Microsoft's toolchain now enables enterprises to optimize and deploy custom small language models on-premises, completing an end-to-edge solution for privacy-sensitive AI applications.
The evolution of small language model deployment options has reached a critical inflection point with Microsoft's release of integrated optimization and serving capabilities. Where organizations previously faced limited choices for deploying custom-tuned models, the combination of Microsoft Olive for model optimization and Foundry Local for edge serving creates a compelling third path distinct from cloud-centric solutions.
Deployment Landscape Shift
Three distinct architectural approaches have emerged for SLM deployment:
| Solution | Environment Target | Complexity | Scalability | Best For |
|---|---|---|---|---|
| vLLM | Cloud (Kubernetes/VMs) | High | High | Public-facing cloud services |
| Ollama | Hybrid (Docker containers) | Medium | Medium | Developer teams, prototypes |
| Olive + Foundry | Edge/On-premise | Low | Single-node | Privacy-sensitive workloads |
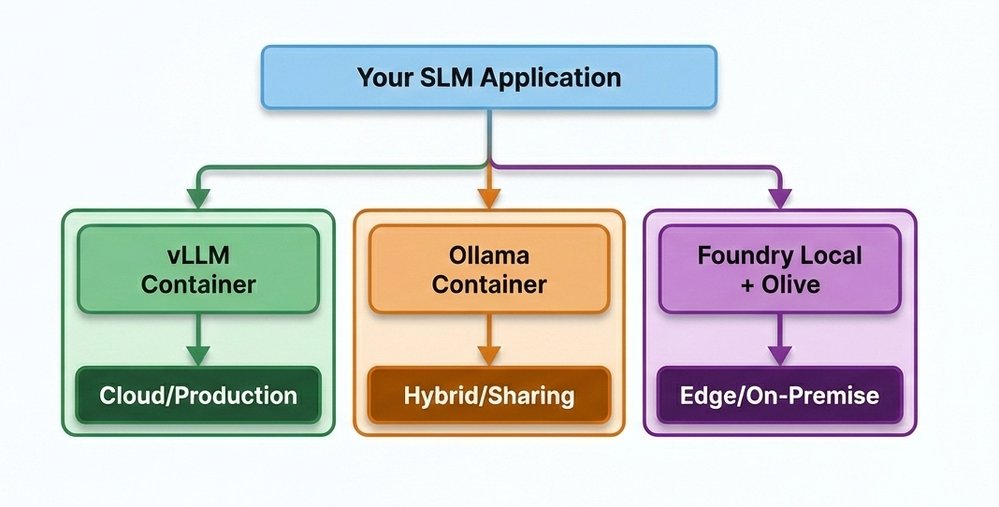
This trifurcation represents more than technical alternatives—it reflects fundamental business strategy decisions about data sovereignty, latency tolerance, and operational control. Where vLLM dominates cloud deployments requiring containerization and autoscaling, Foundry Local establishes Microsoft's stake in the growing edge computing territory. The differentiation is particularly relevant for industries like healthcare, finance, and government where regulatory compliance often prohibits cloud deployment.
Custom Model Workflow: From Hugging Face to Local Deployment
The end-to-edge workflow demonstrates Microsoft's strategic positioning:
- Model Selection: Start with any Hugging Face model (e.g., Qwen 2.5-0.5B) as proxy for proprietary fine-tuned models
- Optimization via Olive: Convert to ONNX format with quantization options:
- FP32 (baseline)
- FP16 (50% size reduction)
- INT8 (75% reduction)
- INT4 (87.5% reduction)
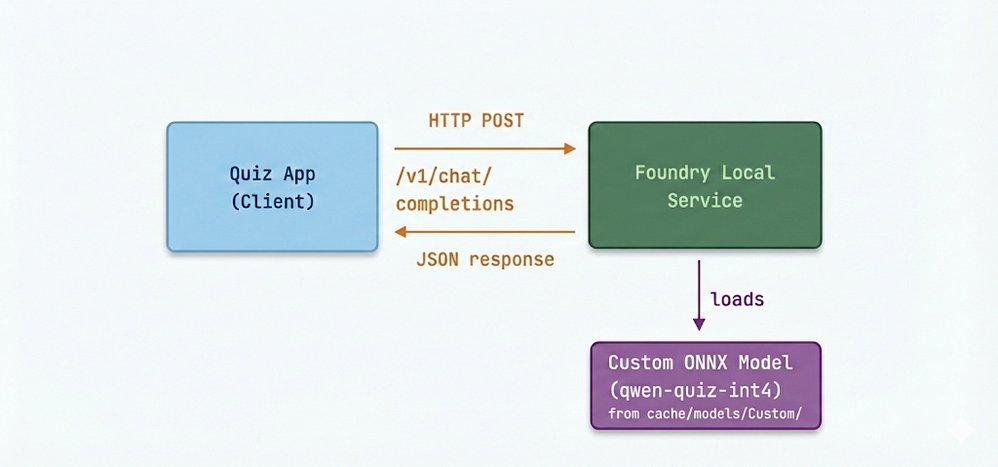
- Registry Integration: Place optimized artifacts in Foundry's local cache directory structure
- Prompt Templating: Configure
inference_model.jsonwith model-specific chat templates - Runtime Execution: Serve via Foundry Local's lightweight HTTP server
Quantization choice becomes a strategic business decision: While INT4 achieves maximum compression (87.5% smaller than FP32), INT8 frequently delivers the optimal balance for enterprise use cases—maintaining quality while dramatically reducing resource requirements. Olive's quantization pipeline makes these tradeoffs accessible through simple parameter changes.
Business Impact: Solving the Edge Deployment Gap
The integration solves two critical barriers to enterprise adoption:
Data Sovereignty Assurance By keeping both model optimization and execution within controlled environments, organizations bypass cloud data residency concerns. The entire workflow—from downloading source models to serving inferences—operates within private networks.
Customization Without Compromise Previously, Foundry Local's model catalog limited users to Microsoft-curated models. Now, the same toolchain supports:
- Proprietary fine-tuned models
- Community models from Hugging Face
- Specialized architectures
Implementation required addressing two integration challenges:
- SDK Catalog Limitations: Foundry's Python SDK initially couldn't discover custom models, necessitating endpoint auto-discovery fallbacks
- Middleware Gap: Tool calling required client-side parsing instead of server-side middleware These solutions demonstrate Microsoft's pragmatic approach to edge deployment realities—acknowledging that edge environments often require simpler, more flexible patterns than cloud infrastructure.
Strategic Implications
This capability completes Microsoft's edge AI story:
- Fine-Tuning Pathway: Enterprises can now train domain-specific models (e.g., medical diagnostics, legal contracts) and deploy them on-premises
- Hybrid Deployment Options: The same ONNX artifacts work across Microsoft's ecosystem—from Azure cloud to IoT devices via ONNX Runtime Mobile
- Cost Control: Avoiding cloud inference costs while maintaining AI capabilities
As evidenced in the quiz application case study, even heavily quantized 0.5B parameter models deliver sufficient quality for structured tasks when optimized correctly. For more demanding workloads, the identical workflow supports larger models like Qwen 2.5-7B.
The Complete Journey
This deployment milestone concludes a progression demonstrating Microsoft's edge-first vision:
- SLM fundamentals and local execution
- Function calling capabilities
- Multi-agent orchestration
- Custom model deployment
The full implementation provides organizations with production-ready patterns for private AI deployment. When combined with Microsoft's Edge AI curriculum, it represents the most complete on-premise AI solution currently available—positioning Microsoft uniquely against cloud-first competitors.
For technical teams, the implications are clear: The barrier to deploying specialized AI in regulated environments has been substantially lowered. The remaining challenge isn't technical implementation, but identifying the high-value use cases where this edge deployment model creates competitive advantage.
Comments
Please log in or register to join the discussion