
Google DeepMind's groundbreaking paper formally proves embedding-based retrieval hits inherent combinatorial limitations at scale. The research demonstrates why single-vector architectures inevitably fail complex queries, forcing a paradigm shift toward hybrid and multi-vector approaches for production systems.

In a landmark paper published last week, Google DeepMind researchers have mathematically formalized what many engineers have empirically observed: single-vector embedding models cannot handle combinatorial retrieval tasks at scale. Titled "On the Theoretical Limitations of Embedding-Based Retrieval," the work provides rigorous proof that the fundamental architecture underpinning most modern retrieval systems—including RAG implementations—contains unavoidable capacity constraints.
The timing is striking, arriving alongside Google's release of its state-of-the-art Gemma embedding models. This juxtaposition highlights the industry's tension between advancing core technology and confronting its theoretical ceilings.
The Combinatorial Ceiling
The paper shifts focus from semantic understanding to geometric limitations: A d-dimensional vector cannot partition document space to satisfy all possible combinations of k items from n documents. The researchers frame retrieval as a low-rank matrix factorization problem, proving that the required embedding dimension (d) is bounded by the sign rank (rank_±) of the relevance matrix:
rank_±(M) - 1 ≤ d_required ≤ rank_±(M)
This establishes sign rank as the mathematical proxy for combinatorial complexity. The -1 term isn't incidental—it emerges from the proof as the rank-1 matrix threshold needed to map retrieval solutions.
Empirical Validation: Breaking Points Revealed
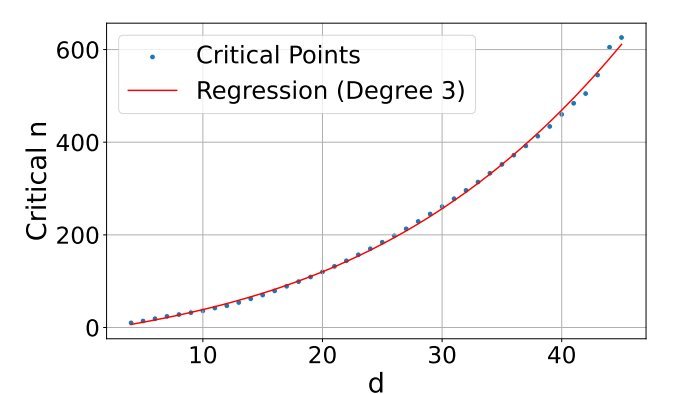
The team created an adversarial "free embedding optimization" test, removing language models to isolate vector capacity. By optimizing document vectors to retrieve all possible k=2 combinations, they identified critical failure points:
- d=512 models (e.g., small BERT): Fail at ~500k documents
- d=1024 models (common production size): Fail at ~4M documents
- d=4096 models (largest available): Fail at ~250M documents
While extrapolation debates exist, the polynomial (not exponential) scaling relationship remains undeniable. As corpora grow, single-vector systems will break.
The LIMIT Dataset: Mirroring Real-World Pain
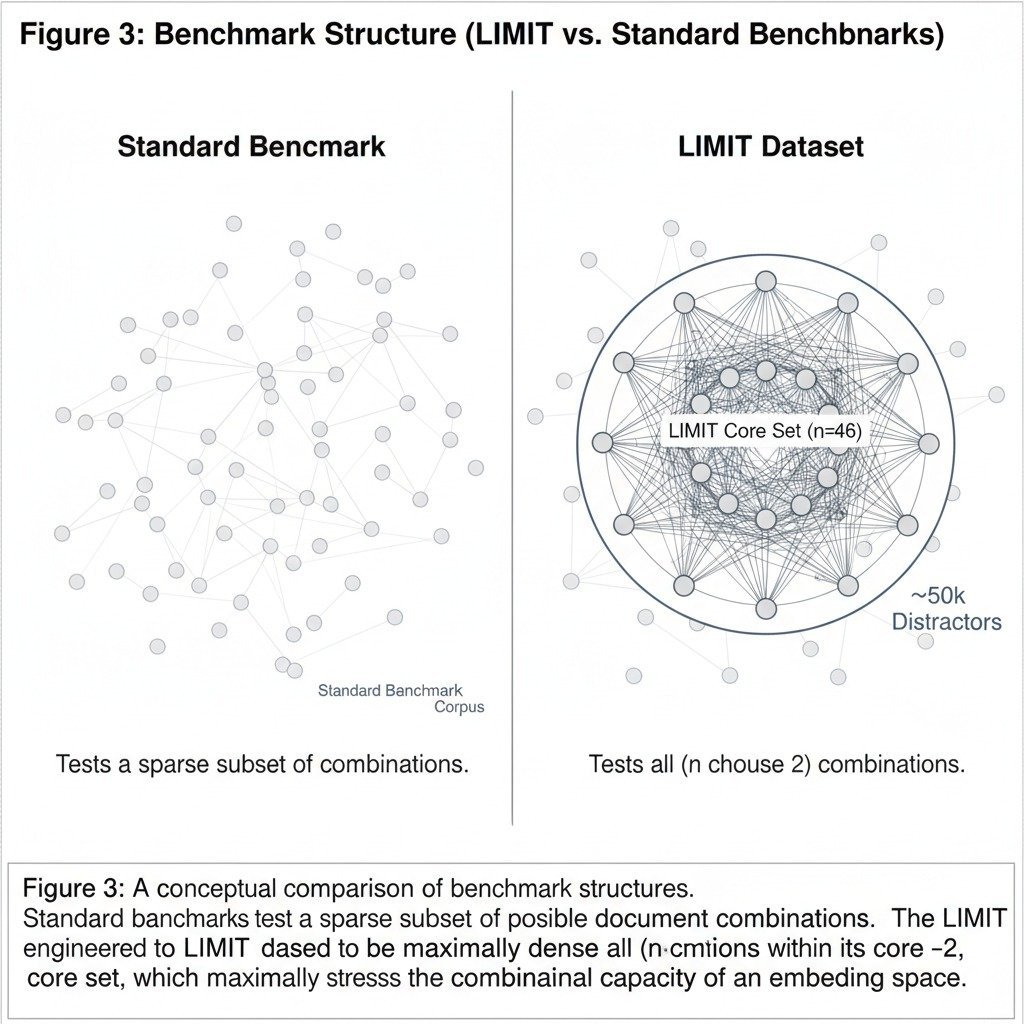
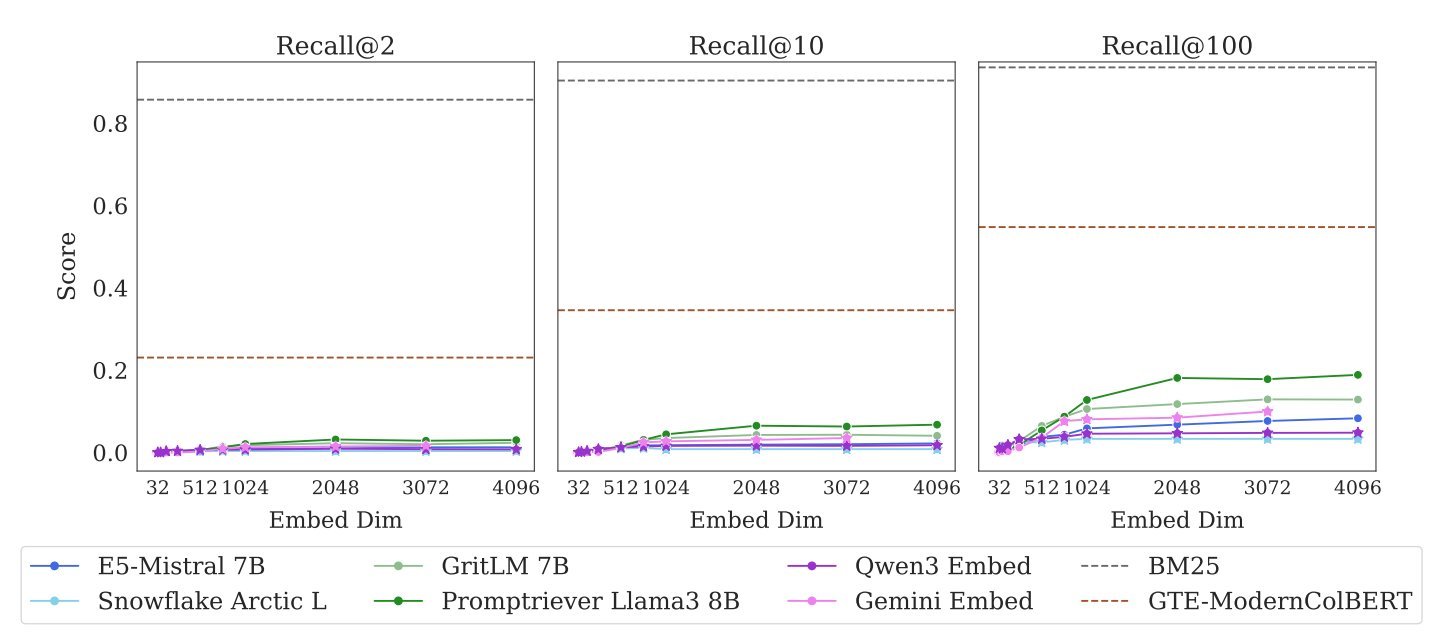
DeepMind's LIMIT dataset operationalizes these findings with 1,035 queries designed to retrieve every pair from 46 documents—creating high sign-rank complexity. Results are damning:
- Single-vector models: <20% recall@100
- Multi-vector (ColBERT) and sparse (BM25) models: Significantly outperform
This isn't about domain adaptation failure—it's architectural. Two production examples illustrate the fallout:
RAG Systems: Queries like "Compare fiscal policies of FDR and Reagan" force single vectors to find shallow documents mentioning both names, rather than retrieving the optimal separate documents on New Deal economics and Reaganomics.
E-commerce: Searches for "blue trail-running shoes size 10 under $100" return items matching some attributes but rarely all, as orthogonal constraints exceed vector dimensions.
Beyond Patches: Architectural Imperatives
The paper reframes hybrid approaches not as workarounds but as necessary architectures:
- Stop blindly scaling dimensions: Returns diminish rapidly while costs explode
- Treat single-vector as L1 cache: Use it for initial semantic recall, not final precision
- Implement combinatorial L2 layers:
- Multi-vector models (ColBERT) for dense re-ranking
- Sparse retrievers (SPLADE) for lexical-semantic fusion
- Cross-encoders for critical accuracy
"If queries are combinatorial," the research implies, "retrieval must be too." This mathematically-grounded reality demands systems that embrace—rather than mask—architectural diversity. The era of single-vector supremacy is over.
Source: Shaped AI
Comments
Please log in or register to join the discussion