Microsoft's Foundry Local now supports native OpenAI-compatible function calling for select small language models, enabling sophisticated multi-agent architectures that challenge cloud-based solutions while offering cost efficiency and data control.
Microsoft's Foundry Local framework has introduced native OpenAI-compatible function calling capabilities for small language models (SLMs), fundamentally altering how enterprises approach multi-agent AI architectures. This shift from manual text parsing to structured tool invocation creates new strategic options for organizations balancing cloud dependencies, cost efficiency, and data privacy.
What Changed: From Fragile Workarounds to Native Execution
Previously, integrating SLMs with external tools required cumbersome text parsing using regex patterns—a brittle approach vulnerable to output inconsistencies. With Foundry Local 0.8.117+, select models like Qwen 2.5-7B now natively support structured tool_calls objects adhering to OpenAI's function calling specification. This eliminates prompt engineering overhead while enabling direct execution of defined functions through standardized API calls.
Provider Comparison: Local vs. Cloud Economics
This update positions Foundry Local uniquely against cloud providers:
- Cost Structure: Cloud APIs like OpenAI charge per token, creating variable operational expenses. Foundry Local's one-time model download (∼4GB for Qwen 2.5-7B) converts costs to fixed infrastructure overhead. For high-volume workflows like educational quizzes or customer support, local execution avoids recurring fees.
- Privacy & Control: Unlike cloud services where data leaves premises, Foundry Local keeps all processing on-device—critical for healthcare, education, or financial applications handling sensitive data.
- Model Flexibility: Cloud providers limit function calling to specific models (e.g., GPT-4). Foundry Local supports mixing specialized SLMs (e.g., 1.7B for structured tasks, 7B for conversations), optimizing hardware utilization.
- Migration Path: Organizations using cloud-based function calling can transition gradually by:
- Replacing individual agents with local SLMs
- Maintaining cloud orchestration initially
- Shifting coordination on-premises after validation
Business Impact: The Multi-Agent Advantage
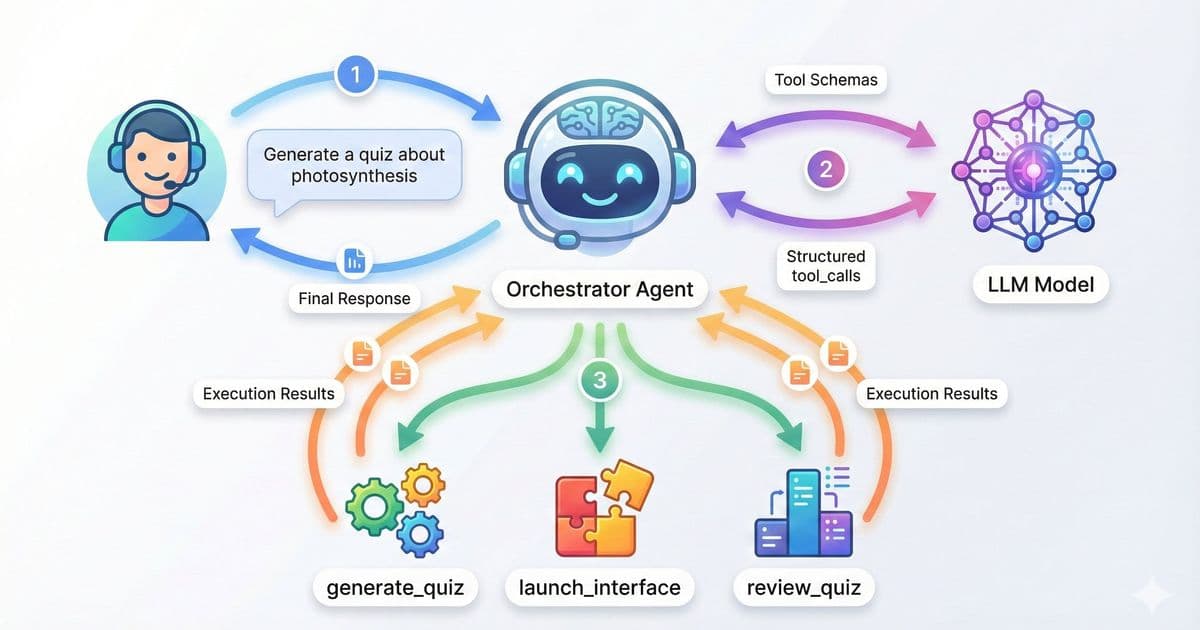
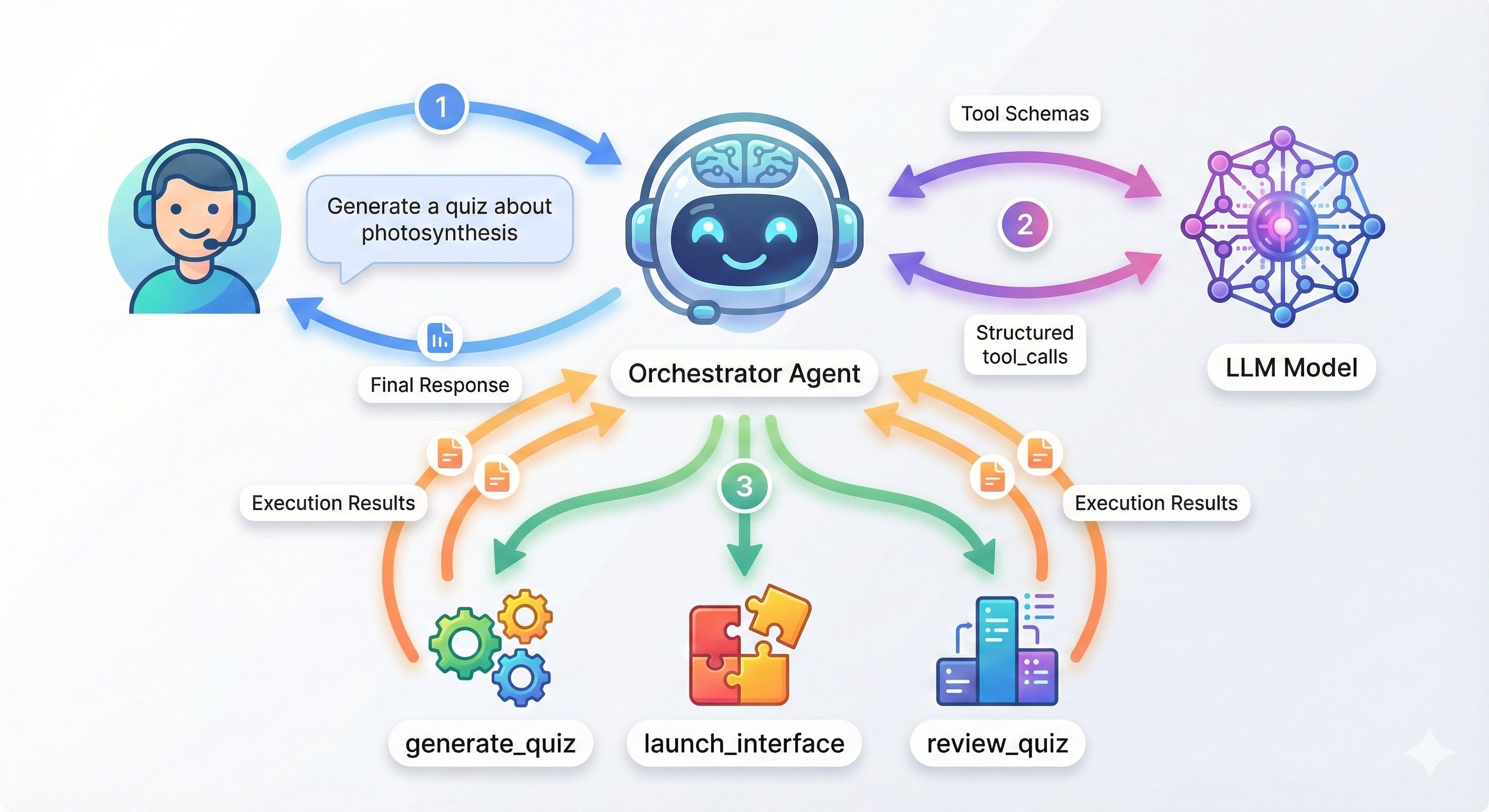
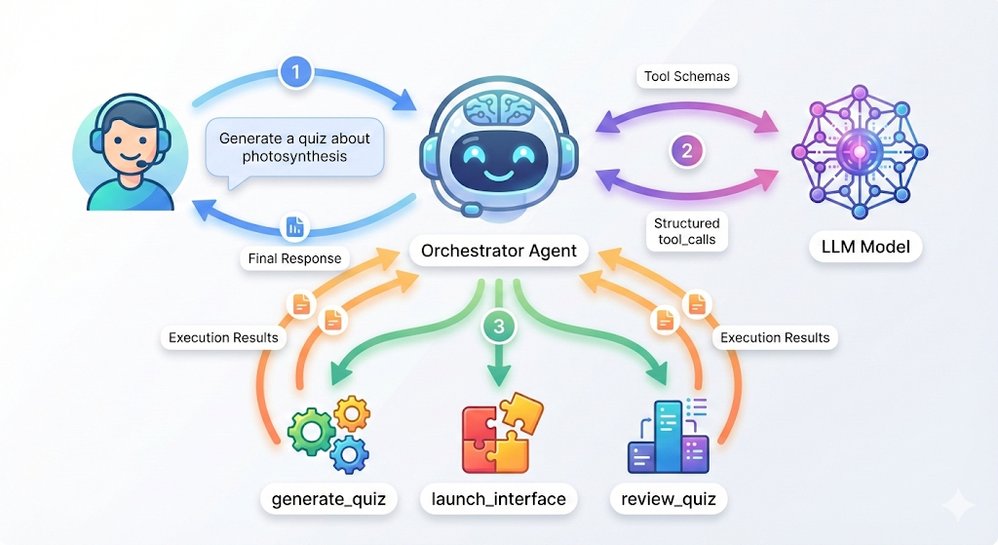
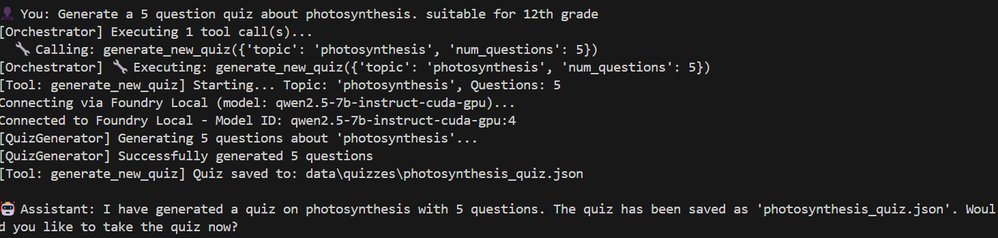
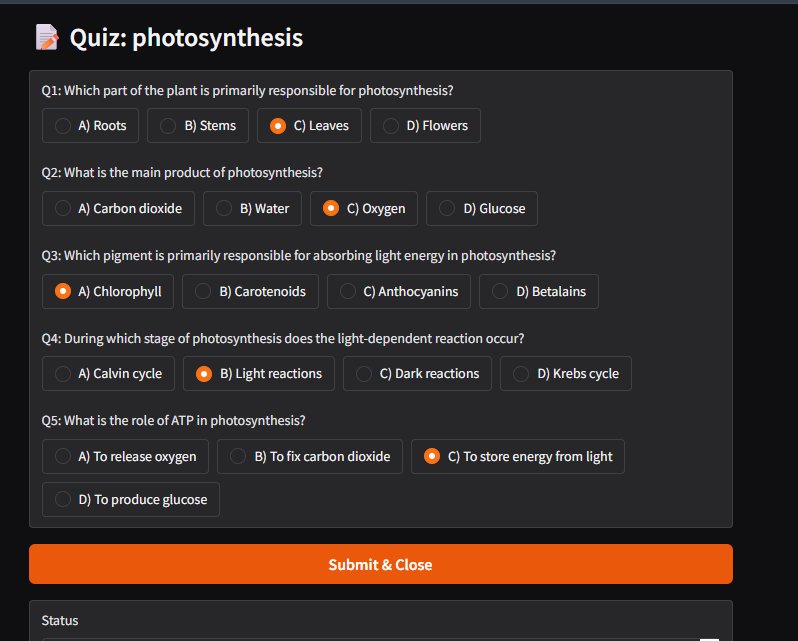
Foundry Local's native function calling enables true multi-agent architectures where specialized models collaborate under a coordinator. In Microsoft's quiz application demo:
- An orchestrator routes requests to purpose-built agents
- A QuizGeneratorAgent creates structured content using low-temperature settings
- A ReviewAgent provides personalized tutoring with higher creativity parameters
This pattern delivers three strategic benefits:
- Specialization Efficiency: Smaller models outperform generalist LLMs in narrow domains. A 7B model focused solely on quiz generation produces higher-quality output than a 70B model handling multiple tasks.
- Cost Containment: Separating workloads to optimized SLMs reduces hardware requirements. CPU-bound tasks can run alongside GPU-accelerated agents.
- Architectural Resilience: Agents remain decoupled—failure in one component (e.g., quiz generation) doesn't crash the entire system. New capabilities integrate via tool schemas without core modifications.
Strategic Implementation Considerations
Organizations adopting this approach should evaluate:
- Hardware Requirements: Qwen 2.5-7B requires 6-8GB VRAM for smooth operation. CPU fallbacks increase latency.
- Tooling Maturity: Currently limited to Qwen models; broader SLM support will determine long-term viability.
- Development Shift: Teams accustomed to cloud APIs must learn local orchestration patterns using tools like the provided Foundry Client.
The Local-First Future
This advancement signals a broader trend: mission-critical AI workloads shifting from cloud-centric to hybrid or local-first deployments. Foundry Local demonstrates that SLMs with native function calling can match cloud services for structured workflows while offering superior data governance. For enterprises, this means:
- Reduced vendor lock-in risks
- Predictable operational costs
- Customizable agent ecosystems
As Microsoft expands compatible models, expect more organizations to deploy local multi-agent systems for education, internal tooling, and regulated industries—where control and cost efficiency outweigh cloud convenience.
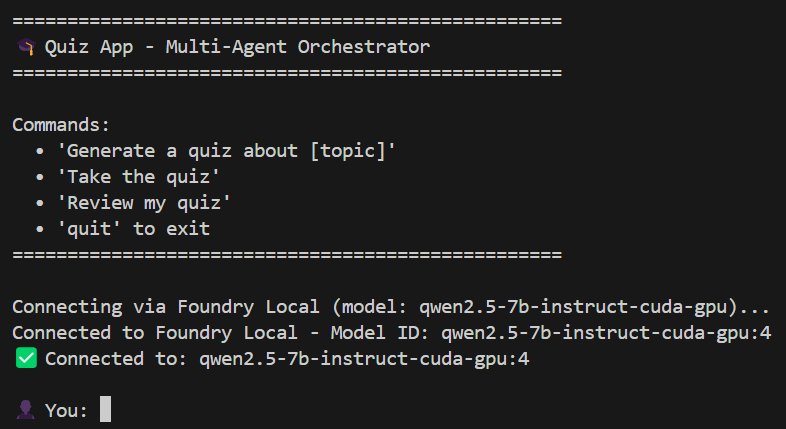
The quiz application source code provides a practical implementation blueprint. Businesses exploring this model should start with narrowly scoped agent teams before scaling to complex workflows.
Comments
Please log in or register to join the discussion