
DataHaskell's Q1 2026 update reveals a strategic pivot toward community-driven growth and targeted technical improvements, focusing on reducing friction for data scientists while leveraging Haskell's unique strengths in symbolic AI and type-safe programming.
As the Haskell community emerges from the holiday slowdown, DataHaskell has published a comprehensive roadmap that reflects months of intensive listening and strategic refinement. The organization's Q1 2026 update reveals a fundamental shift in focus: from broad ecosystem parity with Python to targeted exploitation of Haskell's unique compositional and type-system advantages in data science workflows.
The core insight driving DataHaskell's evolution is that community and ecosystem friction—not technical capability—represent the primary bottleneck to adoption. Through extensive interviews with ecosystem veterans including Ed Kmett, Michael Snoyman, Bryan O'Sullivan, and others, the team discovered that traditional metrics of success (library coverage, feature completeness) matter less than experiential measures like "time to first plot" and "time to first successful notebook." This finding has catalyzed a strategic pivot toward symbolic AI tooling for tabular data, where Haskell's typed DSLs and algebraic modeling can provide genuine advantages without attempting to replicate the entire Python ecosystem.
The Listening Sprint: Understanding the Real Bottlenecks
DataHaskell's Q4 2025 listening sprint engaged key figures across the Haskell ecosystem to understand both progress and persistent gaps. The conversations with Sam Stites, Laurent P. René de Cotret, Ed Kmett, Michael Snoyman, Bryan O'Sullivan, Tom Nielsen, and Aleksey Khudyakov revealed that ecosystem success requires coordinated effort across multiple dimensions simultaneously. As the team notes, "Very few people will touch the ecosystem unless they can read their favourite data format, or plot their results, or run machine learning models easily, or have everything work in Jupyter."
This insight has profound implications for how DataHaskell approaches technical development. Rather than focusing on individual library excellence, the organization now prioritizes end-to-end workflow completeness. The team recognized that even sophisticated Haskell developers abandon the ecosystem when basic data ingestion, visualization, or notebook integration fails. This understanding has led to a new principle: the ecosystem must succeed holistically for any single use case to thrive.
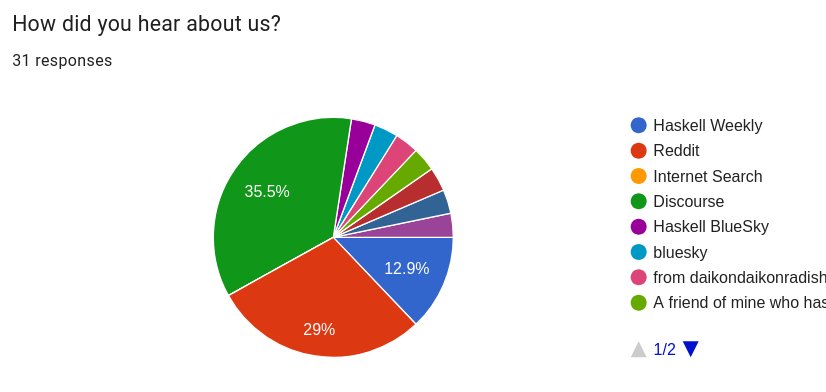
The survey data from DataHaskell's Discord community provides quantitative support for this strategic shift. Among 31 respondents from 110 Discord members, the overwhelming preference was for "low-friction, bite-sized ways to help" rather than long-term maintainer commitments. This suggests the Haskell data science community is naturally trending toward many casual contributors rather than a small set of frequent maintainers—a pattern that fundamentally changes how the organization structures its contribution funnel.
Symbolic AI: Haskell's Natural Domain
DataHaskell's current strategic bet centers on symbolic AI tooling for tabular data. This represents a deliberate choice to avoid direct competition with Python's scikit-learn or PyTorch ecosystem, instead carving out a niche where Haskell's advantages become undeniable.
Symbolic AI, in this context, refers to tools that build interpretable models by searching over programs rather than fitting opaque parameters. The technical scope includes three core capabilities:
Feature synthesis automatically generates meaningful features from raw columns with mathematical constraints. Unlike Python's feature engineering libraries that often rely on runtime experimentation, Haskell's type system can encode constraints at compile time, preventing invalid transformations before they reach production.
Interpretable model search generates compact decision rules, trees, or expressions that remain human-inspectable. The key advantage here is Haskell's ability to represent models as algebraic data types, enabling formal verification, diffing, and safe transformations. When a model changes, you can reason about exactly what changed mathematically.
Program optimization safely simplifies or rewrites model expressions—removing dead branches, canonicalizing expressions, enforcing constraints like monotonicity. Haskell's rewrite rules and type-directed optimization provide a foundation for guaranteed-safe model transformations that would require extensive testing in dynamically-typed languages.
This direction leverages Haskell's strengths in typed DSLs, algebraic modeling, and compositionality. Rather than competing on breadth, DataHaskell is competing on depth of reasoning about programs and data transformations.
The Onboarding Crisis and DevContainer Solution
One of the most significant technical barriers identified was the installation and toolchain management experience. Despite GHCup's improvements, the ecosystem still presents rough edges, with failed IHaskell installations remaining a common frustration.
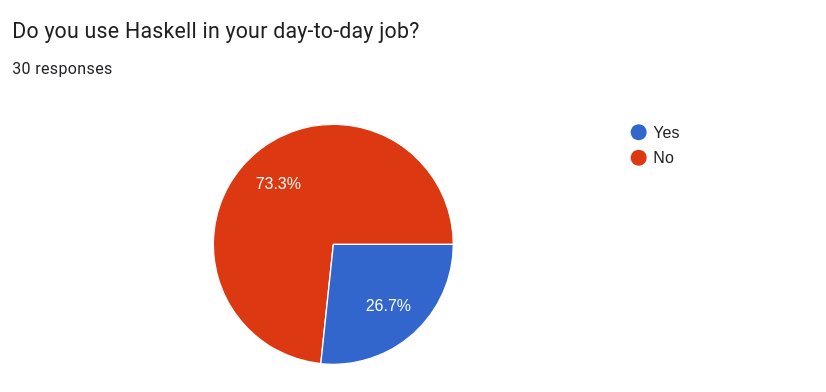
To address this, DataHaskell created a DataHaskell devcontainer and designated it as the "blessed path" for setup. This decision reflects a pragmatic understanding that while Nix offers powerful capabilities, its learning curve adds friction that can derail adoption. The devcontainer approach provides a consistent, reproducible environment that minimizes setup decisions while still allowing for eventual customization.
The focus on "time to first plot"—a metric borrowed from the Julia community—demonstrates DataHaskell's commitment to experiential metrics over technical ones. The goal is to make the initial setup feel "boring in the best sense of the word," reducing cognitive load so users can focus on data work rather than tool configuration.
Community Growth and Contribution Patterns
DataHaskell's engagement strategy has evolved based on survey feedback about how community members want to contribute. The organization is optimizing for:
- Fast feedback loops through structured "try this workflow" prompts
- Clear friction reporting channels for installation issues, notebook problems, and documentation gaps
- Beginner-friendly contribution work with well-scoped tasks
- A steady stream of small, well-defined issues
- Documentation and tutorial tasks with clear completion criteria
- "30-minute tasks" that don't require deep ecosystem knowledge
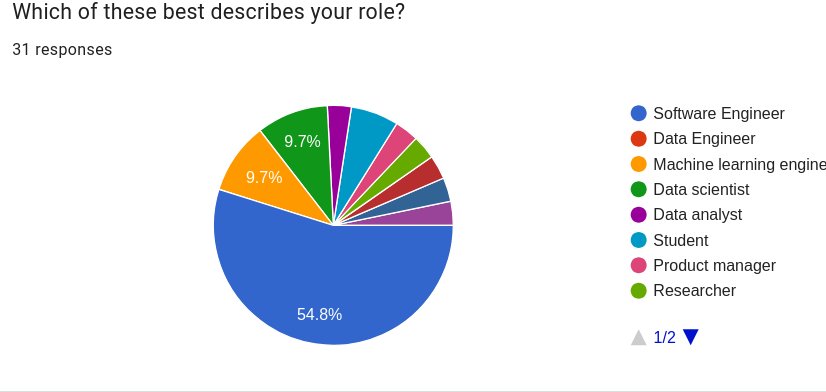
The organization is actively partnering with maintainers in IHaskell, Streamly, cassava, statistics/mwc-random, and HVega to scope out beginner-friendly tasks. Simultaneously, they're identifying longer-term contributors for these libraries, recognizing that sustainable ecosystem growth requires shared ownership.
Engagement with the broader data science community has also been strategic. Jonathan Carroll, a prominent R community member and data scientist, has joined as a core community member, guiding design and prioritization decisions. The collaboration has produced the article "Haskell IS a Great Language for Data Science" and is leading to a book, "Haskell for Data Science," expected in mid-to-early 2026. This bridge-building acknowledges that Haskell's data science future depends on attracting practitioners from other ecosystems, not just converting existing Haskell developers.
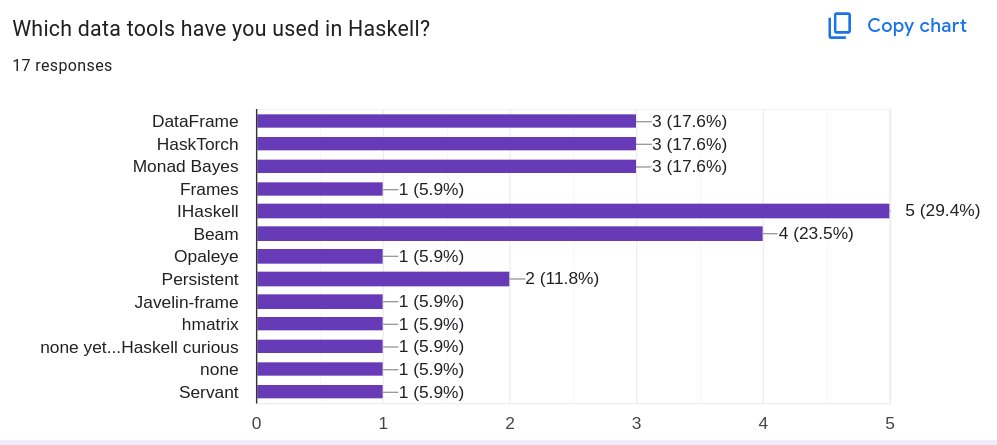
Technical Debt and Ecosystem Coordination
Beyond strategic initiatives, DataHaskell has addressed specific technical pain points across the ecosystem:
- Improved Hasktorch installation experience
- Resolved a decade-old feature request for Poisson sampling
- Updated IHaskell installation instructions
These improvements reflect the principle that ecosystem success requires coordination. A single library's excellence means little if installation fails or documentation gaps prevent usage. However, the team notes that Discord engagement has been "fairly low," making it difficult to mobilize members for these technical tasks. This observation is driving planned outreach mechanism experiments throughout 2026.
The 2026 Roadmap: Four Concrete Priorities
DataHaskell's roadmap for 2026 prioritizes practical outcomes over ambitious scope:
1. Boring onboarding: Reduce setup friction, tighten the blessed path, and make "time to first plot" consistently short and reliable.
2. Golden workflows: Publish a small set of end-to-end workflows that reflect real usage patterns. These should cover ingestion, transformation, visualization, and modeling honestly—acknowledging gaps while demonstrating complete, repeatable paths.
3. Contribution funnel: Replace undirected calls for help with a visible, regularly updated board of bite-sized tasks and well-scoped bounties. The goal is to make one-hour contributions feel immediately useful while providing clear next steps for continued involvement.
4. Notebook ergonomics: Improve IHaskell defaults, clarify installation and troubleshooting documentation, and reduce silent failures or confusing states. For many users, notebooks represent the front door to the ecosystem.
5. Pilot partnerships: Collaborate with 1-2 production teams using Haskell for data work. The goal is to ship fixes quickly based on real pain points, making the roadmap sharper and ecosystem work easier to justify.
Looking Forward
DataHaskell's Q1 2026 update reveals an organization that has moved beyond initial enthusiasm toward disciplined, community-informed strategy. By focusing on symbolic AI tooling where Haskell's type system and compositional nature provide genuine advantages, and by optimizing contribution patterns for the many rather than the few, DataHaskell is building a sustainable foundation for Haskell's role in data science.
The invitation to pilot partners is explicit: if your company uses Haskell in production or wants to, DataHaskell wants to collaborate closely, ship improvements quickly, and learn what actually matters in day-to-day use. This pragmatic, user-driven approach—combined with the technical depth of symbolic AI tooling—represents Haskell's most promising path toward becoming a practical option for day-to-day data work.
The organization's primary leads, Michael Chavinda (with a decade of fraud detection and ML experience at Google and FIS Global) and Jireh Tan (data scientist with experience at Facebook and Gojek), bring both industry credibility and genuine passion for Haskell's potential. Their shared vision is clear: not just a cool idea, but a toolkit people actually reach for.
As the Haskell data science ecosystem evolves in 2026, DataHaskell's focus on reducing friction, building contribution pathways, and leveraging symbolic AI strengths provides a roadmap for sustainable growth. The question is no longer whether Haskell can be used for data science, but how quickly the community can make it the obvious choice for teams that value correctness, composability, and reasoning about programs.
Comments
Please log in or register to join the discussion