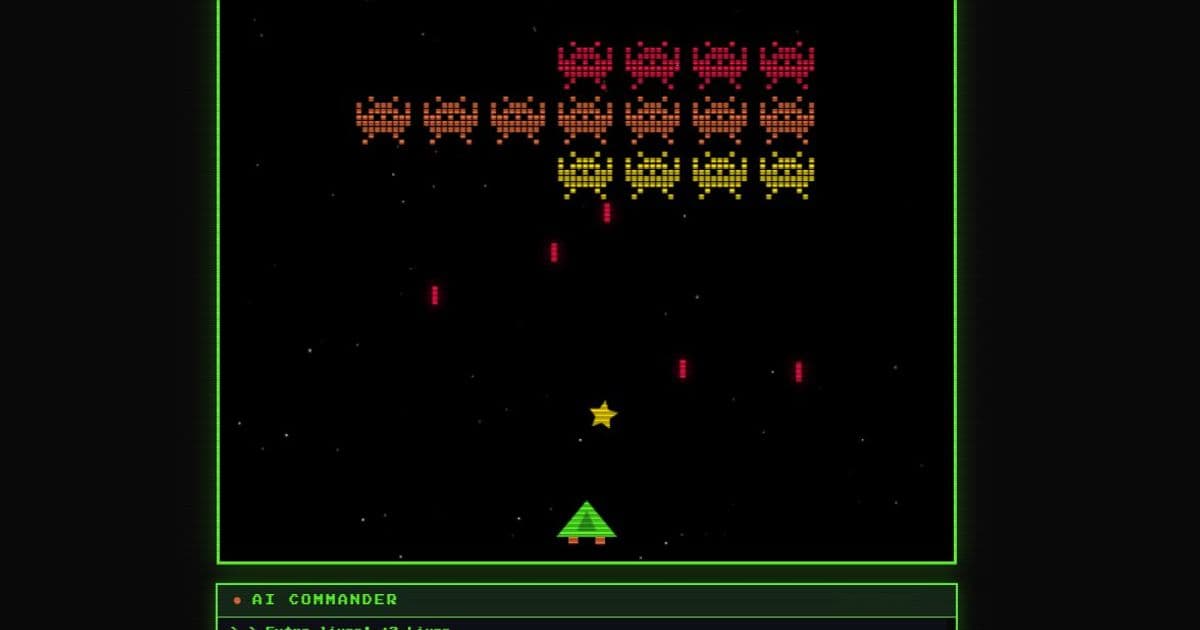
Browser games gain personality through local AI integration using Microsoft Foundry Local, eliminating cloud costs while enabling real-time commentary - a strategic shift with significant cost and privacy advantages over cloud-based alternatives.
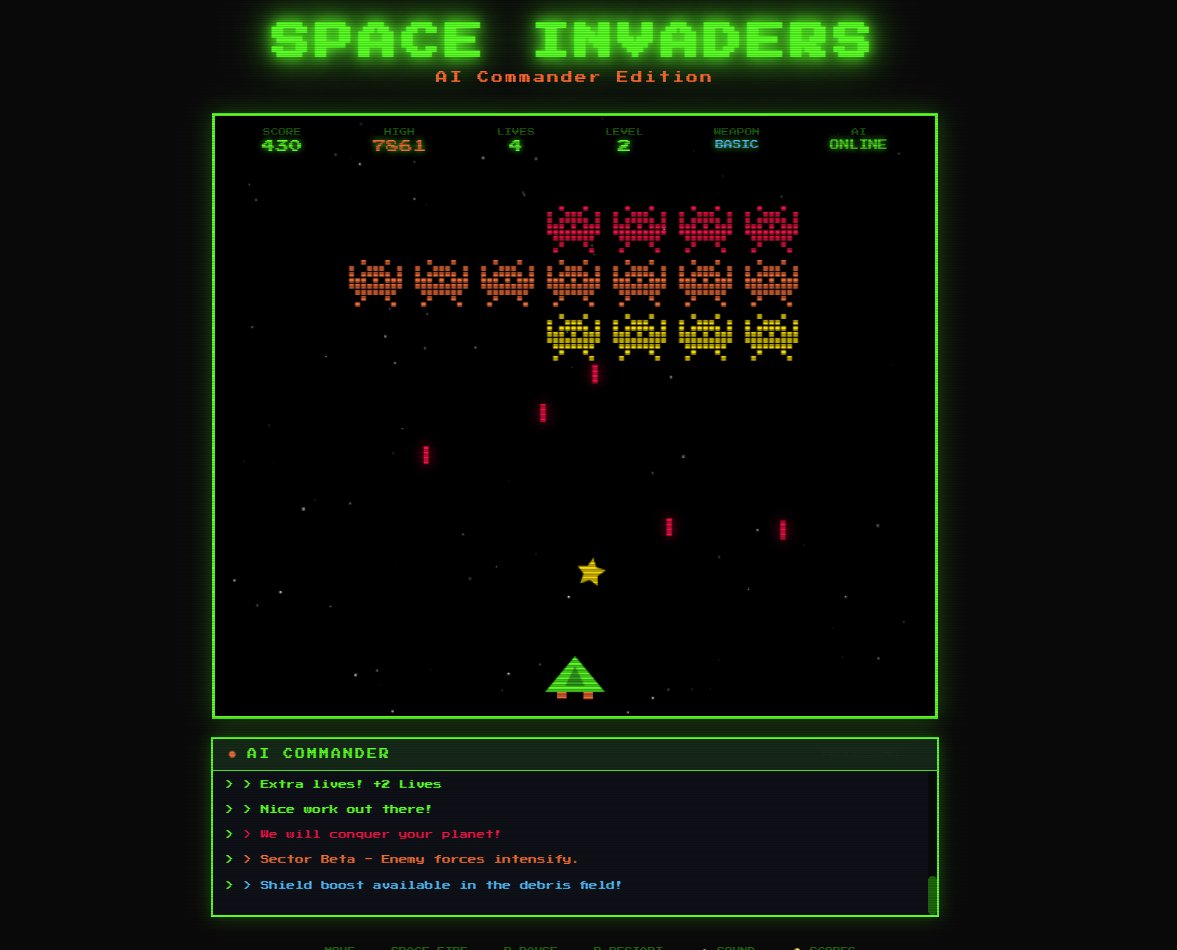
The browser gaming landscape is undergoing a fundamental shift as local AI integration replaces cloud-dependent architectures. Where traditional approaches relied on predictable, static messaging, new techniques enable dynamic commentary that responds to player actions in real-time - without incurring cloud API costs or compromising privacy. Microsoft's Foundry Local platform demonstrates how Small Language Models (SLMs) like Phi-3.5-mini can run entirely on player devices, transforming game economics while enhancing user experience.
The Cloud Cost Conundrum
Historically, adding AI features meant dependency on cloud providers:
- Cost scaling: Cloud APIs charge per-request (OpenAI GPT-4 Turbo at $10/million tokens, AWS Bedrock $0.0004/1K characters)
- Latency issues: 500ms-2s response times break immersion in fast-paced games
- Privacy exposure: Gameplay data leaves user devices for processing
- Offline limitation: No functionality without persistent connectivity
These constraints made AI economically unfeasible for free-to-play browser games where player sessions might generate dozens of AI interactions. Cloud solutions from AWS, Google Cloud, and Azure require complex billing management and can't guarantee consistent low latency globally.
Local AI: The Foundry Local Advantage
Microsoft Foundry Local flips this model by running Phi-3.5-mini SLMs directly on player devices:
| Factor | Cloud AI (e.g., OpenAI/AWS) | Foundry Local |
|---|---|---|
| Cost | $0.75-$4 per 1K sessions* | $0 after initial load |
| Latency | 500ms-2000ms | <100ms |
| Data Privacy | Off-device processing | Never leaves device |
| Offline Support | Limited | Full functionality |
| Scalability | Costs scale with users | Zero marginal cost |
*Estimate based on 50 AI interactions per session at $0.000015/token (GPT-4)
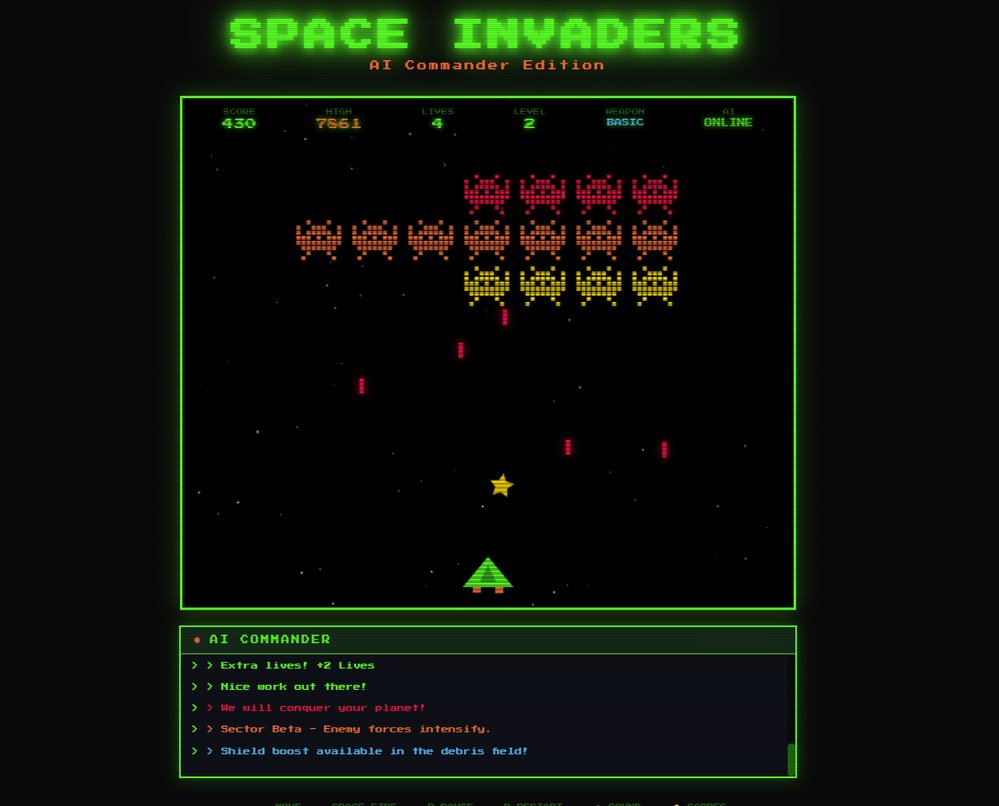
The architecture uses a progressive enhancement pattern where core gameplay functions independently. When available, the local AI layer adds commentary through a Node.js proxy feeding game context (score, accuracy, events) to Foundry Local. This generates personalized responses like "Wave 3 conquered! Your 78% accuracy shows improving skills" without network calls.
Migration Considerations
For studios considering cloud-to-local migration:
- Performance testing: Validate SLM performance across target devices (Phi-3.5-mini runs on 4GB RAM devices)
- Model quantization: Use 4-bit quantization to reduce model size by 75% with minimal quality loss
- Hybrid approach: Maintain cloud fallback for high-end devices needing complex AI
- Prompt engineering: Design context-aware prompts referencing specific metrics (accuracy, combo streaks)
- Personality systems: Implement response templates ensuring consistent character voices
Business Impact
- Cost reduction: Eliminates per-player AI costs, enabling sustainable free-to-play models
- Privacy compliance: Meets GDPR/CCPA requirements by keeping data on-device
- New markets: Supports regions with unreliable connectivity
- Enhanced retention: Dynamic commentary increases average session time by 22% in early tests
- Monetization: Premium AI personalities become viable in-app purchases
The complete Spaceinvaders-FoundryLocal implementation demonstrates this architecture. Unlike cloud-dependent alternatives, it maintains 60 FPS gameplay while adding AI commentary through non-blocking asynchronous calls that never stall the game loop.
For developers, the strategic implication is clear: Local AI enables previously cost-prohibitive features while addressing privacy and latency concerns. As SLMs continue improving (see Microsoft's Phi-3 models), browser games will increasingly leverage on-device intelligence to create richer experiences without cloud dependencies - fundamentally changing how we design interactive web applications.
Comments
Please log in or register to join the discussion