Graph neural networks promise state-of-the-art performance on relational data—but naive sampling can quietly strangle both accuracy and throughput. Kumo’s adaptive metapath-aware graph sampling challenges the static GraphSAGE paradigm, reclaiming wasted budget and delivering up to 50% gains on key benchmarks. Here’s why this matters for anyone shipping GNNs into production.
 )
)
The Hidden Bottleneck of Industrial-Scale GNNs
Graph neural networks have become the go-to architecture for problems where relationships matter as much as entities: fraud rings, recommendation systems, protein interactions, supply chain risk, knowledge graphs. But the moment you try to move from a tidy academic dataset to a production graph with billions of nodes, you hit the wall: your graph does not fit.
Everybody solves this the same way: we sample.
GraphSAGE-style neighbor sampling—select a fixed number of neighbors at each hop, build a local subgraph, train on that—is the workhorse of scalable GNN training. It’s elegant, hardware-friendly, and widely supported.
It’s also fundamentally wasteful for real-world, heterogeneous, relational data.
Kumo’s latest work on adaptive metapath-aware graph sampling takes direct aim at this inefficiency. The core idea: instead of blindly sampling a static fanout at each hop, dynamically reallocate your sampling budget along semantically meaningful paths. In benchmarks, that seemingly small shift delivers consistent gains and up to a 50% relative boost in MAP@K on some Amazon tasks.
For teams building serious graph-native systems, this is not just an incremental tweak. It’s a blueprint for how GNN infrastructure needs to evolve.
Why Static GraphSAGE Sampling Breaks Down
At its heart, GraphSAGE does something intuitive:
- Start from a target node.
- At each hop, sample a fixed number of neighbors per edge type.
- Stack these into a computational graph and feed it to a GNN.
This works nicely in demos. But production graphs are:
- Heterogeneous (users, items, transactions, locations, reviews, etc.).
- Highly skewed (some users with 2 events, others with 20,000+).
- Semantically structured (some paths are far more predictive than others).
Static fanouts simply don’t respect that reality.
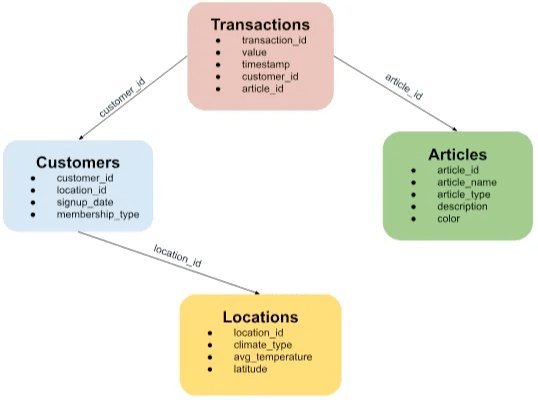
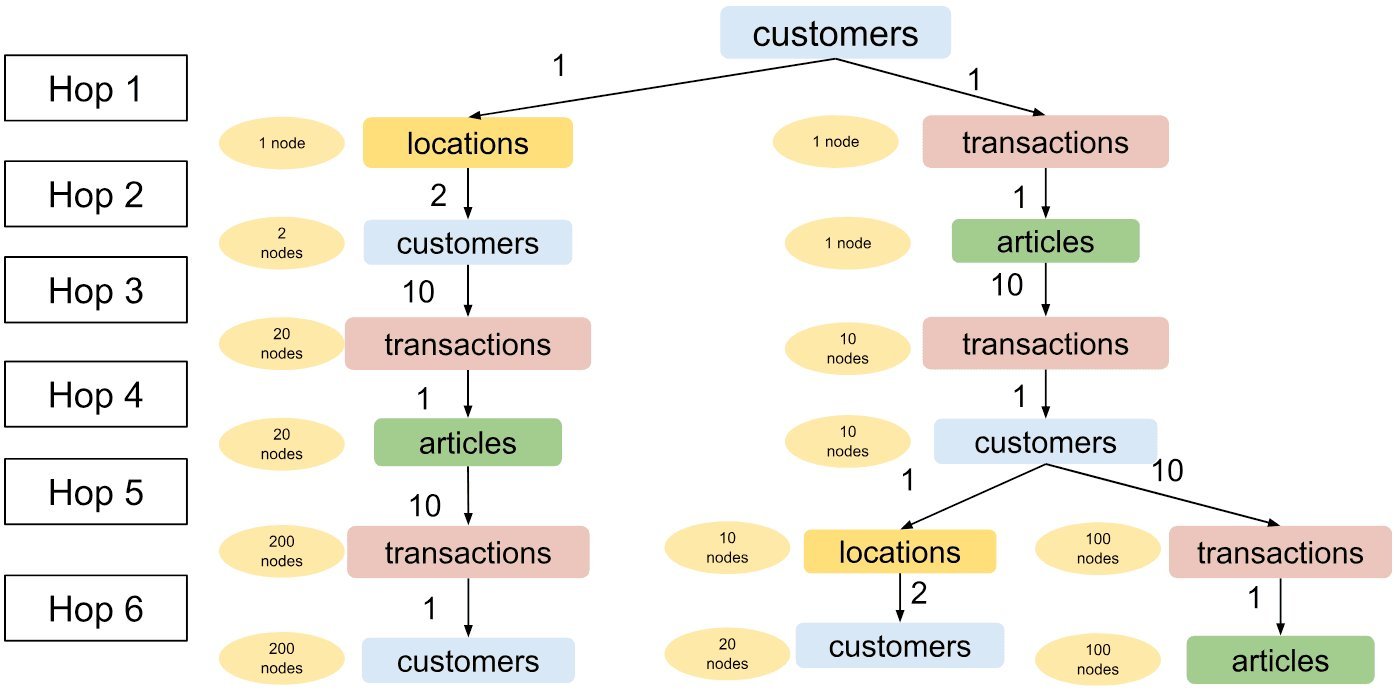
Consider a retail schema with customers, transactions, articles, and locations. You might start with a sensible GraphSAGE config:
num_neighbors:
- hop1:
customers.customer_id->transactions.customer_id: 10
customers.customer_id->locations.location_id: 1
hop2:
transactions.article_id->articles.article_id: 1
locations.location_id->customers.customer_id: 2
This builds a compact, relevant 2-hop neighborhood: recent transactions, linked articles, a few nearby customers.
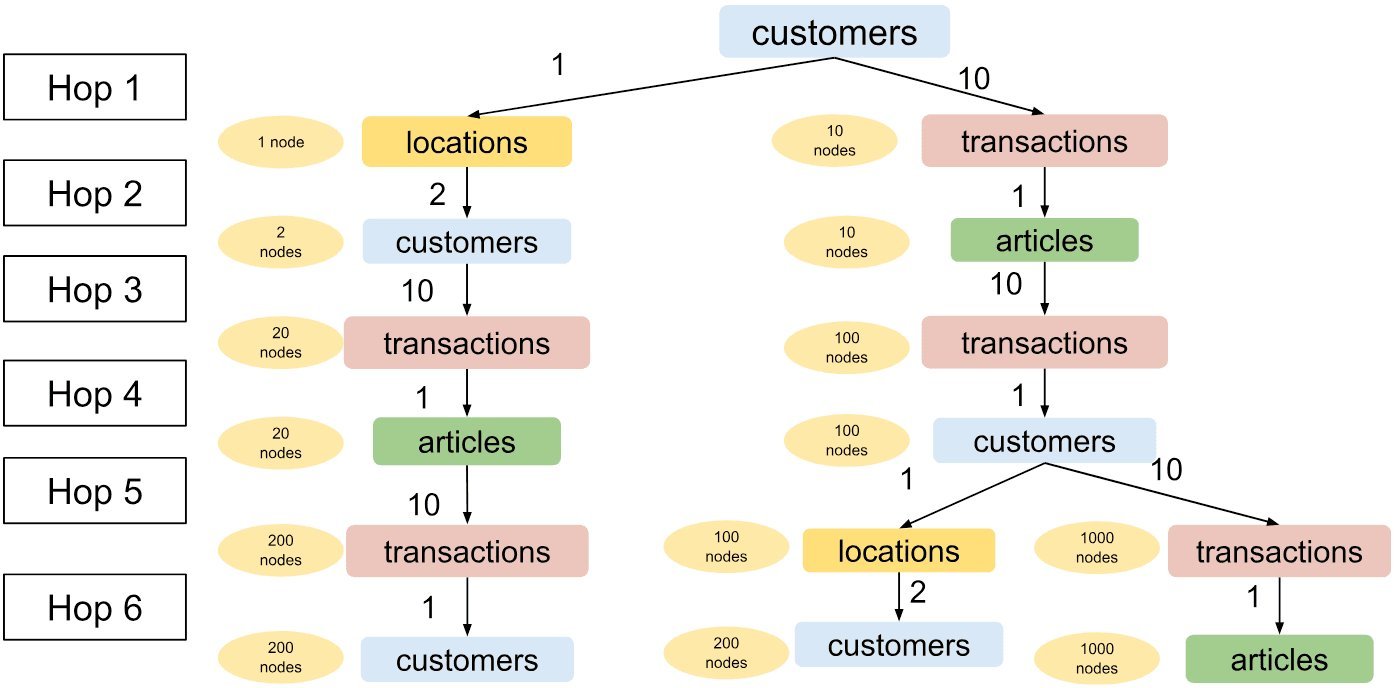
But as you enrich context with more hops—collaborative filtering signals, similar customers, co-purchased items—the fanout explodes. A carefully tuned 6-hop configuration, following simple rules (1 for FK→PK, 2 for weaker signals, 10 for strong PK→FK edges), can easily balloon towards ~3,000 nodes for a single seed.
You’re now living in the tension every GNN team knows:
- Too small: you underfit the relational structure.
- Too large: you blow up memory, batch size, or training time.
And even if you get the global config “right,” it’s wrong for most individual nodes.
The Real Problem: One Size Fits Nobody
The Kumo team surfaces two critical failure modes of static GraphSAGE sampling when applied to relational graphs like the H&M purchase dataset.
Users with very short histories
- If a user has only 1 past transaction and the config asks for 10, you only sample 1.
- Subsequent hops compound this under-sampling.
- The actual sampled subgraph ends up tiny and dominated by weaker signals (e.g., users from the same location) instead of rich behavioral context.
- Result: you waste sampling budget and bias the model towards less informative neighborhoods.
Users with very long histories
- If a user has thousands of transactions but you cap hop1 at 10, you’re discarding tons of high-quality signal.
- You impose an artificial bottleneck where the model never even sees most of the meaningful neighborhood.
The obvious patch—"if we undersample at hop k, oversample at hop k+1"—makes things worse. In the short-history case, compensating at the next hop often means over-sampling along the wrong edge types (e.g., spraying into location-based neighbors instead of purchase-history neighbors), amplifying noise instead of signal.
The diagnosis is blunt: GraphSAGE’s uniform, per-hop fanouts are not semantically aware.
What we actually care about isn’t just hops—it’s metapaths.
Introducing Adaptive Metapath-Aware Sampling
Metapaths are typed paths in a heterogeneous graph (e.g., customer → transaction → article → transaction → customer). For relational deep learning, these metapaths encode hypotheses: what kind of evidence should inform a prediction?
Kumo’s adaptive metapath-aware sampling pivots neighbor sampling around that idea:
- Treat the sampling configuration as a plan over metapaths, not just local degrees.
- When you fail to fill the planned budget at one step, you compensate along the same metapath (or its descendants), not arbitrarily.
In practice, the algorithm:
Detects under-sampling
- If a hop specifies N neighbors but only M < N exist, we record the deficit along that metapath.
Compensates along the same metapath
- First, oversample siblings consistent with that metapath. Example: if we lack 10-last-purchases for one article, we draw more from other articles the same user interacted with.
If that fails, backs off to children with the same path prefix
- For a user with just one transaction, the sampler shifts budget downstream: more neighbors from that transaction and its article, then their related users and transactions.
Critically, the sampler preserves the semantic intent of the original plan. It doesn’t just "use up budget"—it reallocates it to nodes that play the same structural role.
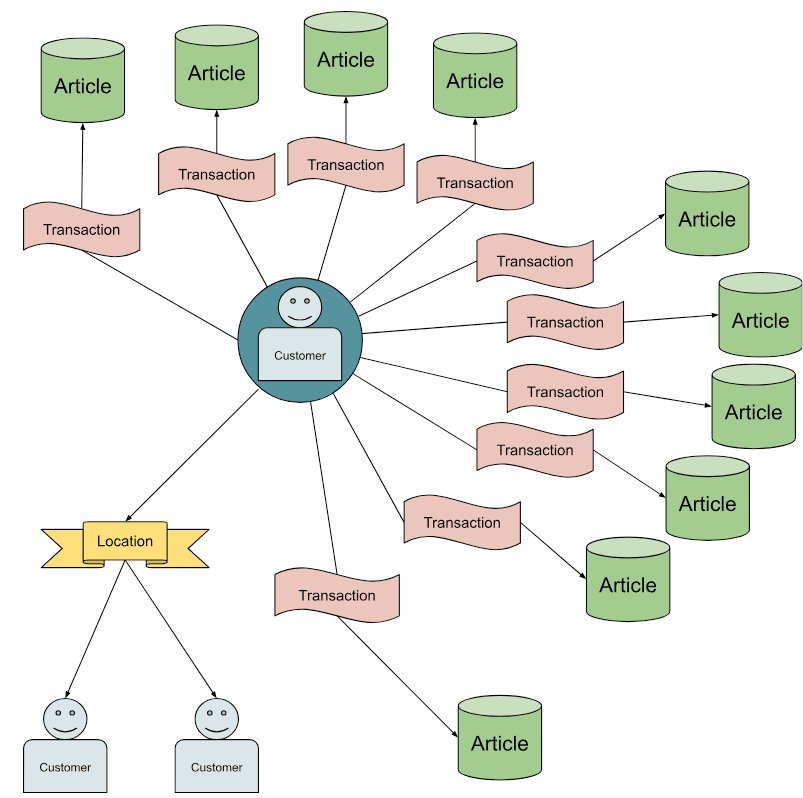
A Walkthrough: One Transaction, Smarter Sampling
Revisit the user with a single historical transaction.
The original GraphSAGE config expects 10 transactions; we get only 1. A naive fix would oversample users from the same location in later hops. Adaptive sampling does something more principled:
- It identifies that the missing mass is along a "purchase-history" metapath.
- It compensates by sampling many past buyers of the same item, then their related purchases.
- The resulting neighborhood maintains the intended balance: heavy on behaviorally similar customers, light on incidental geography.
This is exactly what recommenders and fraud models want.
Two Sparse Items, Still Coherent
In another scenario, a user has two purchased items (A, B), each with limited historical interactions. The sampler again cannot fully realize the intended early-hop fanout.
Instead of over-indexing on irrelevant edges, adaptive sampling scales up along each partial subtree: more transactions per relevant past customer, more neighbors where the schema and metapath match the original signal.
The effect is subtle but powerful: scarce data doesn’t force you into bad context.
Long Histories: From Constraint to Superpower
The same mechanism that rescues sparse users liberates dense ones.
Knowing that budget can be intelligently reallocated, Kumo simplifies the sampling config dramatically:
num_neighbors:
- hop1:
customers.customer_id->transactions.customer_id: 1000
customers.customer_id->locations.location_id: 200
hop2:
default: 1
hop3:
default: 1
hop4:
default: 1
hop5:
default: 1
hop6:
default: 1
Key points:
- Aggressively sample rich transactional context up front.
- Use adaptive logic to re-distribute when that fanout isn’t available (sparse users, rare items).
- Keep later hops tight (default: 1) to control combinatorial growth.
This turns GraphSAGE from a brittle global compromise into a dynamic per-node strategy—without changing your base GNN architecture.
The Numbers: Does This Actually Work?
Kumo evaluates the approach on the RelBench benchmark suite for relational deep learning, focusing on link prediction tasks that are especially sensitive to multi-hop structure.
Headlines:
- Consistent improvements across most tasks.
- Average relative improvement: ~19% in MAP@K.
- On Amazon user-item purchase prediction: up to 50% relative MAP@100 improvement.
A closer look at the H&M user-item purchase task (structurally similar to Kumo’s running example) is particularly telling:
- Performance lifts appear across almost all user segments.
- Gains are not limited to extreme sparsity or density buckets.
- Even users with ~10 past transactions—where fixed configs are "supposed" to be optimal—see improvements.
The implication: this isn’t just a clever hack for edge cases. It’s a more faithful way to translate relational schemas and business intuition into graph neighborhoods the model can actually exploit.
When You Should Not Use It
For all its benefits, adaptive metapath-aware sampling is not a universal default.
Kumo notes several boundaries where it likely won’t pay off:
Too few hops
- Adaptive behavior relies on at least two consecutive PK→FK-style expansions along a metapath (e.g.,
customer -> transaction -> article -> transaction). - If your model uses <3 hops, there’s often little room for smart reallocation.
- Adaptive behavior relies on at least two consecutive PK→FK-style expansions along a metapath (e.g.,
Tasks dominated by local features
- If most signal is in a single table (e.g., user features alone are strong predictors), dialing up sampling complexity mostly adds compute without accuracy gains.
Blindly increasing neighbor counts
- Adaptive sampling can make it tempting to "just increase budget" everywhere.
- Without profiling, you risk higher latency and cost for marginal or no improvement.
The important nuance for architects and MLEs: treat adaptive metapath-aware sampling as an instrument, not a switch. It shines where:
- You have rich, heterogeneous schemas.
- Target tasks benefit from multi-hop reasoning.
- Graph size and skew make fixed fanouts especially brittle.
Why This Matters for Builders of Graph-Native Systems
This work from Kumo is more than another sampling trick; it formalizes what many practitioners have been hacking toward in-house:
- That "neighbor sampling" is really about encoding hypotheses over metapaths.
- That static, global fanouts are misaligned with skewed, real-world distributions.
- That budgets should adapt per node, per structure, not per benchmark dataset.
If you’re:
- Designing large-scale recommenders on heterogeneous logs.
- Detecting fraud in transaction networks with heavy-tailed behaviors.
- Training foundation models over relational or event graphs.
…then this approach points to a practical pattern:
- Start with semantic metapaths that match your domain intuition.
- Use them to define a sampling plan, not just k-hop radii.
- Let an adaptive sampler enforce those intentions dynamically under real-world constraints.
Production GNNs are moving from “can we train this at all?” to “can we train this in a way that is faithful to the domain, efficient on hardware, and robust to skew?” Adaptive metapath-aware sampling is one of the first concrete, tested answers to that question—and it’s likely a precursor to a richer ecosystem of structure-aware graph compilers and samplers.
For once, better theory and better engineering point in the same direction.
Comments
Please log in or register to join the discussion