
AMD's Zen 5 architecture delivers impressive gains in productivity benchmarks but struggles to translate that dominance to gaming performance. A deep technical analysis reveals frontend bottlenecks, including instruction cache misses and branch prediction challenges, as the primary culprits—outshining even backend memory latency issues. This exposes the inherent trade-offs in modern CPU design when balancing peak throughput with real-world gaming demands.
AMD Zen 5's Gaming Dilemma: When Wider Isn't Always Faster

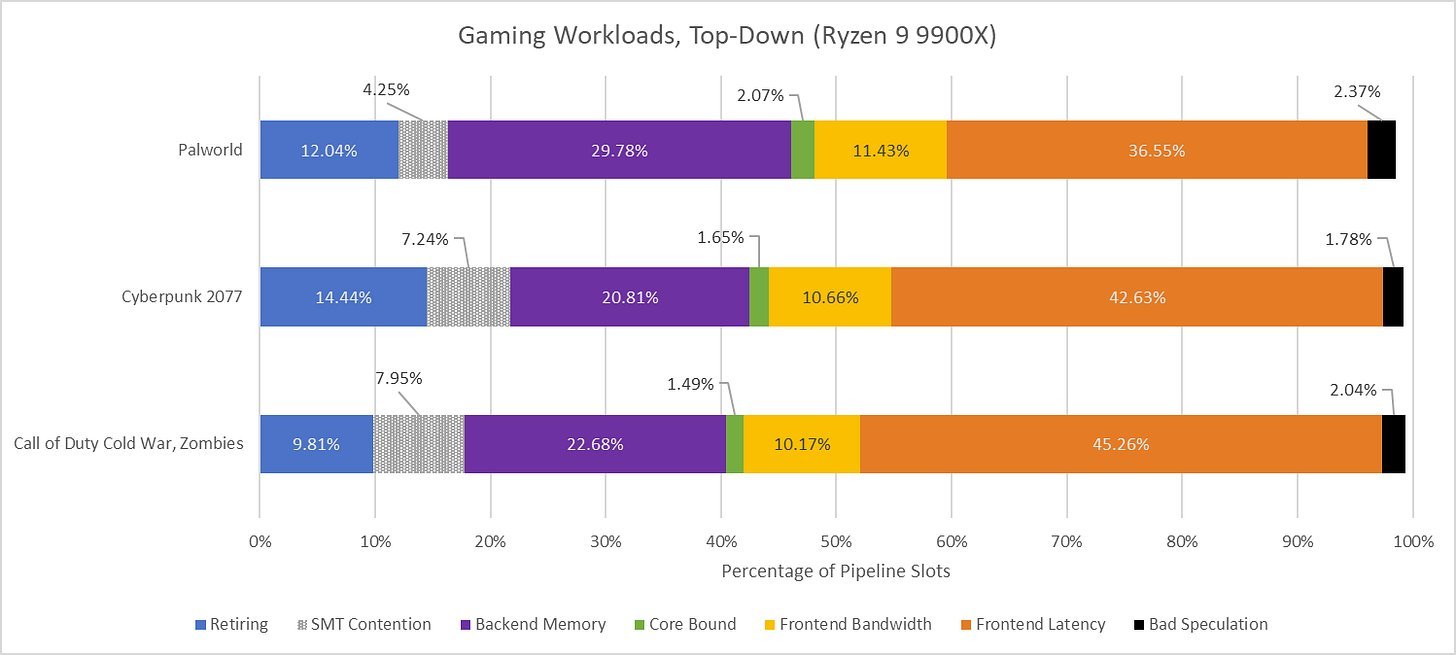
AMD's Zen 5 core architecture promised a leap forward with its wider execution engine, increased reordering capacity, and pipeline enhancements. Benchmarks like SPEC CPU2017 show clear wins, affirming Zen 5's prowess in productivity applications. Yet, as reviewers noted, non-X3D variants like the Ryzen 9 9900X often underwhelm in gaming—a puzzle explored in depth by Chester Lam at Chips and Cheese. Testing titles like Palworld, Call of Duty: Cold War, and Cyberpunk 2077 reveals that Zen 5's gains are hamstrung not by raw power, but by frontend latency, highlighting a critical challenge for CPU architects targeting diverse workloads.
Source: Chips and Cheese, Chester Lam, Aug 02, 2025.
The Frontend Bottleneck: Instruction Fetch Falls Short
Zen 5's frontend combines a 6K-entry op cache, a 32KB L1 instruction cache (L1i), and a massive 24K-entry branch target buffer (BTB) to predict and fetch instructions efficiently. But in gaming workloads, it stumbles. Performance monitoring shows 20–30 L1i misses per 1,000 instructions—higher than Intel's Lion Cove—with average fetch stalls lasting 11–12 cycles, closely aligning with L2 cache latency. This directly throttles the rename/allocate stage, leaving slots idle and core utilization low.
Branch prediction accuracy, while generally high, dips slightly compared to Lion Cove across all tested games, surprising given Zen 5's SPEC CPU2017 advantages. Mispredicts and frequent "decoder overrides" (similar to Intel's BAClears) exacerbate delays, forcing the frontend to wait for correct instruction paths. Even op cache throughput averages just 6 micro-ops/cycle—below the 8 needed to feed Zen 5's width—partly due to high branch frequency in game code.
Backend Struggles and Cache Trade-Offs
While frontend latency dominates, backend memory latency remains a factor. Zen 5's 448-entry reorder buffer (ROB) often fills, but resource stalls frequently trace to the integer register file. Load-related retirement blocks last 18–20 cycles on average, with L1 data cache misses showing higher latency in COD and Cyberpunk than in Palworld. Here, cache hierarchies reveal stark differences:
- L1d Miss Handling: Palworld sees more misses but benefits from Zen 5's low-latency 1MB L2, while Intel's larger 192KB L1.5d cache shines in reducing overall latency for that title.
- L3 Efficiency: Zen 5 serves 55–68% of demand loads from L3, with most misses going to DRAM. Cross-CCX accesses are rare (under 1% in normal gaming) and surprisingly performant—often matching or beating DRAM latency.
 AMD's own data illustrates the latency cost of cross-CCX cache refills, though real-world gaming rarely triggers this.
AMD's own data illustrates the latency cost of cross-CCX cache refills, though real-world gaming rarely triggers this.
Testing the Limits: Forcing Cross-CCX Traffic
To probe system topology impacts, Lam artificially split Cyberpunk 2077 across both CCX-es on the 9900X, disabling boost for consistency. This increased cross-CCX accesses significantly, reducing performance by 7% versus single-CCX pinning. While this highlights a potential scaling limit, it's an edge case—Windows scheduler typically confines games to the highest-clocked CCX, minimizing real-world penalties. Intel's hybrid architecture faces similar critiques, but Thread Director largely mitigates E-core inefficiencies in gaming, with deviations rarely exceeding 10%.
The Bigger Picture: Peak Throughput vs. Latency Tolerance
Zen 5 and Lion Cove both prioritize high-IPC workloads like SPEC's 538.imagick, where wider cores excel. Yet games, with their low IPC and poor locality, expose the diminishing returns of chasing peak throughput. Frontend improvements demand disproportionate investments in branch prediction and caching, while backend fixes require costly expansions of register files and queues. AMD's unchanged cache hierarchy from Zen 4—1MB L2s and shared L3—contrasts with Intel's larger L1i, suggesting a path forward: combine robust frontend caching (like Intel's) with AMD's low-latency backend for a gaming-optimized core.
As core counts climb, scalable designs like AMD's CCX-es and Intel's hybrid approach face scrutiny, but current data shows they're effective. The real bottleneck remains latency, not topology. For developers and hardware engineers, this analysis underscores a pivotal shift—optimizing for the "hard cases" in low-IPC workloads may yield broader gains than pushing high-IPC peaks further. In the race for gaming dominance, the CPU that best masks latency, not just multiplies ops, could define the next generation.
Comments
Please log in or register to join the discussion