
Discover how YDB engineered a custom binary JSON format to overcome parsing bottlenecks in distributed SQL databases, enabling O(1) array access and O(logN) object lookups while maintaining compact storage. This technical breakdown reveals why existing solutions like BSON and JSONB fell short for YDB's scalability needs.
When handling JSON in high-performance databases, traditional string-based storage creates an unavoidable performance tax: parsing multi-megabyte documents just to access a single field. This was the challenge faced by YDB's engineering team while developing their distributed SQL database, which prioritizes strong consistency at scale. The solution? A purpose-built binary format called BinaryJson that fundamentally rethinks JSON storage.
The JSON Parsing Bottleneck
YDB initially stored JSON data as validated strings—a common approach. But as engineer Artem Razin explains, querying even trivial fields in large documents became prohibitively expensive: "Even if the query only accesses field type, we still need to parse the rest of 10MB before extracting it." This linear parsing overhead scaled catastrophically with dataset size.
Why Existing Formats Fell Short
Two established binary JSON formats were evaluated:
- BSON (MongoDB): Interleaves structure and data, forcing linear searches for object keys. Also carries legacy type baggage irrelevant to YDB.
- JSONB (PostgreSQL): Similarly interleaves values/structure and is tightly coupled to PostgreSQL's codebase, making extraction impractical.
Neither met YDB's requirements for:
- Sub-linear access times (O(1) for arrays, O(logN) for objects)
- Minimal storage overhead (<2x original JSON)
- Decoupled, versionable implementation
BinaryJson Architecture: Separation of Concerns
YDB's novel approach separates document structure from bulk data. The format comprises four sections:
 BinaryJson's segmented architecture (Source: Artem Razin)
BinaryJson's segmented architecture (Source: Artem Razin)
- Header: Versioning + pointer to string index (using 27-bit offset)
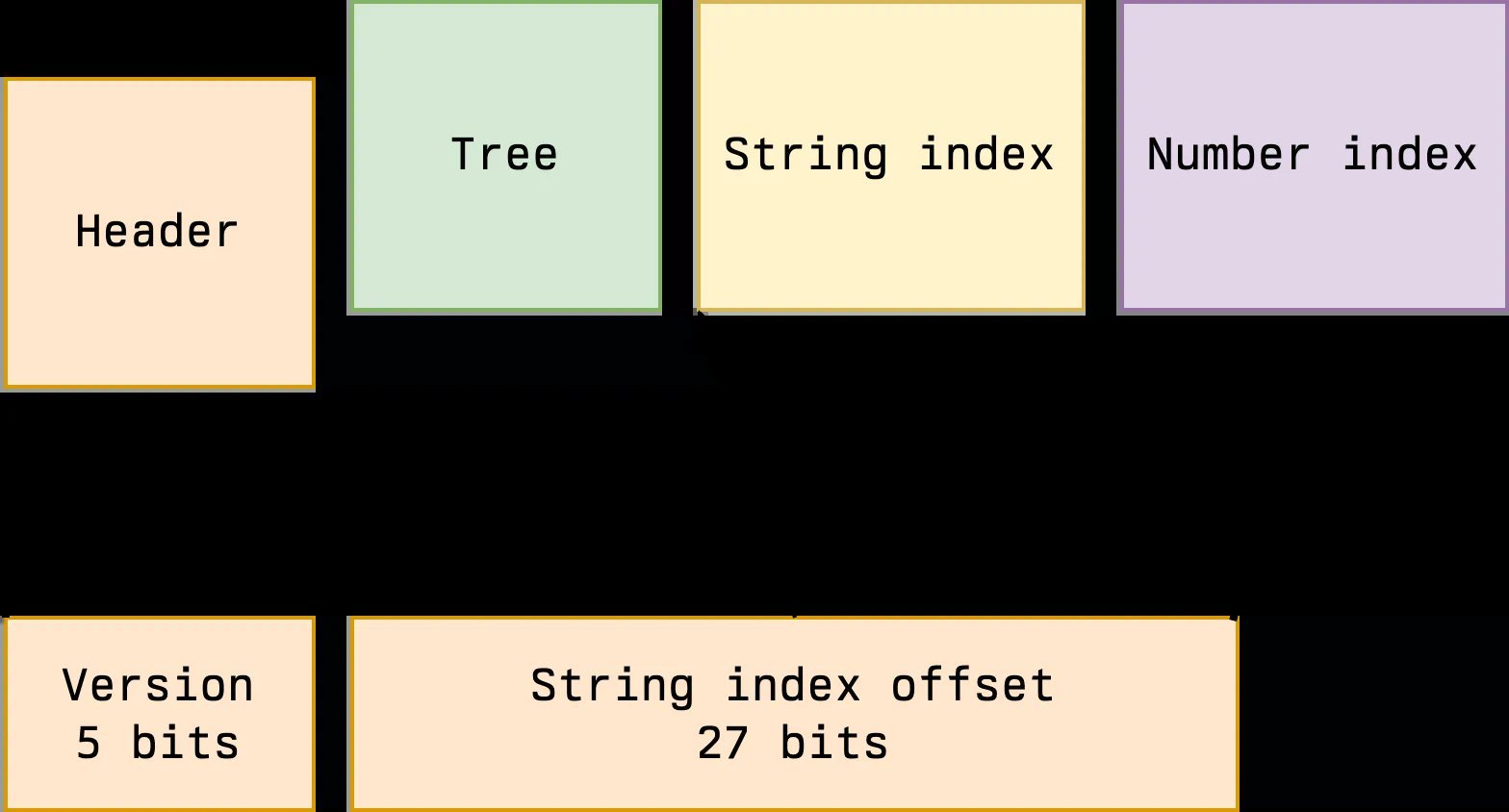
- Tree: Hierarchical node structure using 32-bit entries
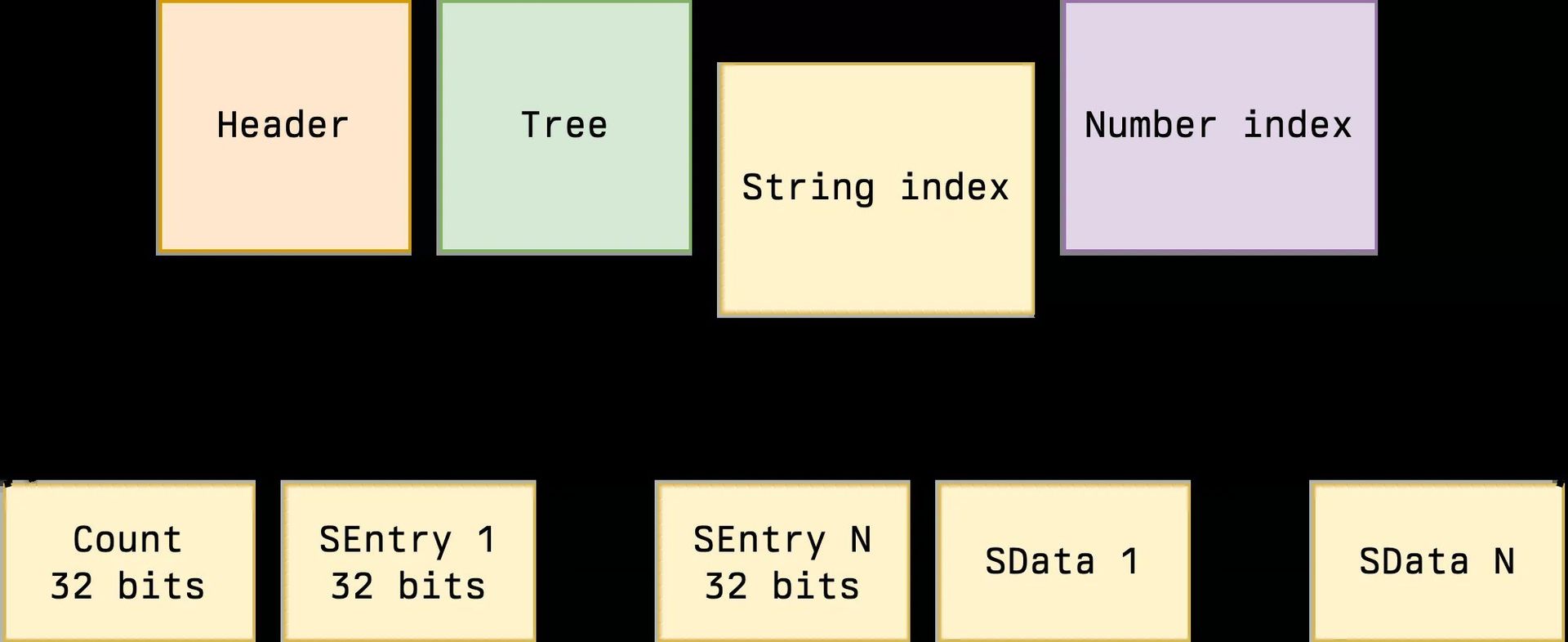
- String Index: Length-prefixed, null-terminated strings with O(1) access
- Number Index: Flat array of doubles
Smart Value Encoding
Tree nodes use 5-bit type tags with 27-bit payloads:
Type 0: Boolean false
Type 1: Boolean true
Type 2: Null
Type 3: String index reference
Type 4: Number index reference
Type 5: Container (array/object) pointer
This enables single-byte storage for primitives and efficient referencing for larger values.
Container Optimization
Arrays store value entries contiguously after metadata, enabling O(1) index access:
ArrayElementOffset(i) = ArrayStart + i * sizeof(Entry)
Objects use dual arrays: sorted keys (string indices) followed by values. Key lookup uses binary search:
KeyOffset(i) = ObjectStart + i * sizeof(KeyEntry)
ValueOffset(i) = ObjectStart + N*KeyEntrySize + i*sizeof(Entry)
 String index structure enabling efficient key lookups (Source: Artem Razin)
String index structure enabling efficient key lookups (Source: Artem Razin)
Why This Matters for Distributed Systems
By eliminating full-document parsing, BinaryJson reduces CPU overhead significantly for partial JSON reads—critical when scanning petabytes across nodes. Storage efficiency remains comparable to textual JSON (unlike BSON's typical 30-40% bloat). The format's versioning header also future-proofs deployments.
Future Horizons
Razin notes several optimization opportunities:
- Perfect hashing for O(1) object lookups
- NaN-tagged doubles to eliminate number indexing
- Inlining small strings in entries
As databases increasingly handle semi-structured data, formats like BinaryJson demonstrate how thoughtful engineering can turn JSON from a liability into a scalable asset. YDB's implementation is now open-source, inviting further collaboration.
Source: How Binary JSON Works in YDB by Artem Razin
Comments
Please log in or register to join the discussion