
OpenAI's new GPT-5.3-Codex-Spark model runs at 1,000 tokens per second on Cerebras WSE-3 chips, completing coding tasks in 9 seconds versus 43 seconds on traditional hardware.
OpenAI has unveiled GPT-5.3-Codex-Spark, a research preview coding assistant that achieves unprecedented inference speeds of 1,000 tokens per second when running on Cerebras' wafer-scale chips. This marks the first public collaboration between OpenAI and Cerebras, combining OpenAI's model capabilities with Cerebras' massive WSE-3 (Wafer-Scale Engine 3) architecture.
In a demonstration that highlights the performance difference, OpenAI showed GPT-5.3-Codex-Spark completing a "build a snake game" task in just 9 seconds, compared to nearly 43 seconds for the standard GPT-5.3-Codex model running on conventional hardware. The side-by-side comparison clearly demonstrates the speed advantage of the Cerebras-backed Spark model.
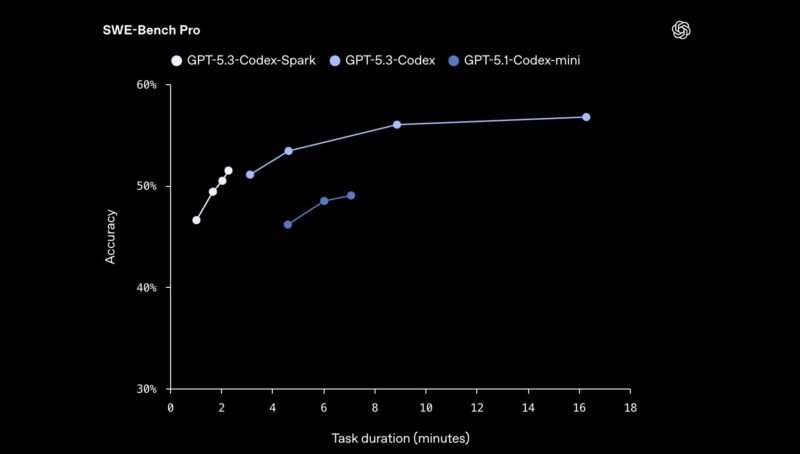
According to OpenAI, the Spark model not only delivers superior speed but also higher quality outputs compared to the GPT-5.1-Codex model. This performance leap is particularly significant for agentic AI workflows where faster task completion translates directly to more efficient operations.
The Cerebras WSE-3 Architecture
The performance gains come from running on Cerebras' Wafer-Scale Engine 3, a chip that takes the largest possible square from a silicon wafer and powers it as a single integrated unit rather than cutting it into smaller chips. This approach creates a massive processing surface that can handle inference workloads at unprecedented speeds.

Cerebras has developed specialized liquid cooling solutions to manage the thermal output of these enormous chips. The company's approach involves innovative cooling techniques that were detailed in coverage from SC22, where the cooling infrastructure was shown to be integral to the system's operation.
Implications for AI Workflows
The speed improvements have practical implications for developers and organizations building AI-powered workflows. Tools like n8n and OpenClaw, which automate complex processes, stand to benefit significantly from faster inference times. When AI agents can complete tasks in seconds rather than minutes, entire workflows become more responsive and efficient.
This development also represents a shift in how we think about coding assistance. A task that might have taken a developer hours of learning and implementation time just a quarter-century ago can now be accomplished with a simple prompt and completed in under 10 seconds. The barrier to creating functional applications continues to lower as inference speeds increase.
Looking Forward
The collaboration between OpenAI and Cerebras suggests a growing trend toward specialized hardware partnerships in the AI industry. As models become more capable and workloads more demanding, the combination of cutting-edge model architecture with purpose-built hardware may become increasingly common.
For organizations building agentic AI systems or complex automation workflows, the availability of faster inference solutions like GPT-5.3-Codex-Spark on Cerebras hardware could be transformative. The ability to execute coding tasks and other AI operations at 1,000 tokens per second opens new possibilities for real-time AI applications and responsive agent systems.
The success of this collaboration validates Cerebras' wafer-scale approach, which has been in development for years. As Andrew Feldman, CEO of Cerebras Systems, noted in earlier interviews, the company's vision of wafer-scale computing is finally seeing real-world validation through partnerships with major AI players like OpenAI.

The announcement represents more than just a speed benchmark—it's a glimpse into how AI infrastructure is evolving to meet the demands of increasingly sophisticated applications. As inference speeds continue to increase, we can expect to see more complex tasks being offloaded to AI systems, further accelerating the pace of software development and automation.
Comments
Please log in or register to join the discussion