A novel experiment reveals sending text as images to OpenAI's GPT-5 can reduce prompt tokens by 40%, but hidden trade-offs in completion tokens and latency make it impractical. This deep dive examines the data and why developers should prioritize efficiency elsewhere.
When OpenAI released multimodal capabilities allowing image inputs alongside text, developers noticed something curious: high-resolution images consumed surprisingly few tokens compared to their text equivalents. This sparked an intriguing hypothesis—could converting text prompts into images actually reduce API costs? An experiment by PageWatch put this theory to the test, with paradoxical results.
The Token Discrepancy That Sparked Curiosity
Traditional text prompts charge per token—roughly ¾ of a word. But when feeding images to models like GPT-5, token counts remain low despite massive file sizes. A 50x larger image might consume nearly the same tokens as its text counterpart. Why? OpenAI’s systems don’t process raw pixels. Instead, they use vision encoders to compress images into compact latent representations.
Testing the Hypothesis: Text vs. Image Prompts
The PageWatch team designed a controlled experiment using Andrej Karpathy’s blog post on digital hygiene as input data. They crafted two identical prompts asking GPT-5 to extract hygiene tips:
- Text version: Raw article text (~5,000 characters).
- Image version: Article text rendered into two 768x768 images (
 ), optimized for OCR clarity.
), optimized for OCR clarity.
Both prompts demanded identical structured outputs. Crucially, the image prompt specified "detail": "high" to preserve readability.
The Token Trade-Off: Prompt Savings vs. Completion Costs
Results revealed a stark split:
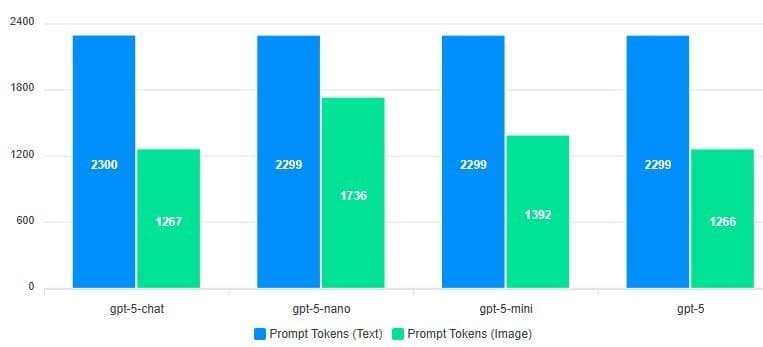
- Prompt tokens dropped dramatically: Using images slashed prompt tokens by 40% with GPT-5 (
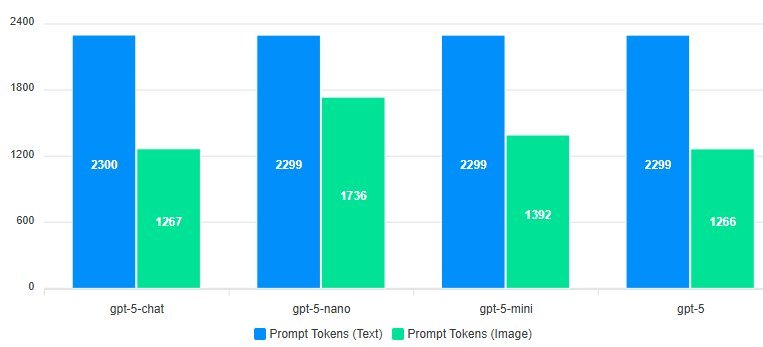 ). Vision encoders compressed visual data far more efficiently than tokenizing raw text.
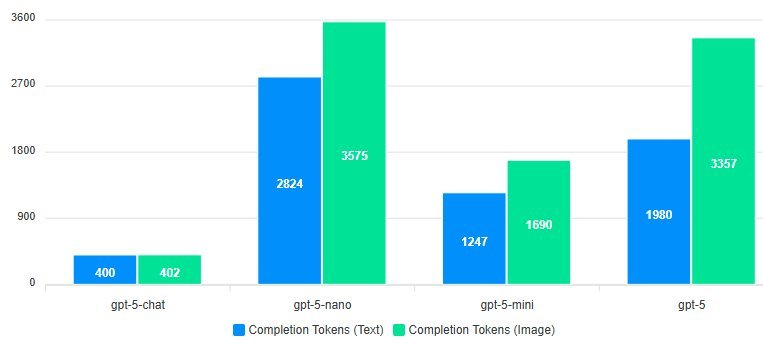
). Vision encoders compressed visual data far more efficiently than tokenizing raw text. - Completion tokens spiked: All models except GPT-5 generated 30-60% more completion tokens when responding to image inputs ({{IMAGE:3}}). Why? OCR errors introduced noise, and models worked harder to "translate" visual text back into structured outputs.
- Latency doubled: Image processing added significant delay, making responses slower.
Why This Isn’t a Cost-Cutting Hack
Despite prompt token savings, economics kill the idea:
- Completion tokens cost 2-3x more than prompt tokens in OpenAI’s pricing model. The increase in completion tokens erased any savings.
- Quality risks: Rendering text as images invites OCR inaccuracies, especially with complex layouts or fonts.
- Engineering overhead: Automating text-to-image conversion adds complexity versus direct API calls.
As the researchers concluded: “Unless you’re using GPT-5-chat specifically, the trade-offs aren’t worth it.” For most developers, optimizing prompt design or using compression techniques like LLMLingua offers safer ROI.
The Bigger Picture: Multimodal Efficiency Frontiers
This experiment highlights how vision-language models handle inputs in unintuitive ways. While not a practical shortcut, it underscores ongoing challenges in LLM cost predictability. As models evolve, expect tighter alignment between input modalities and token efficiency—but until then, stick to text.
Source: PageWatch AI
Comments
Please log in or register to join the discussion