
At CES 2026, Phison demonstrated its aiDAPTIV+ technology transforming consumer PCs into capable AI workstations, achieving 10x faster inference by offloading key-value cache to flash memory. The solution enables 120B parameter models to run on 32GB systems instead of requiring 96GB, with major OEMs like Acer, MSI, and even Nvidia showing working demos.
From Enterprise Proof-of-Concept to Consumer Reality

Phison's aiDAPTIV+ technology has undergone a fundamental strategic shift between its mid-2024 introduction and its CES 2026 showcase. Initially positioned as an enterprise solution for training large models on limited memory budgets, the technology now targets client PCs with entry-level or integrated GPUs. This pivot addresses a critical bottleneck: the widening gap between AI model memory requirements and consumer hardware capabilities.
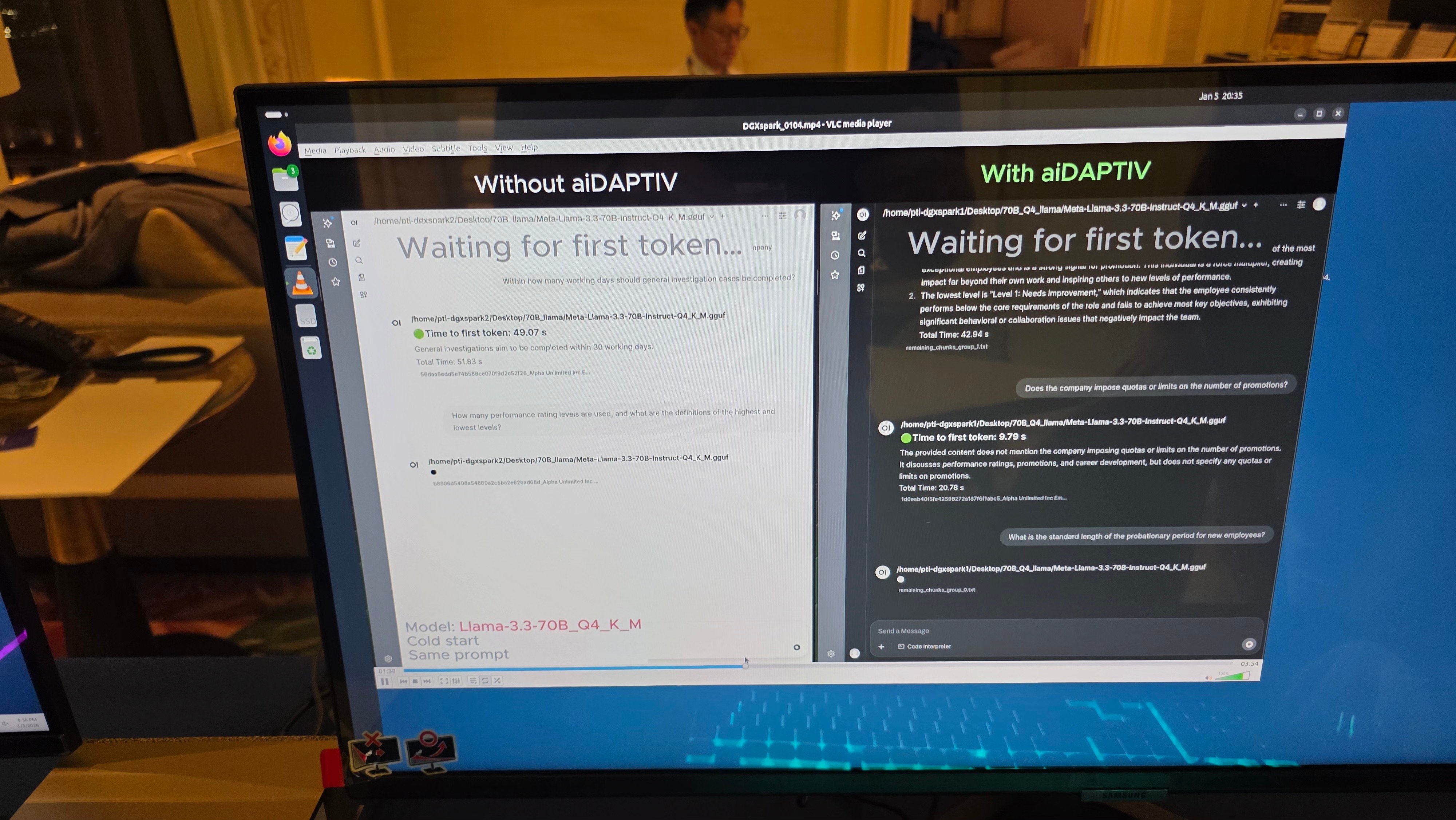
The core problem aiDAPTIV+ solves stems from how modern AI inference operates. During inference, models generate and store key-value (KV) pairs in GPU memory for each token processed. When context windows exceed available VRAM—which happens frequently with long conversations or complex agentic tasks—systems must evict older KV entries. If those tokens are needed again (common in multi-turn dialogues or iterative reasoning), the GPU recomputes them from scratch, creating massive inefficiency.
Phison's solution treats NAND flash as a managed memory tier alongside DRAM. Instead of discarding evicted KV pairs, the system writes them to an AI-aware SSD. When tokens are referenced again, they're retrieved from flash rather than recomputed. This approach mirrors how operating systems use page files for RAM overflow, but optimized specifically for AI tensor operations.
Technical Implementation: Hardware-Software Co-Design

aiDAPTIV+ requires three integrated components:
- AI-aware SSD controller: Phison's advanced controller with firmware optimized for low-latency tensor access patterns
- Specialized firmware: Handles KV cache management, wear leveling for frequent writes, and prioritization of hot tokens
- Software stack: Integrates with PyTorch, TensorFlow, and ONNX Runtime to intercept and redirect cache operations
The implementation is designed for plug-and-play deployment. PC manufacturers can integrate the stack without rewriting applications, making it viable for OEMs targeting developer and power-user segments. For Phison, this creates a dual revenue stream: controller sales plus licensing fees for the aiDAPTIV+ software stack.
Performance Claims and Real-World Demonstrations

Phison's internal benchmarks show dramatic improvements on memory-constrained systems:
- 10x faster inference: Measured as time-to-first-token reduction on models exceeding VRAM capacity
- 3x model size increase: 120B parameter MoE models running on 32GB DRAM systems
- Power efficiency gains: Reduced memory pressure lowers GPU power draw during sustained inference
- Context length extension: Models can maintain 4-8x longer conversation histories before degradation
The most compelling demo at CES 2026 showed Acer running gpt-oss-120b—a 120-billion-parameter model—on a laptop with only 32GB of system memory. Without aiDAPTIV+, this model would require approximately 96GB of DRAM to maintain acceptable performance, putting it far beyond consumer hardware.
The technology particularly benefits Mixture of Experts (MoE) architectures, where only a subset of parameters activate per token. In conventional systems, entire models must reside in memory even though most parameters sit idle. aiDAPTIV+ keeps inactive expert sub-networks in flash, swapping them in only when needed. This explains how Phison achieves the 3x memory reduction claim.
Market Implications: Democratizing Local AI
The shift from enterprise to client PCs opens substantial addressable markets:
For Developers: Small development shops and independent AI engineers can iterate on large models locally without renting cloud instances. A 120B parameter model on a laptop changes the economics of fine-tuning and prompt engineering.
For Businesses: Small-to-medium enterprises gain access to private AI deployment. Running models locally eliminates data privacy concerns and cloud egress costs while maintaining performance comparable to cloud-hosted solutions.
For PC Makers: Creates a premium differentiation vector. Systems branded with "aiDAPTIV+ Ready" can command higher margins, especially in the growing AI developer workstation segment.
For Consumers: High-end AI capabilities trickle down to mainstream hardware. Users with integrated graphics or mid-range GPUs can run models previously requiring data-center GPUs.
Competitive Landscape and Partnership Strategy

Phison's partnership roster at CES 2026 included notable names: Acer, Asus, Corsair, Emdoor, MSI, and critically, Nvidia. The Nvidia inclusion is significant—Nvidia's participation suggests recognition that memory limitations affect even their high-end GPUs, and that software-hardware co-optimization is necessary regardless of silicon vendor.
This positions aiDAPTIV+ as a cross-platform solution rather than a proprietary lock-in. For AMD and Intel systems, the technology could extend the viability of their integrated graphics solutions for AI workloads, potentially disrupting the discrete GPU upgrade cycle.
Implementation Challenges and Trade-offs
While the concept is elegant, practical deployment involves trade-offs:
Latency: Flash memory access is slower than DRAM. Phison's firmware must intelligently predict which tokens will be reused to pre-fetch them, or accept that some operations will have higher latency than pure DRAM systems.
SSD Endurance: Frequent KV cache writes could accelerate NAND wear. Phison's controller must implement sophisticated wear-leveling and potentially use SLC caching modes to extend drive lifespan.
Model Compatibility: Not all inference frameworks support KV cache offloading. Phison needs broad framework adoption for the technology to be transparent to developers.
Performance Variance: Gains depend heavily on access patterns. Models with repetitive token reuse see massive benefits; models with strictly sequential processing see minimal improvement.
Technical Deep Dive: How KV Cache Offloading Works
To understand why aiDAPTIV+ is transformative, consider a typical inference scenario:
Initial Processing: Model processes 1,000 tokens, generating KV pairs for each. These occupy 8GB of VRAM.
Context Overflow: As processing continues to token 2,000, available VRAM fills. Traditional systems evict tokens 1-500 to make room.
Context Retrieval: At token 2,100, the model references information from token 200. Traditional system recomputes KV pairs for tokens 1-500 from scratch, wasting compute.
aiDAPTIV+ Path: Evicted tokens 1-500 are written to flash. At token 2,100, the system retrieves them in ~50μs (NVMe) instead of recomputing in ~5ms (GPU compute), achieving 100x speedup for that operation.
The cumulative effect across thousands of such retrievals yields the 10x overall inference acceleration.
Future Trajectory
Phison's CES 2026 demonstrations suggest the technology has moved beyond prototype status. With major OEMs showing working systems, market availability appears imminent. The next evolutionary step likely involves:
- CXL Integration: Using Compute Express Link to make flash memory appear as addressable memory space rather than storage
- QLC NAND Optimization: Leveraging higher-density flash to reduce cost-per-gigabyte for cache storage
- Cloud Hybrid Models: Extending the concept to edge-cloud scenarios where local flash caches cloud model weights
For now, aiDAPTIV+ represents a pragmatic solution to AI's memory wall problem—one that doesn't require waiting for next-generation memory technologies or accepting 10x price increases for GPUs with more VRAM. By treating storage as a memory tier rather than a separate domain, Phison has created a bridge between current consumer hardware and the demands of modern AI models.
The technology's success will depend on whether PC makers embrace it as a standard feature for AI-ready systems, and whether software frameworks integrate support transparently. If CES 2026 demos are any indication, that adoption curve may be steeper than expected.
For more information on Phison's aiDAPTIV+ technology, visit Phison's official product page or explore the technical documentation. For system availability, check with Acer, MSI, and other participating OEMs.
Comments
Please log in or register to join the discussion