
Parallel has raised a $100M Series A to build what may become the missing substrate for production-grade AI agents: web-native infrastructure that can monitor, fetch, and act reliably across dynamic online systems. For developers, this signals a shift from brittle scraping and ad-hoc orchestration toward treating the web itself as a programmable, observable platform.
 )
)
The Web Wasn’t Built for Agents — Parallel Wants to Fix That
When people talk about AI agents, they usually fixate on reasoning: better planners, sharper tool use, more capable foundation models. What quietly breaks in production is everything else: authentication flows that change overnight, HTML that mutates on a whim, undocumented APIs, rate limits, inconsistent responses, and zero observability once an agent leaves your sandbox and touches the live web.
Parallel’s $100M Series A is a wager that this failure mode is not a side issue—it’s the defining infrastructure problem of the agent era.
The company is building web infrastructure for agents: a layer that standardizes how AI systems read, monitor, and interact with web properties so developers don’t have to duct-tape scrapers, fragile parsers, and custom heuristics into something pretending to be reliable. If this works, agents stop behaving like hopeful bots clicking around the internet and start behaving like first-class distributed systems clients.
Source: Parallel Blog and Parallel Series A Announcement
From Scrapers to Substrate: What Parallel Is Actually Building
Today’s agent stacks often look sophisticated from the outside—LLMs, vector stores, tool routers—but the integration with the real world is primitive. Most systems:
- Screen-scrape web pages or shadow APIs.
- Depend on brittle CSS/XPath selectors.
- Fail silently when the DOM or UX shifts.
- Offer almost no production-grade monitoring, alerting, or SLAs.
Parallel is attacking this with a developer platform that abstracts the messy edges of the web. One of the core primitives highlighted in their materials is the Monitor API, positioned as an evolution of traditional information retrieval and site integration patterns.
Instead of periodically scraping a page and hoping your parser still works, a Monitor-style approach offers:
- Declarative targets – You describe what you care about (entities, prices, slots, statuses) rather than wiring DOM details directly into your code.
- Change-aware infrastructure – When a site changes structure, the platform adapts—using learned extractors, templates, or human-in-the-loop corrections at the platform level instead of every customer relearning the same site.
- Consistent schema & delivery – Data arrives in normalized formats with well-defined contracts so agents can reason deterministically on top.
- Observability & reliability – Metrics, logs, error traces, and alerts for web interactions; in essence, SRE-style tooling for agent/web behavior.
In other words: treat the open web like a cloud service with endpoints you can depend on, monitor, and scale against.
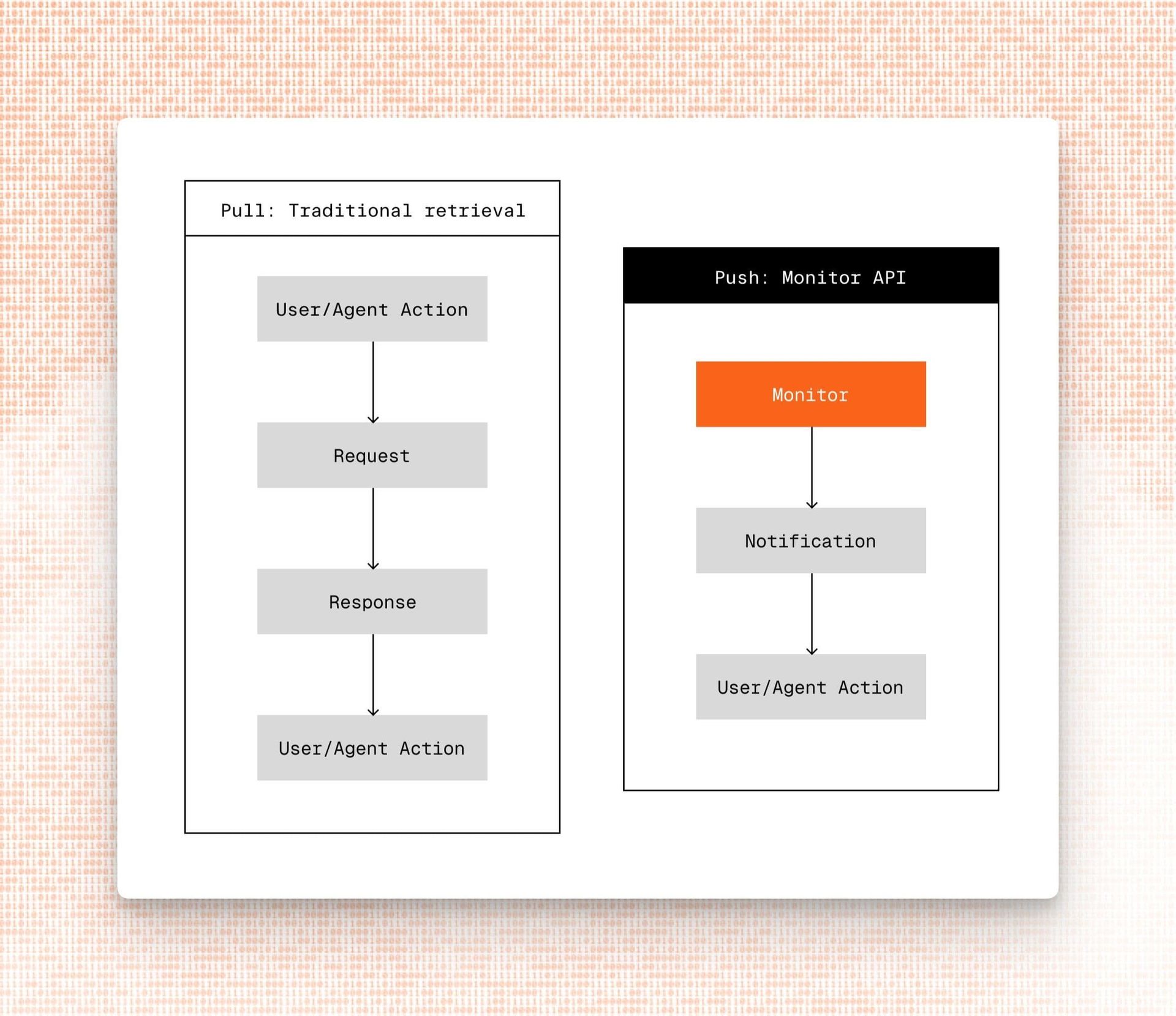
Traditional information retrieval pipelines were built for humans reading documents. Agent-native infrastructure is built for autonomous systems that must read, decide, and act — thousands or millions of times a day — without a human catching them when the HTML moves.
Why This Matters for Agent Builders
For teams building serious agent systems—travel planners, research copilots, procurement bots, pricing intelligence, marketplace automation—integration reliability is quickly becoming the hard problem.
Some key implications for developers and technical leaders:
1. Reliability as a First-Class Primitive
If your agents operate in production, MTTR for broken selectors is no longer acceptable. An infrastructure layer like Parallel’s promises:
- Centralized handling of layout and flow changes
- Contract-based data extraction instead of one-off scripts
- Reduced ops overhead on keeping agents alive on the shifting web
This is conceptually similar to moving from pets to cattle in infrastructure—only now your “pets” are custom scrapers and brittle adapters.
2. A Shift in How We Architect Agent Stacks
With a stable substrate for web interactions, architecture patterns change:
- Clean separation of concerns: LLMs focus on reasoning and decision-making; the web infra layer handles extraction, navigation, and monitoring.
- Composable capabilities: Teams plug in monitoring and retrieval as services, not as hard-coded workflows.
- Multi-tenant learning: Fixing one site benefits all customers; the platform accumulates operational knowledge of the web.
For platform engineers, this looks less like a one-off integration problem and more like adopting an NPM-for-the-web or a Stripe-for-website-interactions.
3. Security, Compliance, and Governance Aren’t Optional
Any serious agent infra must respect robots.txt, ToS, auth flows, and data boundaries. Centralizing this logic:
- Standardizes how agents authenticate and access resources.
- Makes it easier to audit what an agent did, where, and with which credentials.
- Reduces the likelihood that 20 internal teams each reinvent risky, invisible scraping systems.
This is especially relevant for enterprises that want agents interacting with vendors, partners, or third-party platforms without exposing themselves to untracked automation.
Reading the Signal Behind the $100M
A $100M Series A for a web infra startup is not about incremental convenience tooling; it’s a signal that investors and customers are aligning around a future where agents are:
- Persistent: running continuously, not just invoked per prompt.
- Operational: touching production systems, inventory, calendars, tickets, money.
- Accountable: expected to be observable, testable, and governable.
In that world, fragile integrations are an existential risk. Whoever solves “the web as infrastructure” for agents becomes a foundational dependency of the AI stack—akin to what Twilio did for communications and Stripe did for payments, but for knowledge, workflows, and state that live outside your API perimeter.
For engineering leaders, the strategic question is no longer "Can we hack an agent together with a browser automation library?" It’s "What’s our abstraction for the external world, and how do we make it reliable enough to bet revenue and brand on it?"
When Agents Stop Guessing

The history of infrastructure is the story of moving from best-effort hacks to hardened primitives: bare metal to cloud, SCP scripts to CI/CD, ad-hoc logs to observability platforms. AI agents are currently in their Bash-script era—clever, surprising, and absolutely not what you want owning critical workflows.
Parallel’s raise doesn’t guarantee they’ll be the one to standardize agent-native web infrastructure, but it reinforces a trajectory that technical teams should be planning for now:
- Treat web interaction as a product surface with SLAs, not a side effect.
- Design agents assuming a dedicated substrate for monitoring, compliance, and schema-stable access to third-party systems.
- Expect your competitors to move once these primitives exist—they’ll build agents that don’t break every time the frontend team ships.
When agents stop guessing their way through the web and start operating on reliable infrastructure, the experiments end and the real platform wars begin.
Comments
Please log in or register to join the discussion