OpenAI's first open-weight LLMs since GPT-2, gpt-oss-120b and gpt-oss-20b, reveal strategic shifts in transformer design—embracing Mixture-of-Experts, MXFP4 quantization, and sliding window attention. We dissect how these choices stack against Alibaba's Qwen3 and what they signal for efficient, locally deployable AI. Source analysis shows surprising trade-offs in width vs. depth and expert specialization that redefine developer possibilities.
OpenAI’s release of gpt-oss-120b and gpt-oss-20b marks its first open-weight models since GPT-2 in 2019—a seismic shift for developers craving transparency in frontier AI. These models, optimized to run locally on consumer GPUs via MXFP4 quantization, aren’t just incremental updates; they’re architectural statements. Sebastian Raschka’s deep dive into their code and technical reports reveals how OpenAI has evolved beyond legacy designs while borrowing from industry trends, culminating in a head-to-head clash with Alibaba’s Qwen3.
From GPT-2 to gpt-oss: The Transformer’s Unseen Metamorphosis
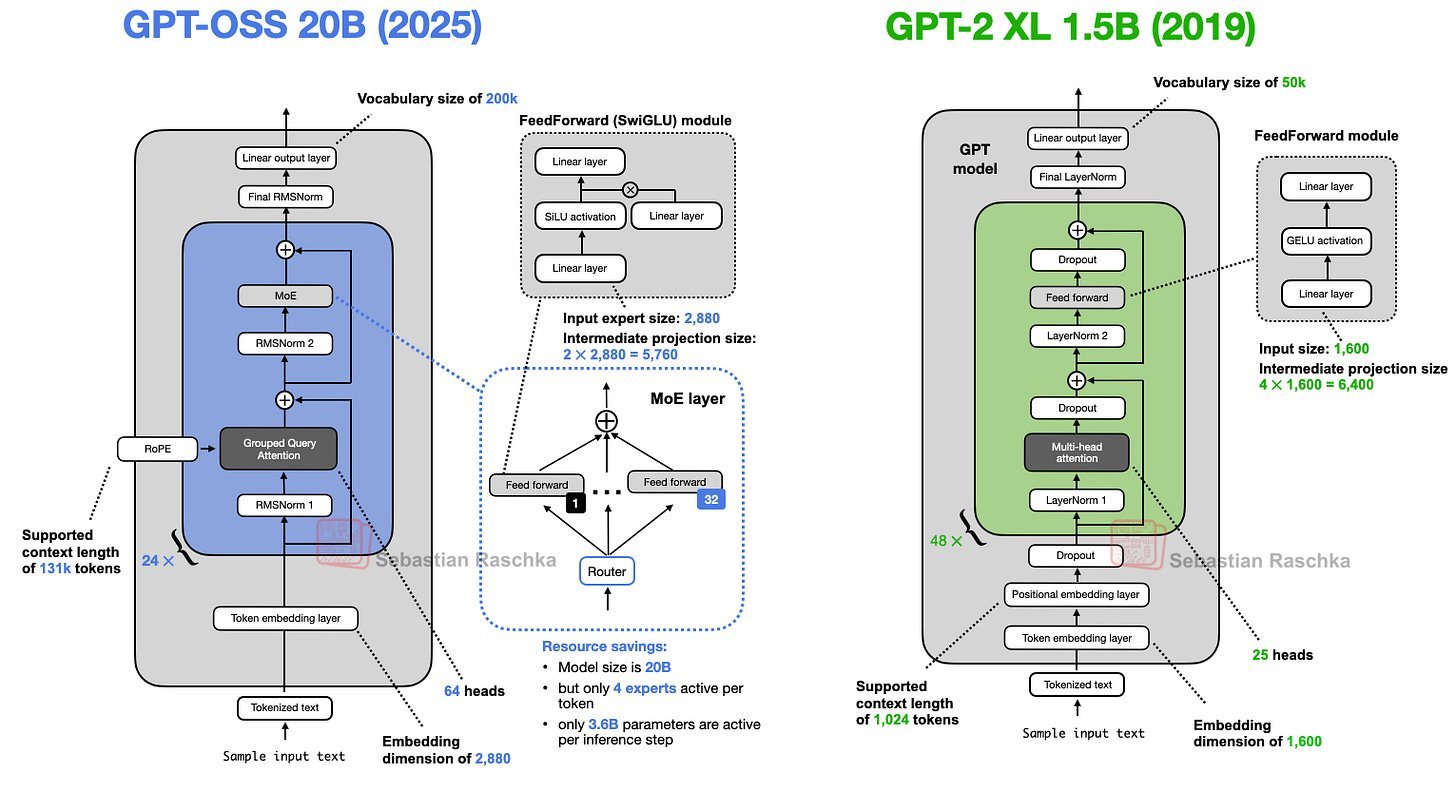
Comparing gpt-oss-20b to its ancestor GPT-2 XL (1.5B) exposes radical refinements that now define modern LLMs:
- Dropout Abandoned: Once critical for preventing overfitting, dropout vanished as single-epoch training on massive datasets reduced its utility. Raschka notes:
Recent studies confirm dropout harms performance in large-scale, single-pass training—validating its omission in gpt-oss.
- Positional Encoding Revolution: Absolute embeddings gave way to Rotary Position Embedding (RoPE), enhancing sequence awareness without added parameters.
- Activation Upgrades: GELU activations were replaced by SwiGLU—a gated linear unit variant. Code comparisons show SwiGLU’s efficiency:
This reduces parameters by 25% while adding multiplicative interactions for richer expressivity.# Traditional FFN (GPT-2) fc1 = nn.Linear(1024, 4096) fc2 = nn.Linear(4096, 1024) # SwiGLU (gpt-oss) fc1 = nn.Linear(1024, 2048) fc2 = nn.Linear(1024, 2048) fc3 = nn.Linear(2048, 1024) - Attention Refinements: Multi-head attention evolved into Grouped Query Attention (GQA), slashing memory use by sharing key-value projections across heads. Half the layers also integrate sliding window attention (128-token context), echoing GPT-3’s sparse patterns but at a minimal window size.
- Normalization Shift: LayerNorm was swapped for RMSNorm, cutting computation by eliminating mean subtraction—a nod to GPU efficiency.
gpt-oss vs. Qwen3: Width, Depth, and the MoE Gambit
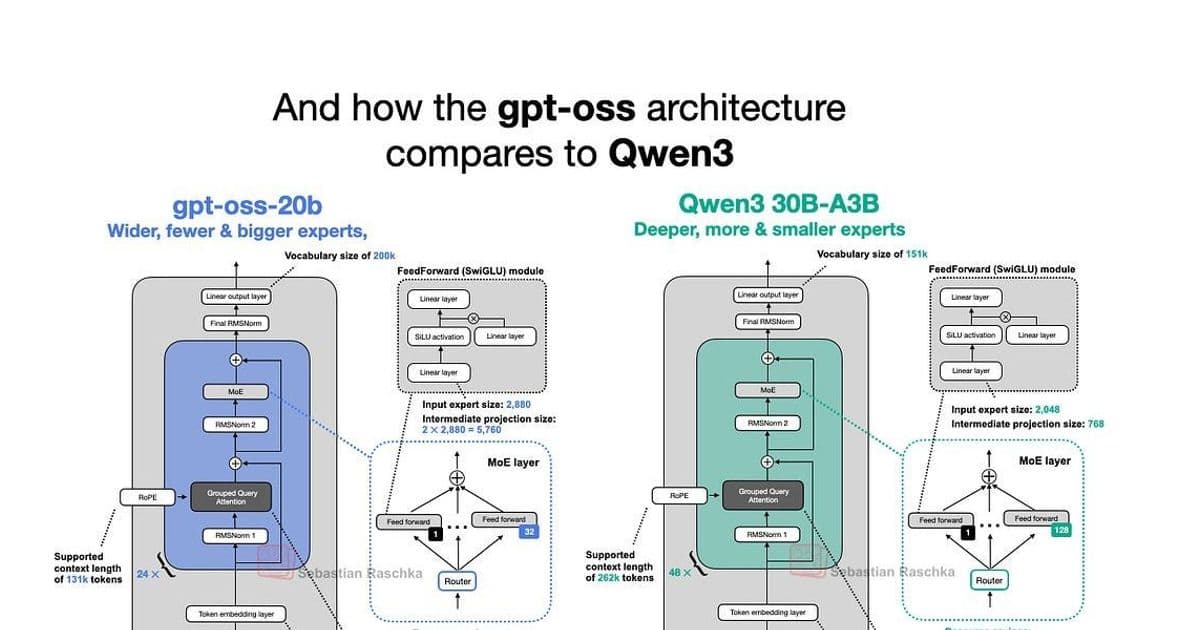
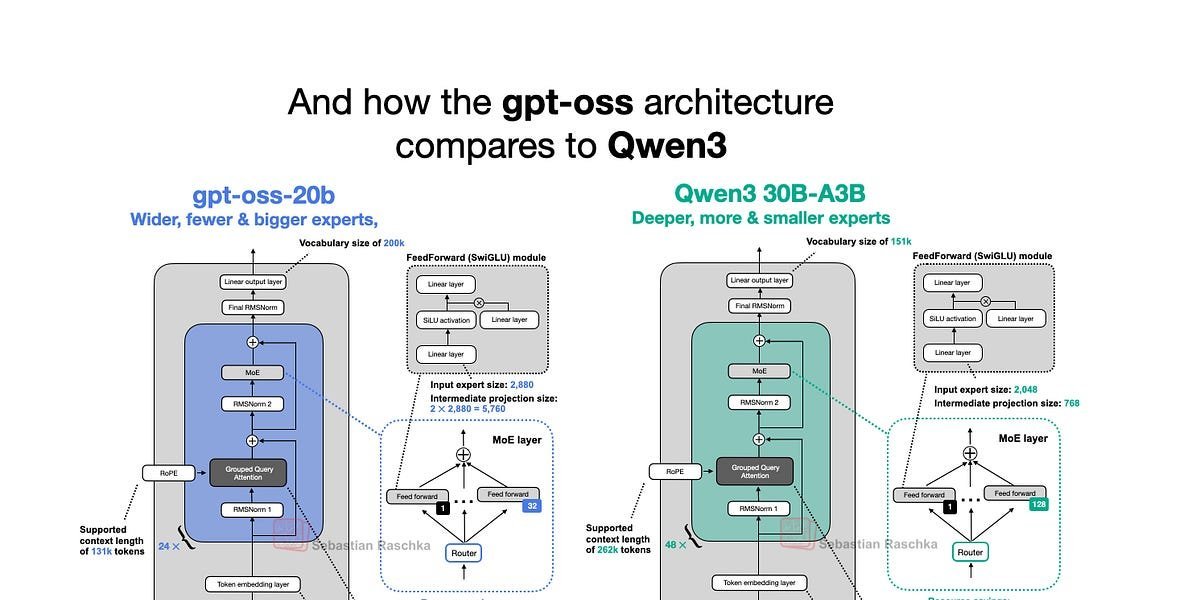
Placing gpt-oss-20b beside Qwen3’s 30B-A3B model highlights divergent scaling philosophies:
- Width vs. Depth: gpt-oss favors width (embedding dim 2880) over Qwen3’s depth (48 layers vs. 24). Raschka cites Gemma 2 benchmarks suggesting wider models edge out deeper ones in throughput-sensitive applications, albeit with higher memory costs.
- Expert Strategies: gpt-oss uses fewer, larger experts (32 total, 4 active/token) versus Qwen3’s many-small approach (128 experts, 8 active). This defies trends like DeepSeekMoE’s push toward specialization via compact experts, raising questions about optimal MoE configurations at scale.
- Attention Nuances: Unlike Qwen3, gpt-oss employs attention sinks—learned per-head biases that stabilize long-context processing—and retains query/key biases, a rarity post-GPT-2. Raschka questions their necessity, referencing studies showing marginal performance gains.
Beyond Architecture: Training, Reasoning, and the Single-GPU Frontier
gpt-oss’s 2.1 million H100-hour training run focused on STEM and coding data, blending supervised fine-tuning with RL for reasoning. Crucially, it introduces adjustable reasoning effort:
System: "Reasoning effort: medium"
Model: *Adjusts response length/accuracy*
This lets developers balance cost against task complexity—contrasting with Qwen3’s abandoned hybrid thinking mode.
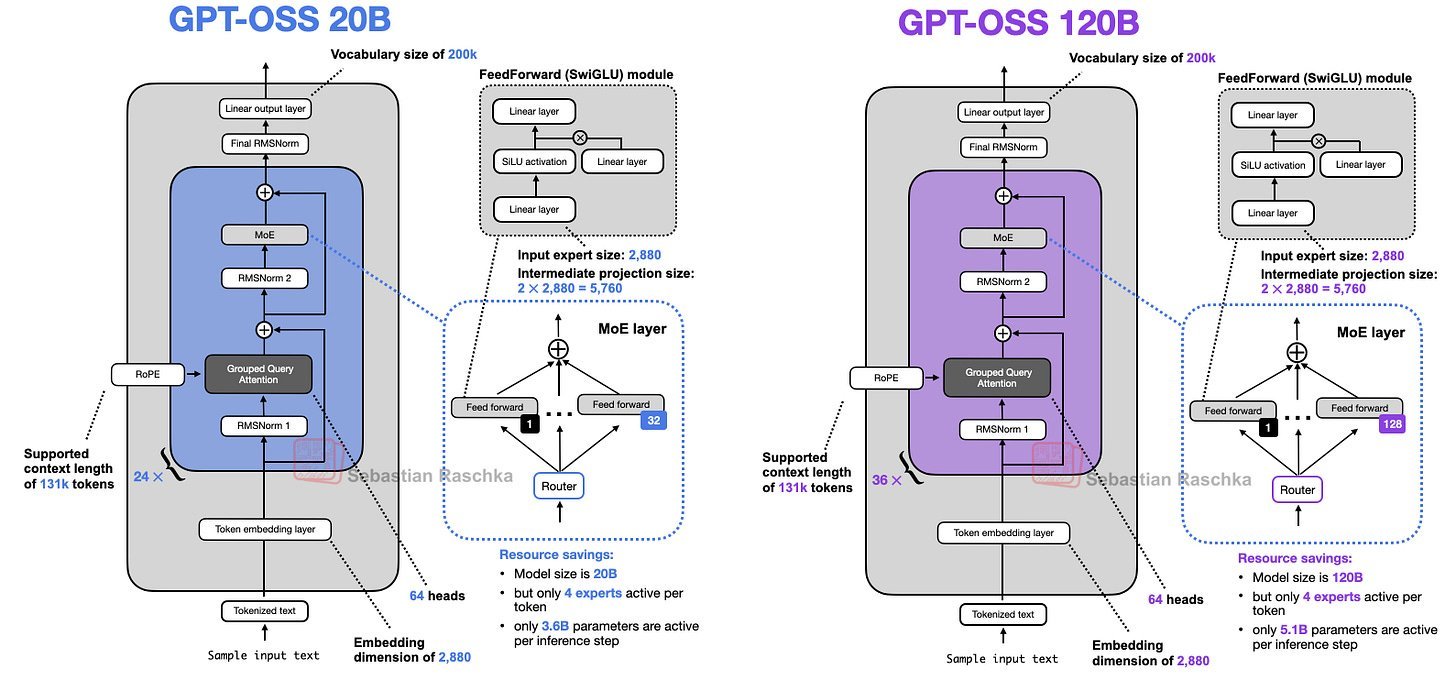
The MXFP4 quantization breakthrough enables unprecedented accessibility:
- gpt-oss-20b fits on a 16GB RTX 50-series GPU.
- gpt-oss-120b runs on a single 80GB H100.
Raschka confirms:
Without MXFP4, memory demands balloon to 48GB (20B) and 240GB (120B), making local deployment impractical.
Benchmarks and the GPT-5 Shadow
Early benchmarks show gpt-oss-120b rivaling OpenAI’s proprietary GPT-4 Turbo in reasoning tasks while trailing Qwen3-Instruct on the LM Arena leaderboard. However, Raschka flags hallucinations in knowledge queries, likely from over-indexing on reasoning training. With GPT-5’s release closely following gpt-oss, OpenAI signals that open-weight models are complementary—not competitors—to its flagship products.
As gpt-oss democratizes high-capacity AI, its Apache 2.0 license invites commercial tinkering. Yet the real win is architectural transparency: developers now have a blueprint for efficient, scalable transformers that prioritize problem-solving over rote memorization—ushering in an era where local LLMs handle complex workflows without cloud dependencies.
Source: Sebastian Raschka, Ahead of AI.
Comments
Please log in or register to join the discussion