Alibaba-owned AutoNavi has unveiled ABot-M0 and ABot-N0, embodied foundation models for robotic manipulation and navigation that achieved state-of-the-art results across 10 global benchmarks, including a 30-point lead on Libero-Plus and 40.5% improvement in social navigation.
AutoNavi, the Alibaba-owned mapping and navigation giant, has entered the embodied AI arena with the launch of its ABot series foundation models. The company unveiled ABot-M0 for robotic manipulation and ABot-N0 for navigation, claiming comprehensive state-of-the-art results across 10 leading global benchmarks. These models represent a significant push into robotics and autonomous systems, leveraging AutoNavi's extensive mapping data and AI expertise.
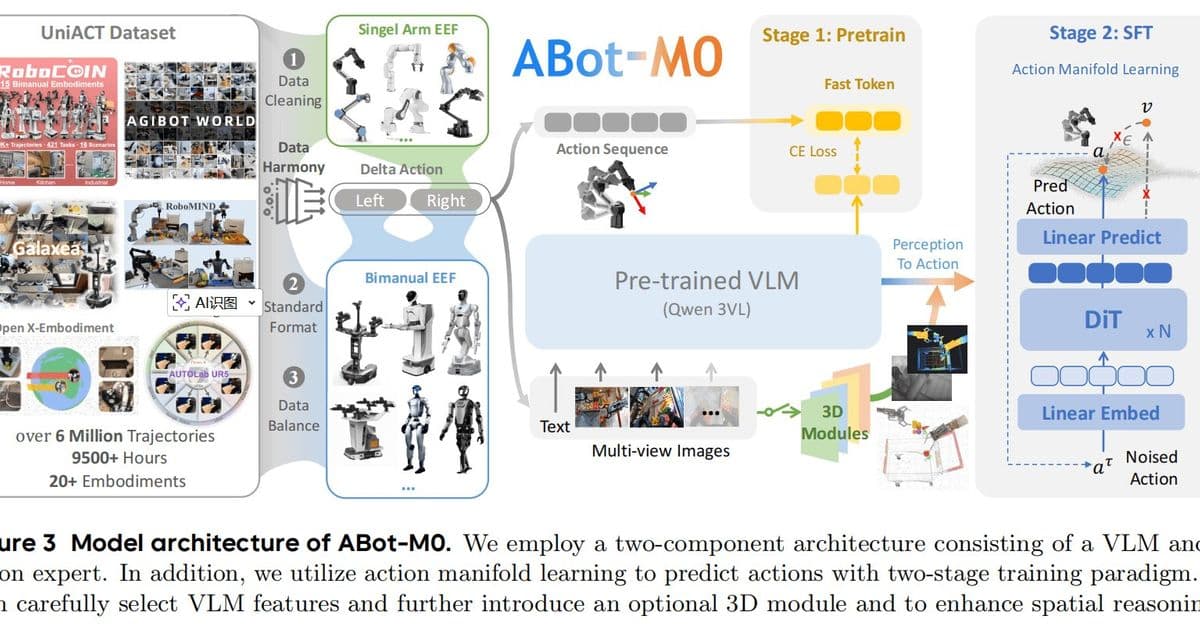
ABot-M0: A Unified Architecture for Robotic Manipulation
ABot-M0 is positioned as the world's first unified-architecture foundation model for robotic manipulation. The model addresses a fundamental challenge in robotics: the lack of standardization across different robotic platforms. By standardizing coordinate systems, control frequencies, and incremental motion modeling, ABot-M0 can integrate trajectory data from diverse robotic systems into a cohesive framework.
The training dataset is particularly noteworthy. Built entirely from public sources, it encompasses over 9,500 hours of training data, 6 million trajectories, and information spanning more than 20 different embodied forms. This breadth of data allows the model to generalize across various robotic platforms and manipulation tasks.
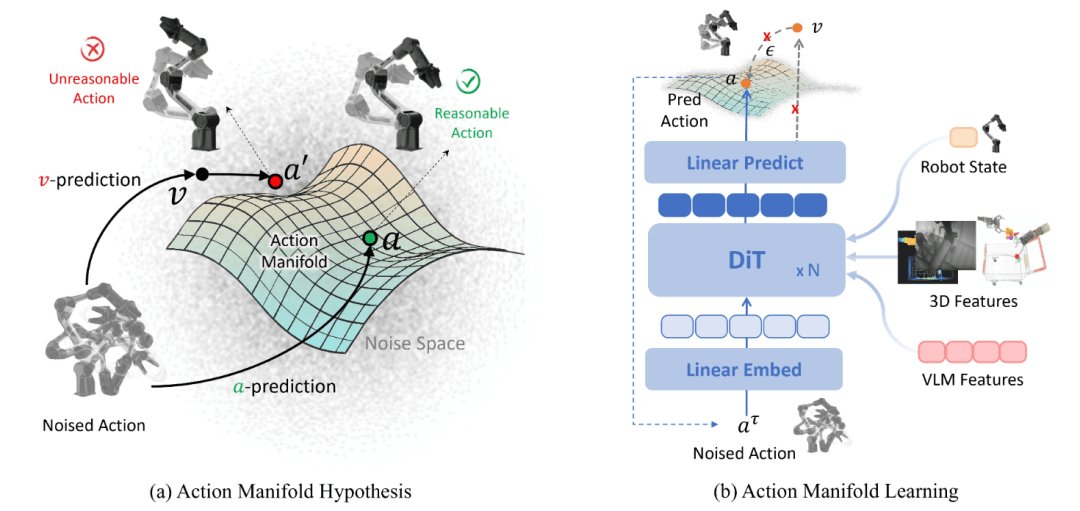
Algorithmically, the team introduced Action Manifold Learning (AML), a novel approach that enhances the model's ability to understand and execute complex manipulation tasks. The integration of 3D perception modules provides enhanced spatial semantic understanding, allowing the robot to better interpret its environment and plan appropriate actions.
On the Libero-Plus benchmark, which tests robotic manipulation capabilities, ABot-M0 achieved an 80.5% task success rate. This represents a nearly 30 percentage point improvement over the previous leading method, demonstrating the model's significant advancement in manipulation capabilities.
ABot-N0: The First VLA-Based Navigation Foundation Model
ABot-N0 takes a different approach, positioning itself as the first single Vision-Language-Action (VLA) based navigation foundation model to unify five core navigation tasks: point-to-point navigation, object navigation, instruction following, point-of-interest navigation, and pedestrian following. This unification represents a departure from traditional approaches that often require separate models for different navigation scenarios.
The model employs a hierarchical "brain–action" architecture. The cognition module, based on a pretrained large language model, handles semantic understanding and task decomposition. This allows the system to interpret complex instructions and break them down into actionable steps. The action experts then generate precise trajectories using flow matching techniques, translating high-level goals into specific movement commands.
AutoNavi constructed a navigation data engine featuring approximately 8,000 high-fidelity 3D scenes and nearly 17 million expert demonstrations. This massive dataset, combined with AutoNavi's mapping expertise, provides the foundation for the model's navigation capabilities.
Benchmark Performance and Real-World Deployment
ABot-N0 set new records across seven major benchmarks, including CityWalker, SocNav, R2R-CE/RxR-CE, and HM3D-OVON. The improvements are substantial: in SocNav closed-loop simulation, success rates improved by 40.5%, while object navigation success in HM3D-OVON rose by 8.8%. These results suggest the model can handle complex, real-world navigation scenarios more effectively than previous approaches.
Perhaps most significantly, AutoNavi reports that ABot-N0 has already been deployed on real-world quadruped robots. The company claims the model achieves efficient edge-device inference and closed-loop control, suggesting practical viability beyond benchmark performance. This real-world deployment capability is crucial for embodied AI systems, as theoretical performance often differs from practical effectiveness.
Context and Implications
The launch of ABot-M0 and ABot-N0 represents AutoNavi's strategic expansion beyond traditional mapping and navigation services. By leveraging its extensive mapping data and AI capabilities, the company is positioning itself in the growing embodied AI market. This move aligns with broader industry trends where companies with large-scale spatial data are increasingly venturing into robotics and autonomous systems.
The models' performance on multiple benchmarks demonstrates significant progress in embodied AI, particularly in unifying different tasks under single architectures. However, as with many AI announcements, independent verification of these benchmark results would be valuable for the research community.
AutoNavi's approach of building models from public data sources is noteworthy in an era where proprietary datasets often provide competitive advantages. The company's ability to achieve state-of-the-art results with publicly available data suggests that model architecture and training methodology may be as important as data exclusivity.
The deployment of ABot-N0 on quadruped robots also highlights the practical focus of these models. While many AI systems excel in simulation, the transition to real-world hardware often reveals limitations. AutoNavi's claims of efficient edge-device inference suggest the models are designed with practical deployment constraints in mind.
As embodied AI continues to advance, the unification of different capabilities under single models, as demonstrated by ABot-M0 and ABot-N0, may become increasingly important. The ability to handle multiple tasks without requiring separate specialized models could significantly reduce complexity and improve system integration in real-world applications.
Comments
Please log in or register to join the discussion