SigNoz engineers tackled a pervasive log query bottleneck by rethinking ClickHouse data organization, introducing a deterministic 'resource fingerprint' to group related logs. This schema change leveraged ClickHouse's sparse primary index to reduce block scanning from 99.5% to under 1%, dramatically lowering I/O and latency while remaining extensible across Kubernetes, AWS, and Docker environments. The optimization underscores how aligning storage with access patterns can yield transformative pe
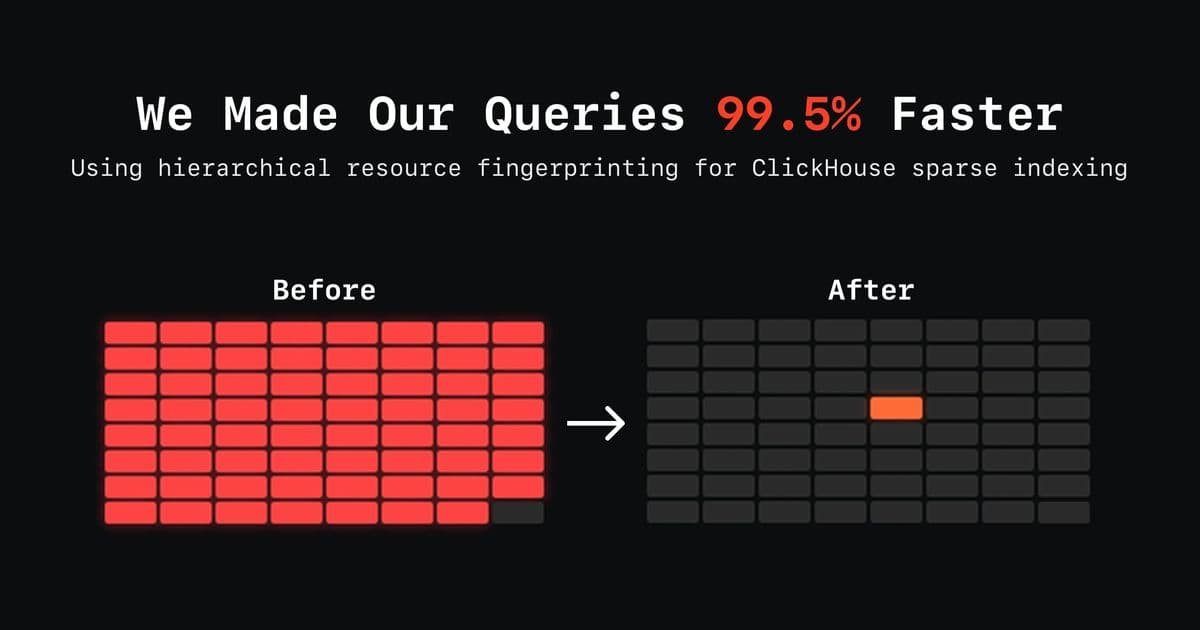
Log management platforms like SigNoz face a relentless challenge: efficiently querying vast volumes of scattered data. For teams filtering logs by Kubernetes namespaces or AWS environments, performance often crumbles under full-table scans. SigNoz engineers recently cracked this problem, slashing query I/O in ClickHouse from near-total data scans to a fraction of a percent. The secret? A clever reordering of data using hierarchical resource fingerprints—a change that exploits ClickHouse's core strengths while teaching a broader lesson in database optimization.
The Scattered Log Problem
When logs stream into systems like SigNoz from diverse sources—production pods, staging services, or development containers—they intermingle chaotically in storage. As described in SigNoz's implementation, a single ClickHouse data block could contain entries from multiple namespaces or environments. This fragmentation forced queries like namespace = 'production' to scan virtually all data blocks (41,498 out of 41,676, or 99.5%), as secondary bloom-filter indexes proved ineffective at skipping irrelevant granules. The result: crippling I/O overhead and latency, even for simple filters.
ClickHouse Mechanics: Granules and Sparse Indexes
Understanding SigNoz's fix requires a quick primer on ClickHouse's architecture. Data is stored in columnar format, grouped into blocks called granules (default 8,192 rows). The primary key, defined by the ORDER BY clause, physically sorts rows and creates a sparse index—storing one entry per granule, not per row. This allows ClickHouse to skip entire blocks if the primary key indicates they lack relevant data. As the SigNoz team noted:
"The key insight: if you can organize your data so the primary key naturally groups related records together, you get much better performance than relying on secondary indexes."
Secondary skip indexes (e.g., bloom filters) exist but are less efficient. When the primary key aligns with query patterns, the sparse index becomes a powerhouse.
The Breakthrough: Resource Fingerprinting
SigNoz's solution centered on deterministic "resource fingerprints"—hashes derived from hierarchical attributes like Kubernetes cluster, namespace, and pod, or AWS ec2.tag.env and cloudwatch.log.stream. For example:
cluster=c1;namespace=n1;pod=p1;hash=15482603570120227210
cluster=c1;namespace=n1;pod=p2;hash=15182603570120224210
ec2.tag.env=fn-prod;cloudwatch.log.stream=service1;hash=10649409385811604510
By adding resource_fingerprint to the primary key:
ORDER BY (
ts_bucket_start,
resource_fingerprint, -- Ensures contiguous storage
severity_text,
timestamp,
id
)
Logs from the same resource (e.g., a specific pod) now pack contiguously into granules. Queries filtering on attributes like namespace or pod can leverage the sparse index to skip blocks unrelated to the fingerprint, eliminating unnecessary I/O.
Quantifiable Performance Gains
Results from SigNoz's production deployment are stark:
- Before: A
namespacefilter scanned 41,498 out of 41,676 blocks (99.5%). - After: The same query scanned just 222 out of 26,135 blocks (0.85%).
ClickHouse's query execution plans reveal the shift:
- Previously:
Skip Index: bloom_filter (41498/41676 granules) - Now:
PrimaryKey: resource_fingerprint filter (222/26135 granules)
This translates to faster queries, reduced cloud costs, and scalability for high-cardinality environments—all while maintaining backward compatibility with existing schemas.
Why This Matters Beyond Log Management
SigNoz's approach highlights a universal principle: optimizing data layout for access patterns often trumps brute-force indexing. The fingerprinting technique adapts automatically to any resource hierarchy—Kubernetes, Docker, or cloud services—making it a versatile pattern for developers battling similar issues in analytical databases. It also reduces reliance on finicky secondary indexes, simplifying maintenance. As the team reflected:
"Sometimes the biggest wins come from understanding your data layout and optimizing storage accordingly."
For engineers, this case is a masterclass in leveraging database internals for order-of-magnitude improvements. It’s a reminder that in the race for faster queries, the smartest path might not involve new tools, but a smarter arrangement of what’s already there.
Source: SigNoz Blog
Comments
Please log in or register to join the discussion