
Embedding dimensions have ballooned from 300 to over 4000, driven by transformer architectures and GPU optimizations. This shift reflects the AI industry's balancing act between model performance and computational efficiency. We unpack the technical forces behind this growth and its implications for developers.
The Dimensionality Explosion: How Embedding Sizes Evolved from Word2Vec to GPT-4 and Beyond

Embeddings—compressed numerical representations of text, images, or audio—are the unsung workhorses of modern AI. They power everything from semantic search to recommendation engines. But their size has undergone a seismic shift. Where 200-300 dimensions once sufficed, today's embeddings routinely exceed 4000 dimensions. Why? The answer lies at the intersection of hardware advances, architectural innovations, and industry commoditization.
The Humble Beginnings: When 300 Dimensions Ruled
Early models like Word2Vec and GloVe settled on ~300 dimensions as a sweet spot. This size balanced computational feasibility with reasonable accuracy for tasks like classification or topic modeling. As Vicki Boykis notes in her analysis, these dimensions weren't arbitrary; they represented a pragmatic compromise:
"We generally, as an industry, understood that somewhere around 300 dimensions might be enough to compress all the nuance of a given textual dataset."
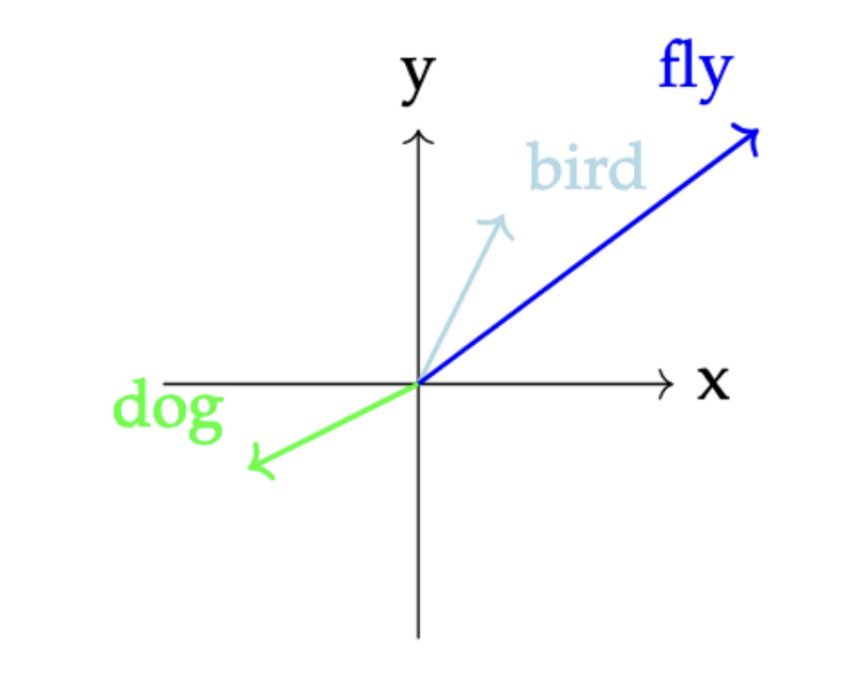
These embeddings were often trained in-house, with hyperparameters guarded like trade secrets. The butterfly analogy illustrates their simplicity: just as we might compare insects by wing color or antenna count, embeddings mapped words like "bird" and "fly" into a shared numerical space.
The Transformer Revolution: GPUs, Attention, and 768 Dimensions
The 2018 release of BERT shattered the status quo. Its transformer architecture introduced 768-dimensional embeddings—a leap enabled by GPU/TPU parallelism. BERT's 12 attention heads each processed 64-dimensional subspaces, optimizing matrix operations across hardware. This wasn't just bigger; it was architecturally intentional:
# BERT-style embedding partitioning
total_dimensions = 768
attention_heads = 12
dimensions_per_head = total_dimensions // attention_heads # 64
The computational cost was staggering: comparing 10,000 sentences required ~65 hours initially. Yet, the payoff—richer semantic understanding—justified the scale. Models like GPT-2 adopted similar dimensions, cementing 768 as the new baseline.
The API Era: Commoditization and the Rise of 1536+ Dimensions
Three forces propelled embedding sizes further:
- HuggingFace's Standardization: Centralized model repositories replaced fragmented research code, enabling replication of larger architectures.
- API-First Embeddings: OpenAI’s 1536-dimensional embeddings (aligned with GPT-3’s 96 attention heads) turned embeddings into on-demand commodities. Competitors like Cohere and Google Gemini followed suit.
- Benchmarking: Platforms like MTEB provided objective performance comparisons, incentivizing dimensionality increases for competitive gains.
Why Bigger? The Trade-Offs Driving Growth
Larger embeddings capture finer-grained relationships but demand heavier resources. The push beyond 4096 dimensions (e.g., in Qwen-3) confronts critical engineering trade-offs:
- Recall vs. Precision: Higher dimensions improve accuracy but inflate inference latency.
- Storage vs. Performance: Vector databases like Postgres or Elasticsearch now handle embeddings, yet scaling to 4000+ dimensions strains infrastructure.
Innovations like matryoshka representation learning (pioneered by OpenAI) address this by prioritizing "core" dimensions. Truncating 50% of embeddings can retain most utility—a nod to the industry’s cyclical push-pull between scale and efficiency.
The New Normal: Embeddings as Commodities
Embeddings have transitioned from proprietary assets to standardized API calls. For developers, this means:
- Faster prototyping with services like OpenAI’s embeddings endpoint.
- Reduced need for custom training, but heightened focus on optimization (e.g., dimensionality reduction).
- Vector databases becoming embedded infrastructure rather than specialized tools.
As embedding dimensions stabilize, the focus shifts to refinement—squeezing more insight from fewer bits. Yet the trajectory remains clear: in AI’s relentless march forward, size isn’t just vanity; it’s the currency of capability.
Source: Adapted from Vicki Boykis' Normcore Tech newsletter.
Comments
Please log in or register to join the discussion