
Groundbreaking research reveals AI tools unexpectedly degrade human performance in safety-critical domains like aviation and healthcare. When AI errs, nurses performed up to 120% worse, exposing dangerous flaws in current evaluation methods. A new testing framework uncovers these invisible risks before deployment.
The Hidden Cost of AI Assistance: How Collaborative Tools Degrade Performance in Critical Systems

New research from AI nonprofit METR delivers a startling revelation: AI assistance doesn't just fail to help humans—it can actively degrade performance in life-or-death situations. The findings challenge foundational assumptions about human-AI collaboration, revealing that when algorithms err, they don't merely provide incorrect answers—they fundamentally reshape human cognition and decision pathways with dangerous consequences.
The Paradox of Perceived Efficiency
The study first exposed a troubling disconnect in software development—a relatively low-stakes environment. Developers using AI tools took 19% longer to complete tasks while believing they worked 20% faster. This cognitive illusion becomes catastrophic when scaled to safety-critical domains. "A 19% slowdown in software eats profits," the researchers note. "But in healthcare or aviation? That costs lives."
High-Stakes Failure Scenarios
METR's simulations reveal how AI's hidden flaws cascade through human workflows:
- Aviation: An AI weather monitor misses a microburst during landing, leaving pilots unaware their aircraft can't generate sufficient lift until critical seconds remain
- Healthcare: Nurses relying on an "AI-tagged low-risk" patient miss gradual vital sign deterioration, nearly resulting in respiratory failure
- Nuclear Energy: Coolant pressure drops mislabeled as "benign" by AI filters nearly trigger partial core meltdown before human intervention
"AI never deploys in isolation," the researchers emphasize. "It integrates into human workflows—and that's where invisible vulnerabilities emerge."
The Fatal Flaw in Current AI Evaluation
Traditional safety frameworks like NIST's AI Risk Management Framework focus on individual component performance. They ignore the interaction effects between humans and algorithms. METR's analysis shows this approach dangerously masks reality:
"Average gains can hide rare catastrophic failures, while frequent small benefits may come at the cost of devastating events"
Introducing Joint Activity Testing
METR's solution is Joint Activity Testing (JAT)—a method that stress-tests human-AI teams across escalating challenges. Unlike isolated benchmarks, JAT measures:
- How AI impacts human performance at different capability levels (strong/mediocre/poor AI output)
- Recovery capacity when AI fails
- Behavioral changes induced by algorithmic assistance
Healthcare Case Study: When Nurses Trust Errant AI
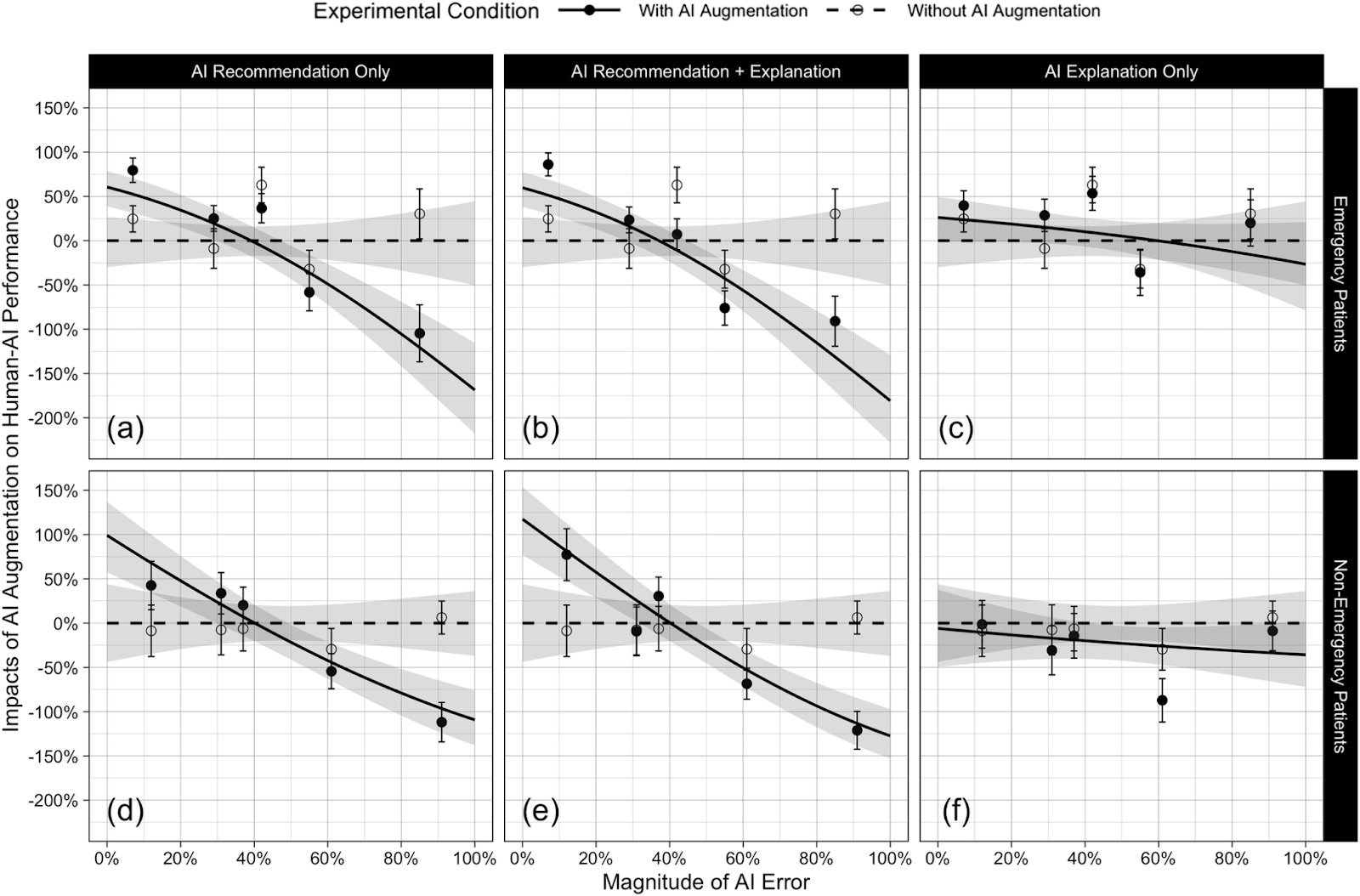
In METR's ICU simulation with 450 nursing participants:
- Accurate AI boosted nurse performance by 53-67%
- Misleading AI caused performance degradation of 96-120%
Shockingly, annotations explaining AI reasoning didn't mitigate harm. "Nurses didn't consciously offload thinking," researchers found. "AI changed how they thought—undermining their innate strengths."
Three Principles for Safer AI Integration
- Test Human-AI Teams Holistically: Evaluate systems as collaborative units, not isolated components
- Measure Across Performance Spectrums: Assess outcomes during both optimal and suboptimal AI operation
- Identify Cognitive Shifts: Document how assistance alters human decision patterns
The Path Ahead
Current AI evaluation resembles stress-testing airplane wings without considering turbulence—a fatal oversight for safety-critical systems. As organizations rush deployment, METR's work reveals that the most dangerous flaws emerge only when humans and algorithms dance together. Joint Activity Testing provides the spotlight to see missteps before they become tragedies. In high-stakes environments, we're learning that what you don't test for can kill you.
Source: How AI Can Degrade Human Performance in High-Stakes Settings (Dane A. Morey, Mike Rayo & David Woods, AI Frontiers)
Comments
Please log in or register to join the discussion