
Modal has developed a groundbreaking approach to reduce inference cold starts from tens of minutes to seconds, dramatically improving GPU utilization and enabling truly serverless AI applications.
Modal, a startup focused on optimizing AI infrastructure, has announced a breakthrough in reducing inference cold starts by up to 40x. Their approach combines four key innovations—cloud buffers, custom filesystems, checkpoint/restore, and CUDA checkpoint/restore—to address the fundamental challenge of GPU utilization in AI inference workloads.
The Problem: GPU Utilization in AI Inference
AI inference presents a unique challenge in cloud infrastructure. Unlike training workloads that can be carefully scheduled, inference demands are highly variable and unpredictable, driven by external user behavior, market conditions, and social media trends. This variability creates a fundamental tension between capacity planning and cost efficiency.
As Modal's engineers explain, "GPUs are expensive and scarce, so we want to maximize their utilization, where 'utilization' is the following unitless quantity: Utilization := Output achieved ÷ Capacity paid for." The reality, however, is that most organizations achieve only 10-20% GPU allocation utilization when running at peak demand, according to the 2024 State of AI Infrastructure at Scale report.
Traditional approaches to this problem involve fixed over-provisioning, which leads to low utilization, or reactive auto-scaling, which introduces latency during demand spikes. As Modal's team notes, "If allocation is slow, utilization and QoS suffer" during these critical moments.
The Solution: A Multi-Layered Approach to Fast Inference Startup
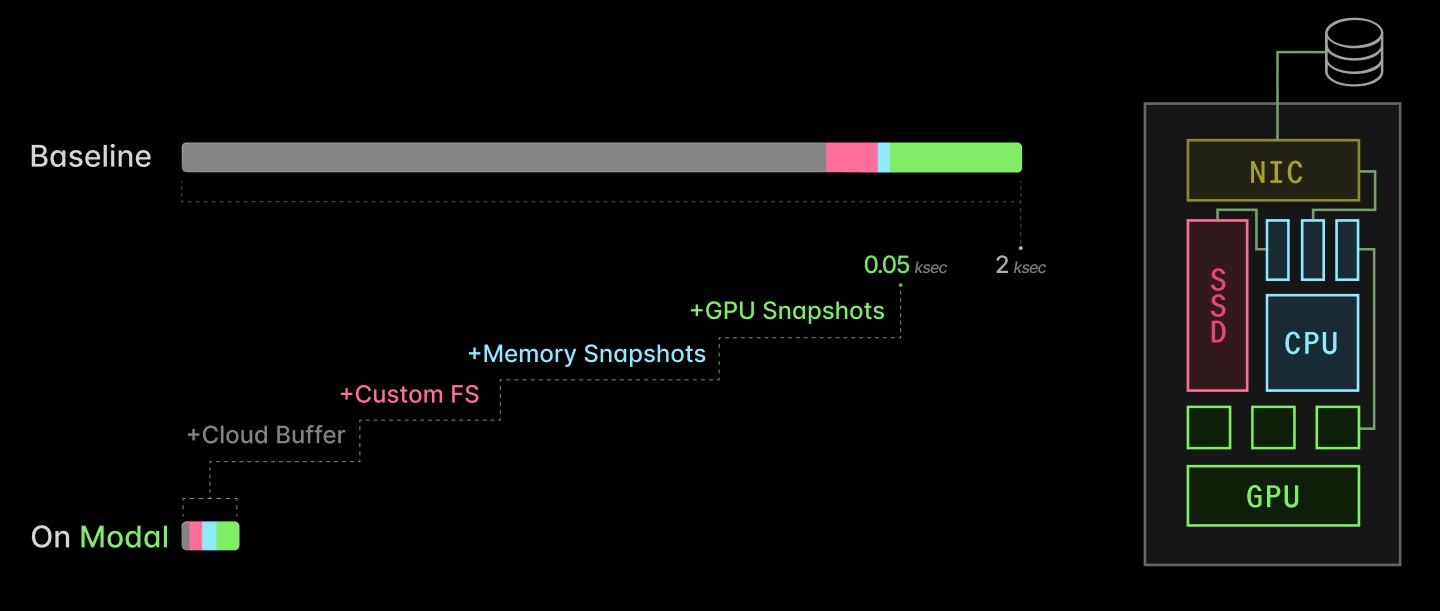
Modal's approach addresses the entire stack from cloud storage to GPU memory, targeting each bottleneck in the inference cold start process:
Cloud Buffers: Instead of provisioning instances on-demand, Modal maintains a buffer of healthy, idle GPUs that can immediately take on new work. This removes the minutes-to-tens-of-minutes delay from instance allocation and health checks that plagues traditional approaches.
Custom Filesystem (ImageFS): Modal developed a custom filesystem using libfuse that serves container images lazily from a multi-tiered, content-addressed cache. This reduces container startup time from minutes to seconds by only loading essential metadata initially and deferring the rest.
Checkpoint/Restore: For host-side initialization, Modal uses checkpoint/restore techniques to fast-forward through CPU-side initialization. By capturing and restoring process state (heap, threads, file descriptors), they can recreate running applications faster than starting from scratch.
CUDA Checkpoint/Restore: The most significant improvement comes from checkpointing and restoring GPU contexts directly, skipping the minutes-long initialization process for neural networks and inference engines.
Together, these optimizations reduce inference server startup times from what could be 2,000 seconds (over 30 minutes) to just 50 seconds—a 40x improvement.
Market Impact and Adoption
Modal's approach enables "truly serverless" AI applications where provisioned supply can tightly match demand, dramatically improving both utilization and quality of service. This has significant implications for the economics of AI deployment.
The company reports running their system at the scale of tens of millions of replicas across many use cases. In the last three months (February-April 2026), they've restored approximately 35 million CPU snapshots and 15 million CPU+GPU snapshots, used by hundreds of distinct organizations.
One notable customer is Reducto, a document processing platform that uses vision-language foundation models. Modal's technology allowed Reducto to scale document processing seamlessly up to thousands of GPUs, reducing cold starts from about 70 seconds to just 12 seconds—a six-fold improvement.
Funding and Trajectory
Modal, founded by Erik Bernhardsson (CEO) and Akshat Bubna (CTO), has developed its technology over five years of deep engineering work. While the exact funding amount isn't specified in the provided content, the company's approach represents a significant advancement in AI infrastructure optimization.
The company's philosophy emphasizes transparency, with Bernhardsson noting, "we believe that secrecy is a bad moat. And if more people learn how to use GPUs efficiently, there will be more available in the market for us!"
Modal offers $30 of free usage credits per month for new users and has attracted customers across various domains including physical intelligence, media generation, financial services, and content platforms.
The Future of AI Infrastructure
Modal's work addresses a fundamental challenge in the AI era: how to efficiently utilize the increasingly expensive and scarce computational resources that power modern AI applications. By reducing cold starts and enabling truly serverless AI, Modal's approach could democratize access to advanced AI capabilities while improving the economics of AI deployment.
As the company continues to develop their technology—exploring potential improvements like RDMA networks and multi-GPU snapshotting—they represent a new generation of infrastructure providers focused specifically on the unique demands of AI workloads.
For organizations struggling with GPU utilization and inference latency, Modal's approach offers a path to more efficient, responsive AI applications without the need for massive over-provisioning or complex capacity planning. You can learn more about their technology on the Modal blog or try it with their free tier.
The authors would like to thank Vikram Mailthody, Steven Gurfinkel, Stephen Jones, Radostin Stoyanov, Rodrigo Bruno, and Jordan Sassoon for their input.
Comments
Please log in or register to join the discussion