SEMamba, a novel speech enhancement model leveraging the innovative Mamba architecture, achieved 4th place among 70 teams in NeurIPS' URGENT 2024 challenge. The universal model handles diverse distortions like noise and reverberation while outperforming benchmarks on multiple metrics, now available via live demo and open-source implementation.
Speech enhancement—the art of isolating clean vocal signals from noisy environments—just witnessed a significant leap forward at NeurIPS 2024. SEMamba, an architecture incorporating the revolutionary Mamba state-space model (SSM), claimed 4th place among 70 competing teams in the conference's URGENT challenge. This breakthrough demonstrates how next-generation sequence modeling can transform audio processing.
The URGENT challenge pushed boundaries by requiring a single universal model to handle diverse distortions including additive noise, reverberation, clipping, and bandwidth limitations across all sampling frequencies—a monumental task given the 1.5TB dataset. SEMamba excelled across 13 evaluation metrics spanning non-intrusive, intrusive, and task-dependent assessments. As lead researcher Rong Chao noted, "Mamba's efficient long-sequence modeling unlocks new potential for real-time, high-fidelity speech enhancement in unpredictable environments."
Why Mamba Matters for Audio
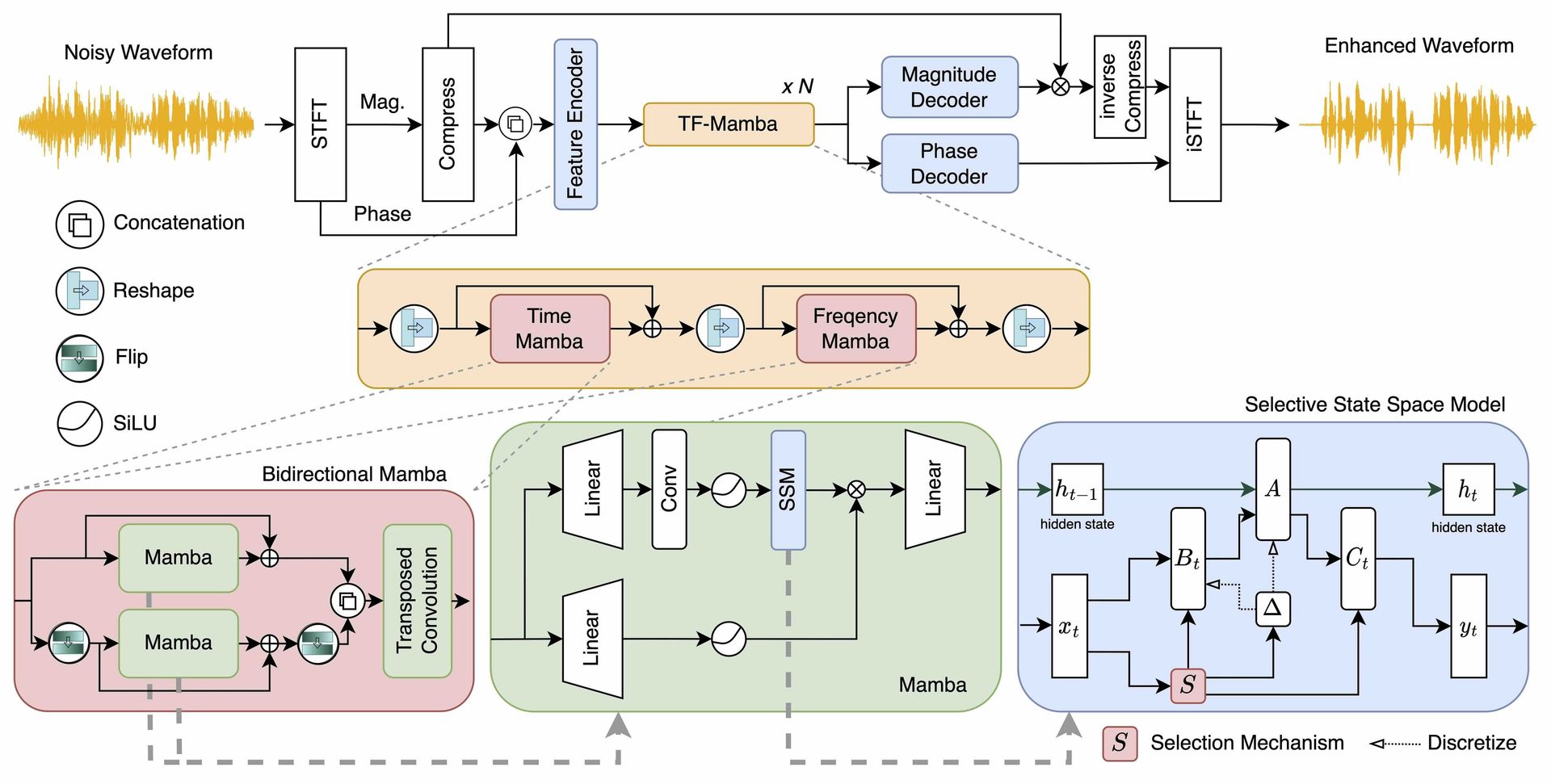
Unlike traditional transformers, Mamba's selective state spaces dynamically adjust to input content, dramatically improving computational efficiency for long audio sequences. SEMamba adapts this architecture to spectrogram processing, enabling nuanced noise suppression while preserving speech integrity—a critical balance often missed by convolutional or recurrent approaches.
Performance That Speaks Volumes
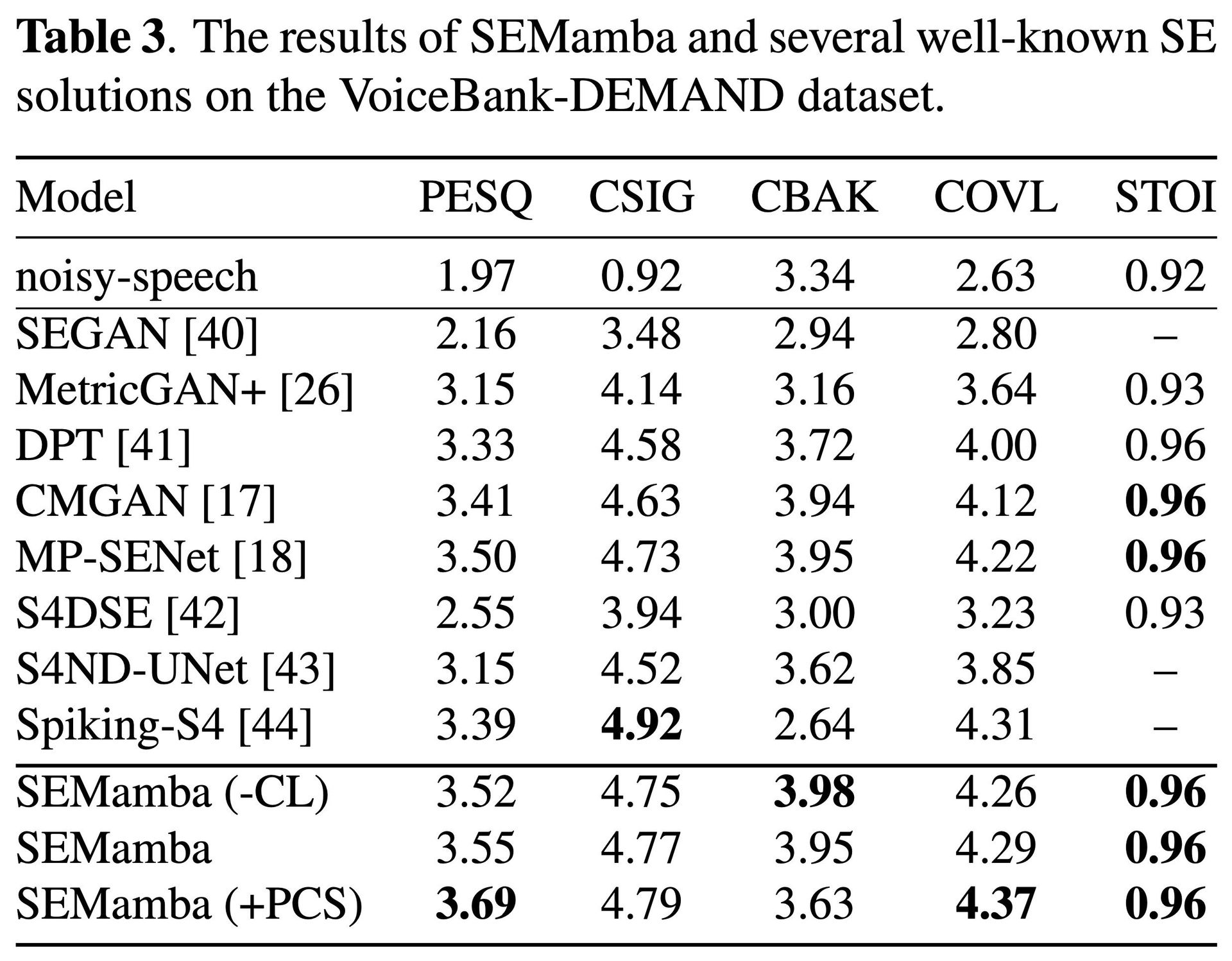
Quantitative results reveal SEMamba's robustness:
- DNS-2020 Dataset: PESQ 3.66, STOI 0.98
- VCTK-Demand: PESQ 3.56, near-human quality (CSIG 4.73)
The model's secret weapon? Perceptual Contrast Stretching (PCS), a technique enhancing spectral contrast that boosted PESQ scores by 0.19 on VCTK-Demand when applied post-processing. Researchers also validated practical utility via ASR integration, showing reduced Word Error Rates with OpenAI Whisper.
Engineering for Real-World Deployment
Accessibility drives SEMamba's design:
- 🚀 Live Hugging Face Demo: Process custom audio via Hugging Face Spaces
- 🐳 Docker Containers: Pre-built images for x86 (A100/RTX 4090) and ARM (NVIDIA GH200) systems
- ⚙️ CUDA 12+ Optimization: Requires modern RTX GPUs (V100/GTX 1080 Ti unsupported)
The team actively maintains compatibility, recently adding support for Mamba-SSM 2.2.x and offering an experimental Mamba-2 branch.
The Road Ahead
SEMamba’s NeurIPS recognition signals a paradigm shift: State-space models now rival transformers in complex audio tasks while offering computational advantages. As noise-robust speech processing becomes critical for applications from telemedicine to edge devices, this open-source milestone (GitHub) provides a foundational tool for researchers and engineers alike—proving that sometimes, the clearest signals emerge from the noisiest challenges.
Source: SEMamba GitHub Repository
Comments
Please log in or register to join the discussion