Discover how language model embeddings solve the perennial problem of messy user-entered job titles by mapping free-text entries to standardized occupational categories. This technical deep dive demonstrates a production-ready pipeline using O*NET data and JobBERT-v2 to bring structure to chaos without predefined rules or external APIs.
User-entered data remains one of the most persistent challenges in operational systems. When it comes to job titles—critical for segmentation, personalization, and analytics—the chaos is legendary: "nurse," "RN," "ER Nurse," and "home health nursing" all represent similar roles but defy simple categorization. For organizations relying on this data, the lack of structure undermines everything from lead scoring to user onboarding.
Why Traditional Methods Fall Short
Previous approaches involved:
- Manually curated normalization rules (brittle and high-maintenance)
- External APIs (costly and privacy-invasive)
- Oversimplified keyword matching (fails for nuanced titles)
As Matthew Hodges demonstrates, language model embeddings offer an elegant solution by capturing semantic relationships rather than relying on exact string matches.
The Embedding-Powered Pipeline
Step 1: Curate a Target Taxonomy
The Occupational Information Network (O*NET) provides a robust foundation with standardized job titles and common variations. After enriching it with non-employed categories (Retired, Unemployed), we create "Long Title" descriptors:
mask = onet_df["Short Title"].eq("")
onet_df["Long Title"] = np.where(
mask,
onet_df["Title"] + " aka " + onet_df["Alternate Title"],
onet_df["Title"] + " aka " + ...
)
Step 2: Encode Semantic Meaning
Using JobBERT-v2—a model fine-tuned specifically for occupational text—we generate embeddings for all Long Titles:
model = SentenceTransformer("TechWolf/JobBERT-v2")
onet_df["embedding"] = list(
model.encode(onet_df["Long Title"].tolist(), normalize_embeddings=True)
)
These embeddings transform job titles into numerical vectors where semantic similarity translates to mathematical proximity. For example:
emb('Software Developer')andemb('Game Engineer')show high cosine similarity (0.87)emb('Software Developer')andemb('Shipping Agent')are nearly orthogonal (0.09)
Step 3: Real-World Matching
When processing messy input (like campaign donor occupations from ActBlue), we:
- Embed user entries
- Compute similarity against O*NET vectors
- Map to the closest standardized title
The GPU-accelerated matching handles scale efficiently:
# On GPU
sims = user_embeddings_batch @ onet_embeddings.T
best_match_indices = sims.argmax(dim=1)
Results That Speak Volumes
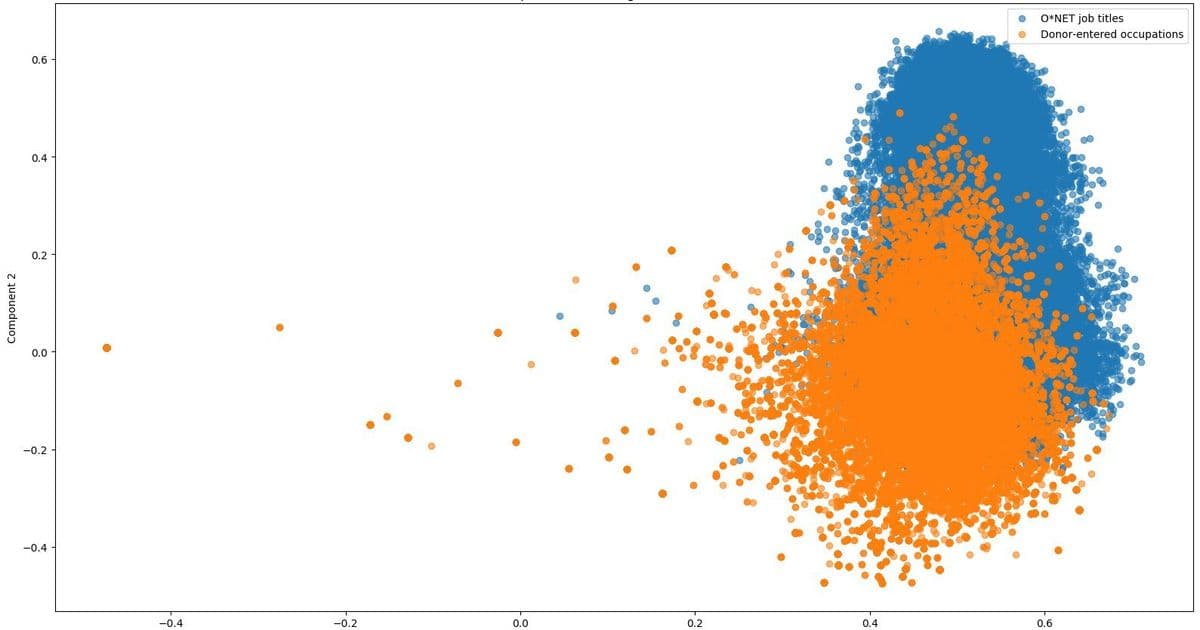
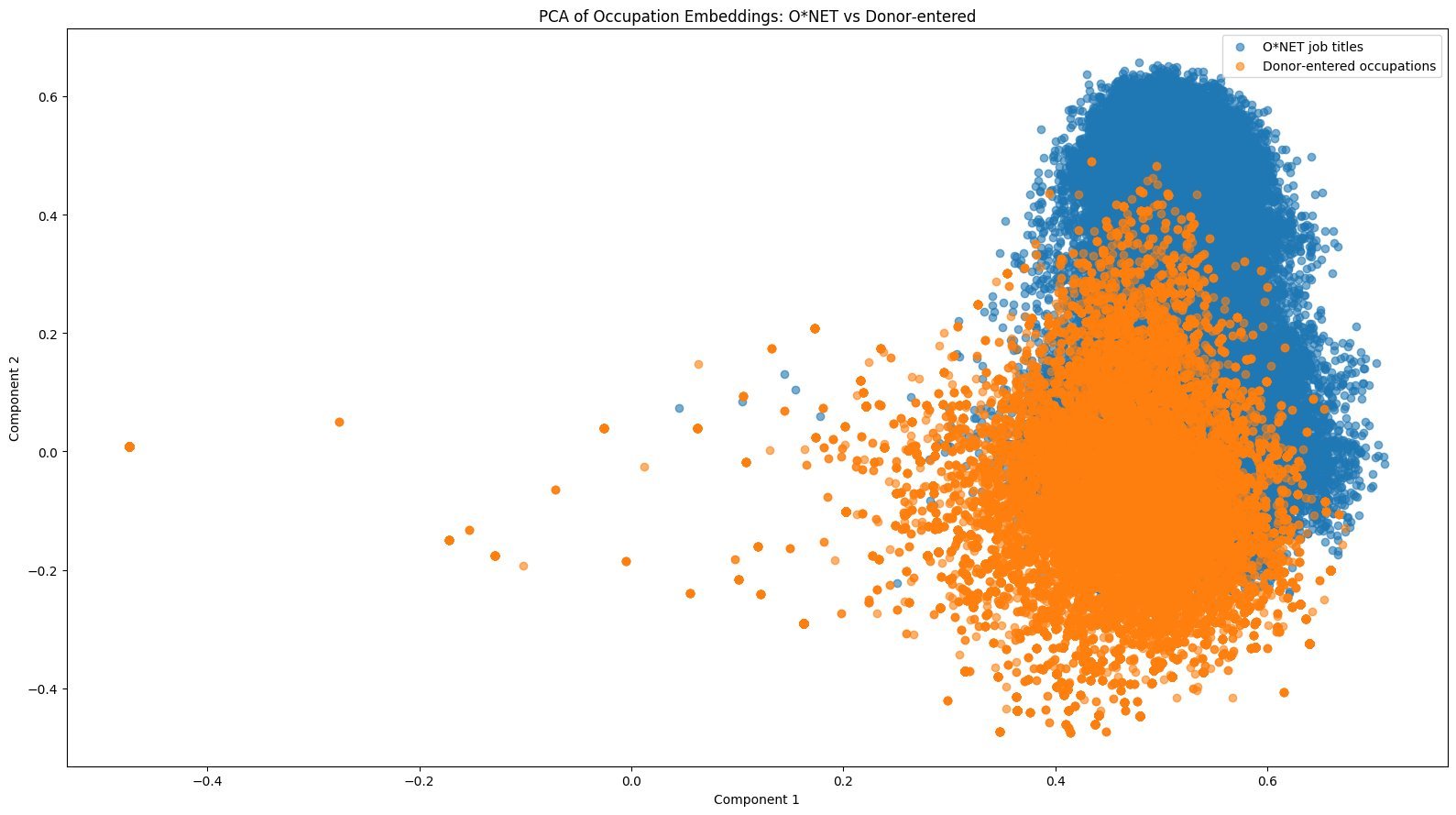 PCA visualization shows donor-entered occupations (orange) clustering around standardized ONET titles (blue)*
PCA visualization shows donor-entered occupations (orange) clustering around standardized ONET titles (blue)*
In real donor data:
| User Entry | Normalized Title |
|---|---|
| "Nursing" | Registered Nurses |
| "Database Analyst" | Database Administrators |
| "Nonprofit" | Fundraisers |
| "Server" | Food Servers, Nonrestaurant |
Even edge cases yield sensible mappings:
normalize("code ninja") # → Computer Programmers
normalize("commodities trader") # → Financial Services Sales Agents
Why This Matters for Developers
- No training data needed: Leverages pre-existing taxonomies
- Privacy-preserving: All processing occurs locally
- Adaptable: Swap O*NET for any domain-specific ontology
- Computationally efficient: Batch processing on GPUs handles large datasets
As Hodges notes: "Language models are surprisingly adept at modeling occupational language—even when user entries are inconsistent or idiosyncratic." This approach transforms a perennial data headache into structured, actionable intelligence.
Source: Matthew Hodges
Comments
Please log in or register to join the discussion