
Deepseek's new technical paper introduces 'Engram,' a conditional memory module that commits static knowledge to system RAM, reducing reliance on expensive HBM and potentially scaling AI performance linearly with memory size.
Deepseek has released a technical paper detailing a new conditional memory technique called "Engram" that fundamentally changes how AI models handle long-context queries. By committing sequences of data to static memory banks separate from the model's compute units, Engram allows GPUs to focus on complex reasoning tasks while relying on more accessible system memory for knowledge storage. This approach promises to reduce the industry's heavy dependence on high-bandwidth memory (HBM) while improving performance on knowledge-intensive tasks.
The core innovation addresses what Deepseek calls "conditional computation"—the expensive process where models reconstruct data every time it's referenced in a query. Traditional Mixture of Experts (MoE) models must repeatedly access their reasoning parameters to assemble information, even for straightforward facts. Engram instead stores these facts in a queryable memory bank, allowing the model to simply check if it already has the data rather than reasoning it out each time.
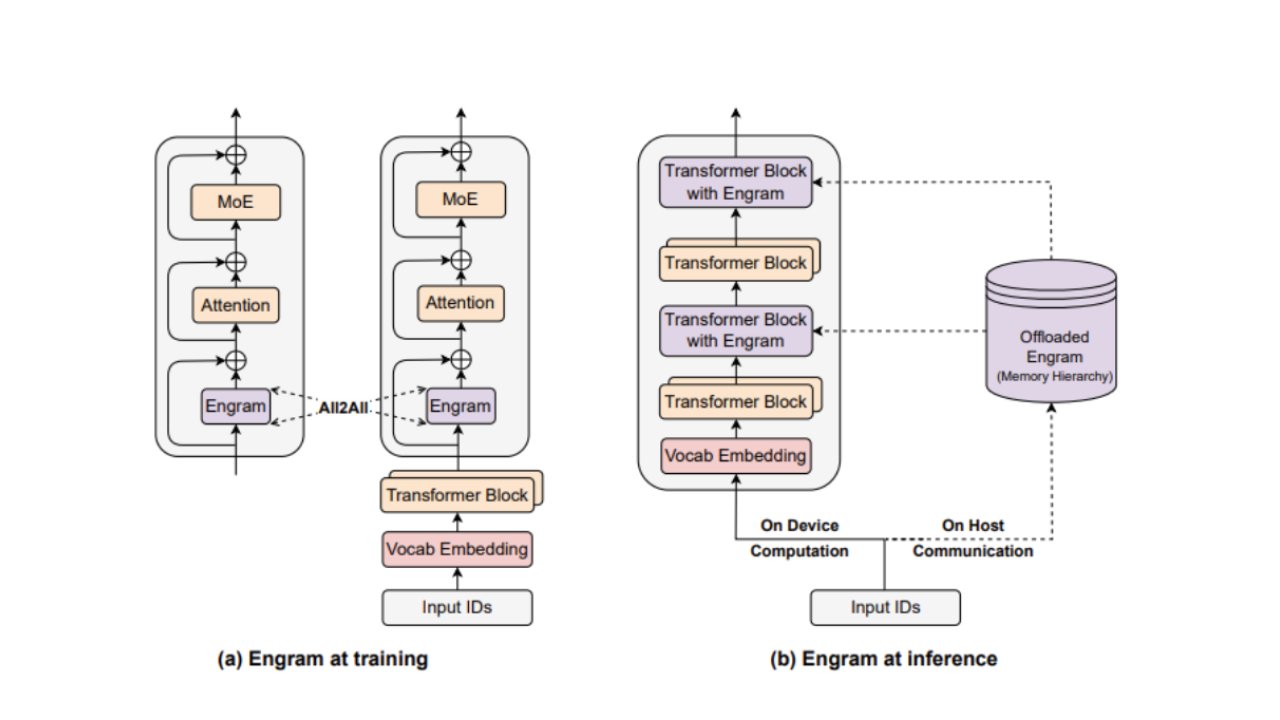
How Engram embeds itself into training and inference workloads (Image credit: Deepseek)
How Engram Works: Hashing and Gating
The system relies on tokenizer compression to reduce vocabulary size by 23%, treating equivalent tokens (like the same word with different capitalization) as identical concepts. This enables rapid information parsing. Deepseek employs "Multi-Head Hashing" to assign multiple hash values to single phrases, preventing database errors. For example, "Universal" and "Universal Studios" remain distinct entries despite potential hash collisions.
Context-aware gating then verifies that terms match their sentence context before output generation. This creates a pipeline where static knowledge sits in system memory while dynamic reasoning occurs on the GPU.

Engram compared to traditional hashing methods (Image credit: Nvidia)
Performance Results: 27B Model Beats MoE
Deepseek tested an Engram-based 27B parameter model against a standard 27B MoE model. The results showed significant improvements:
- Knowledge-intensive tasks: 3.4 to 4 point improvement over MoE
- Reasoning tasks: 3.7 to 5 point uplift
- Long-context accuracy (NIAH benchmark): 97% vs. 84.2% for MoE
- Coding and mathematics: Similar positive results
These gains come from eliminating computational waste. Instead of reconstructing static lookup tables during runtime, the model allocates sequential depth to higher-level reasoning.
The U-Curve Optimization
Deepseek discovered an optimal allocation ratio between Engram embeddings and MoE parameters. Surprisingly, the pure MoE baseline proved suboptimal. The best performance occurred when approximately 20-25% of the sparse parameter budget was reallocated to Engram, even when MoE parameters were reduced to just 40% of the total budget.
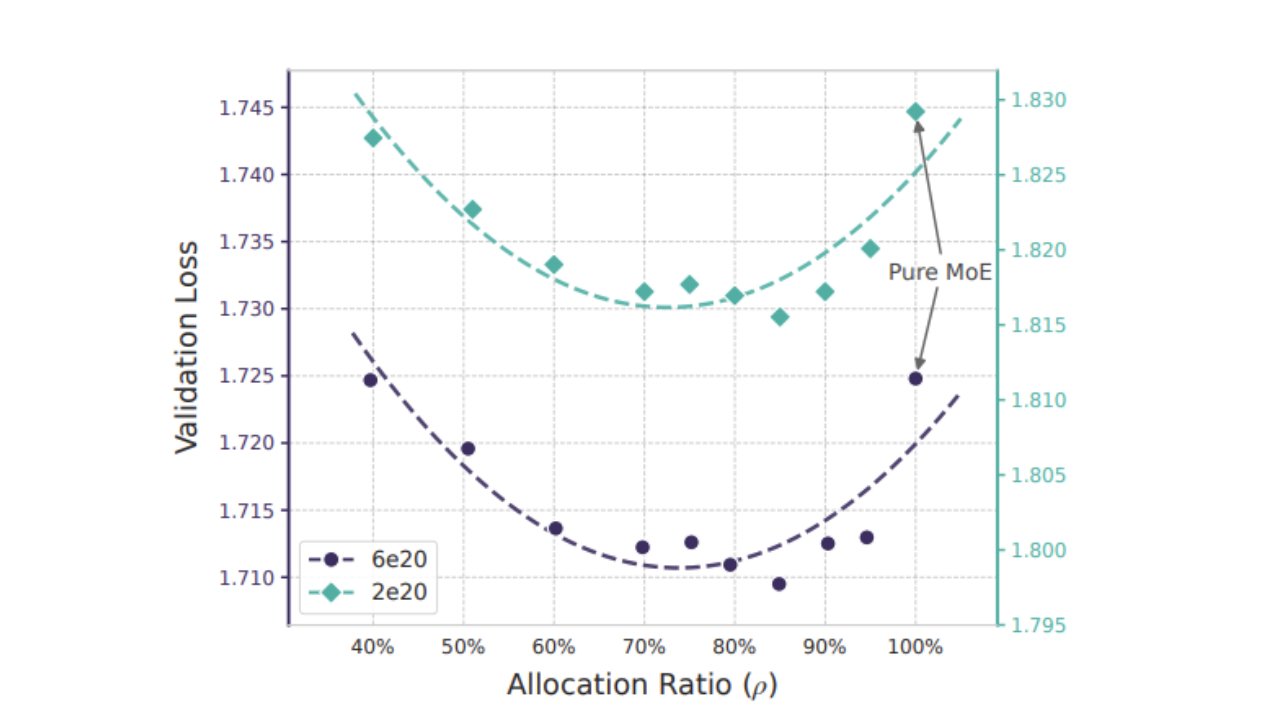
The perfect allocation ratio between Engram and MoE parameters (Image credit: Deepseek)
This reveals that memory and compute represent mathematically distinct forms of intelligence within AI models. The U-curve demonstrates that both Engram-dominated and MoE-dominated models underperform compared to a balanced approach.
Infinite Memory Regime: Linear Scaling
In a separate experiment, Deepseek maintained a fixed computational budget while attaching near-infinite conditional memory parameters. The discovery was striking: performance scaled linearly with memory size. This means AI models could improve continuously by expanding their knowledge banks without increasing compute costs.
This fundamentally changes the economics of AI scaling. If performance isn't singularly bound by compute but by accessible memory storage, the industry's memory squeeze shifts focus from HBM deployment to all available memory forms in data centers, including CXL-connected system DRAM.
Engram vs. KVCache: Different Philosophies
Nvidia's KVCache, announced at CES 2026, offloads context data to NVMe memory using BlueField-4. However, KVCache serves as a short-term solution—disposable after conversation context moves forward. It remembers recent interactions but doesn't draw on pre-calculated knowledge bases.
Engram operates differently. Where KVCache stores handwritten notes, Engram maintains a persistent encyclopedia. The distinction matters for enterprise deployments requiring consistent knowledge bases across sessions.
High-Bandwidth Memory (HBM) Roadmap showing industry constraints (Image credit: Future)
Market Implications: Breaking the HBM Dependency
The ongoing memory supply squeeze affects every AI accelerator manufacturer, including Chinese silicon like Huawei's Ascend series. Each HBM stack consumes multiple memory dies, and demand continues skyrocketing. Engram's approach could alleviate this pressure by enabling system DRAM to handle substantial portions of AI workloads.
If AI hyperscalers adopt Engram, they would diversify memory procurement beyond HBM. This might initially worsen DRAM supply constraints as demand shifts, but ultimately creates a more flexible memory ecosystem. System DRAM becomes viable for AI workloads, while HBM remains reserved for computationally intensive reasoning tasks.
What This Means for Deepseek V4
Deepseek's paper concludes with a forward-looking statement: "We envision conditional memory functions as an indispensable modeling primitive for next-generation sparse models." With rumors of a new AI model announcement within weeks, Engram implementation seems likely.
If Deepseek V4 incorporates Engram, it could trigger another "Deepseek moment"—the same market disruption the company achieved with its previous model releases. The methodology suggests AI performance improvements needn't require massive compute investments, but rather smarter memory architecture.
Real-World Deployment Questions
While paper results are impressive, real-world performance remains unproven. The NIAH benchmark improvement from 84.2% to 97% addresses AI's long-context coherence issues, but production environments introduce variables like concurrent queries, memory contention, and diverse workloads.
Engram's impact depends on whether conditional memory modules can maintain performance gains while managing system memory overhead. The technique requires substantial DRAM capacity for knowledge banks, which may limit deployment on memory-constrained systems.
Nevertheless, the fundamental insight—that memory and compute represent distinct intelligence forms—could reshape AI architecture. If Deepseek's findings hold in production, the industry's focus may shift from pure compute scaling to balanced memory-compute integration, opening new paths for efficient AI development.
Comments
Please log in or register to join the discussion