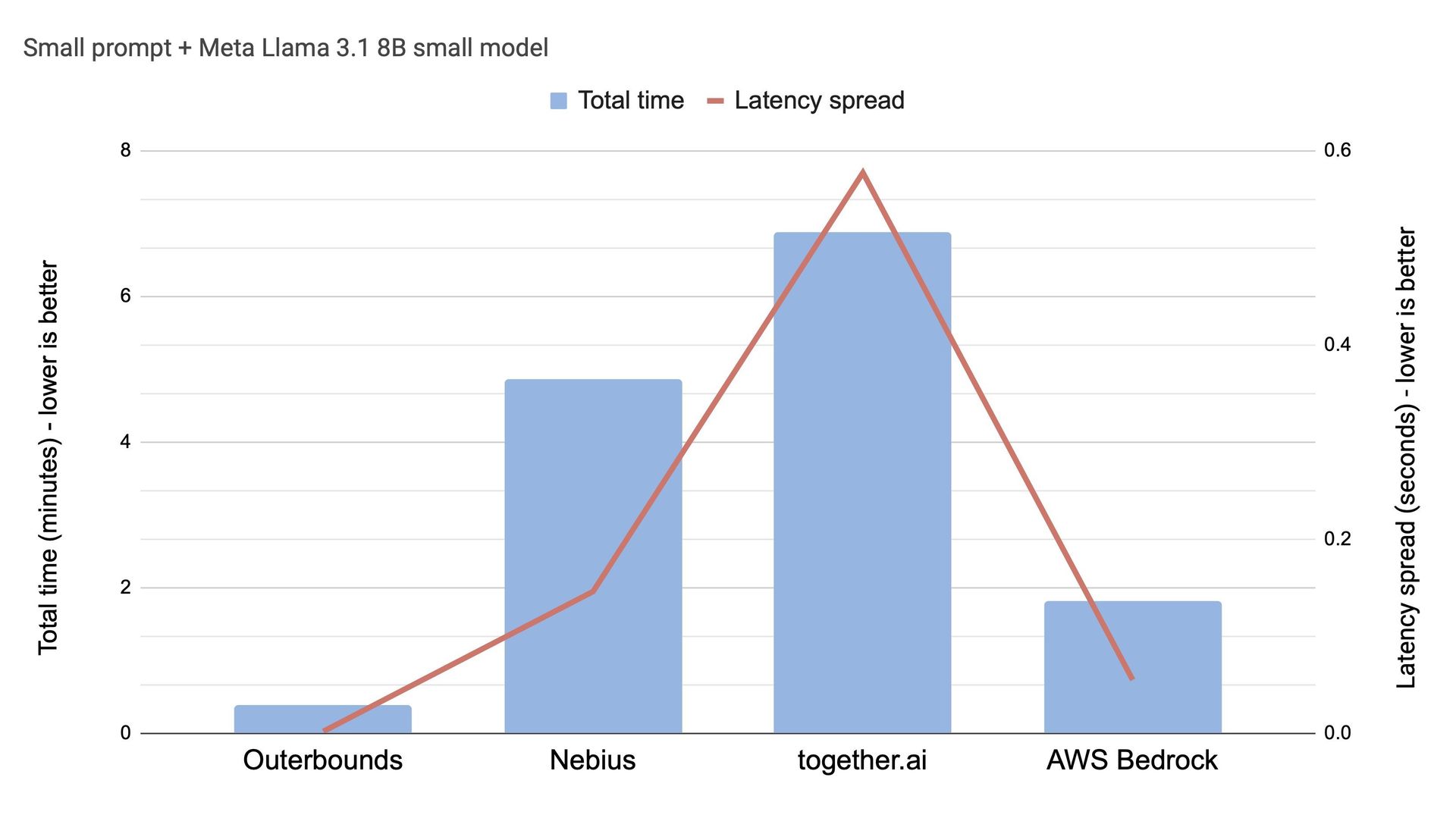 AWS dominates small tasks, but Outerbounds’ consistency enables massive parallelism.
AWS dominates small tasks, but Outerbounds’ consistency enables massive parallelism.
2. Dense Models + Heavy Context (Qwen 2.5 72B) Hyperscalers crumble. AWS Bedrock’s recommended g5.12xlarge instance proved "abysmal" for summarization tasks with 1k-token inputs. Meanwhile:
| Provider | Total Cost | Completion Time |
|------------------|------------|-----------------|
| Together.AI | $22.20 | 117 minutes |
| Outerbounds | $22.80 | 15 minutes |
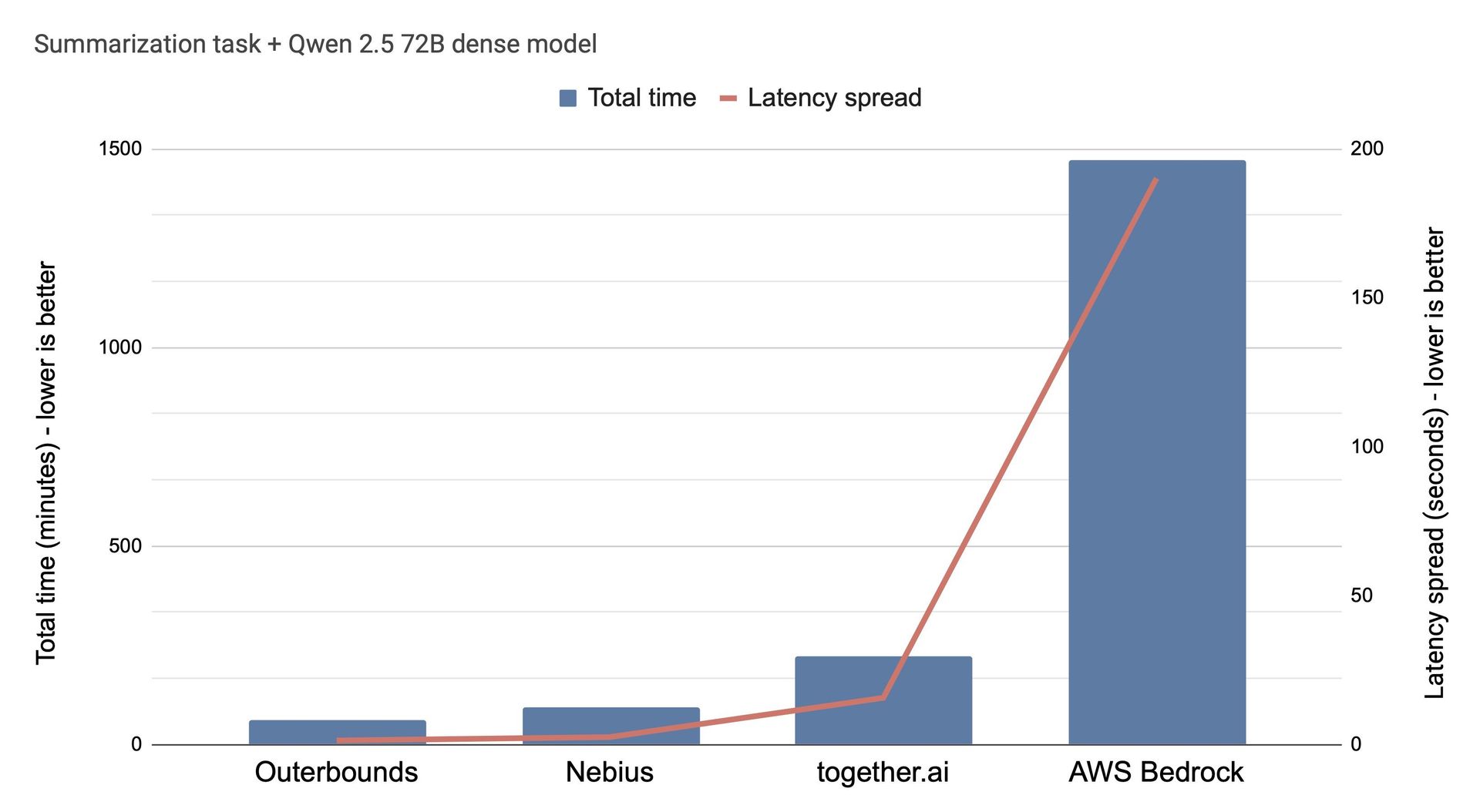 7x faster completion at cost parity—with larger workloads favoring Outerbounds further.
7x faster completion at cost parity—with larger workloads favoring Outerbounds further.
3. Agentic Workloads (Qwen QwQ 32B) For stateful agents processing 20k-token contexts, Outerbounds delivered:
- 2x speedup over Nebius AI Studio
- 50% lower latency spread than Together.AI
Why This Rewrites the Rulebook
- Cost Myth Busted: Dedicated H100s can outperform shared infrastructure on $/token for large workloads
- Statefulness Matters: Systems with massive context windows gain most from co-location (2-7x speedups)
- Predictability > Average Speed: p90-p10 latency spreads under 100ms enable reliable agent choreography
The New Calculus for Inference
While real-time APIs still rule chat UIs, autonomous workloads demand a new approach. As LLMs power increasingly complex agentic systems, Outerbounds’ workload-aware model proves that sometimes, the most efficient path forward is ditching one-size-fits-all solutions—and taking control of your compute.
Comments
Please log in or register to join the discussion