An in-depth analysis of the challenges and implications surrounding attempts to reconstruct improperly redacted PDFs from the Epstein document release, revealing systemic failures in digital redaction processes.

The recent release of Epstein-related documents by the Department of Justice has exposed critical flaws in government digital redaction processes. While public attention has focused on questionable censorship decisions, a more fundamental failure lies in the technical implementation - one that leaves supposedly redacted content potentially recoverable through forensic analysis.
The Base64 Oversight
At the heart of this issue lies the discovery of unredacted base64-encoded PDF attachments within the document dump. These binary email attachments, meant to be transmitted via SMTP, were preserved in their raw encoded form (e.g., EFTA00400459's 76-page base64 block). The DoJ's redaction team apparently failed to recognize that these seemingly random character strings represented actual documents.
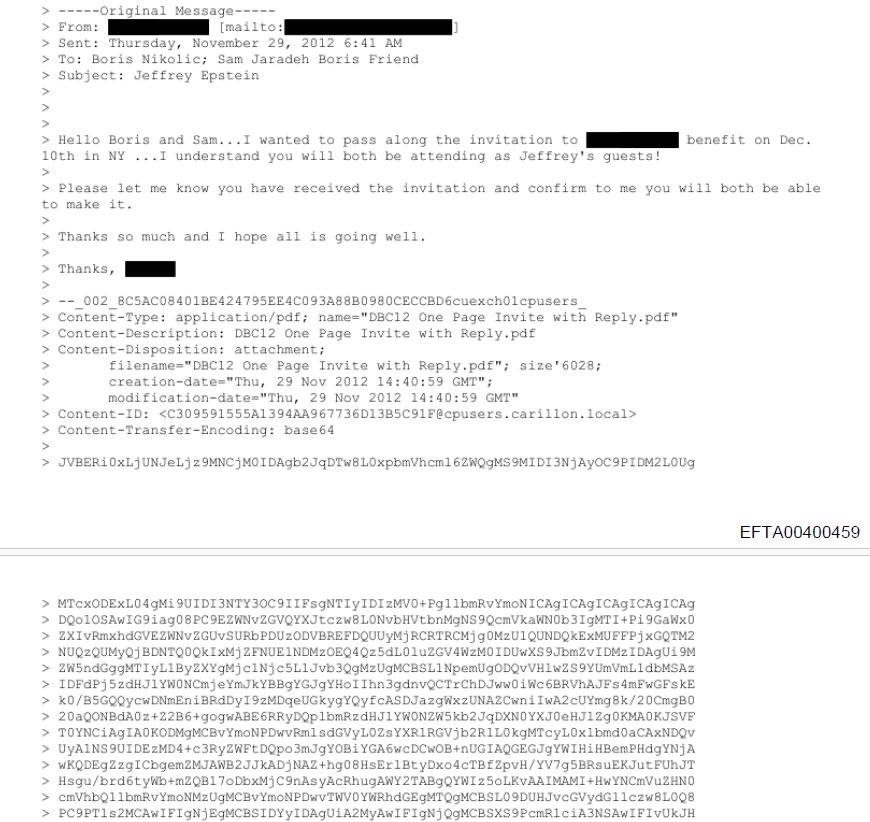
The OCR Obstacle Course
Reconstructing these documents proves exceptionally challenging due to multiple layers of technical incompetence:
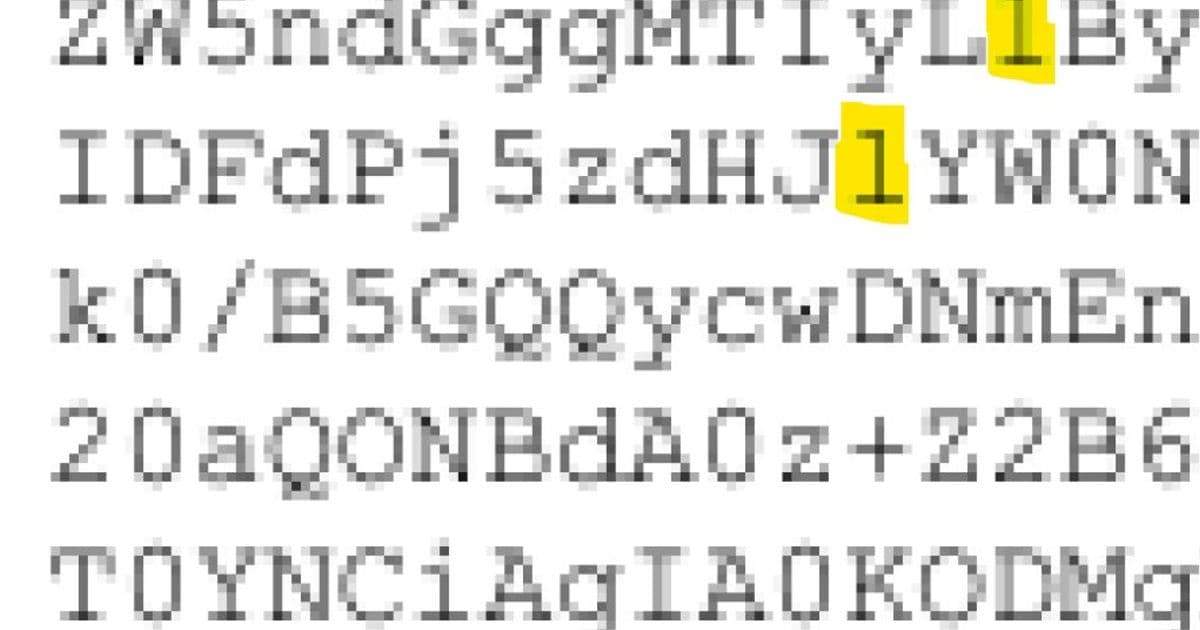
- Generational Loss: The original emails were printed, scanned, and OCR'd, introducing multiple points of quality degradation
- Font Failures: Use of Courier New - with its poor distinction between similar characters (1/l/I) - makes accurate OCR nearly impossible
- Compression Artifacts: Low-quality JPEG scans introduce visual noise that confuses recognition algorithms

Technical Implications
This fiasco reveals several critical issues in government document handling:
- Redaction Theater: Superficial censorship of visible text while leaving machine-readable content intact
- Technical Illiteracy: Failure to recognize common encoding schemes like base64
- Process Failures: Lack of quality control in OCR and digitization workflows
Broader Consequences
The implications extend beyond this specific case:
- Transparency vs Security: Poor redaction undermines both legitimate privacy concerns and public accountability
- Digital Preservation: Highlights the challenges of maintaining document integrity across format conversions
- Font Standards: Demonstrates how typeface choices can have serious real-world consequences
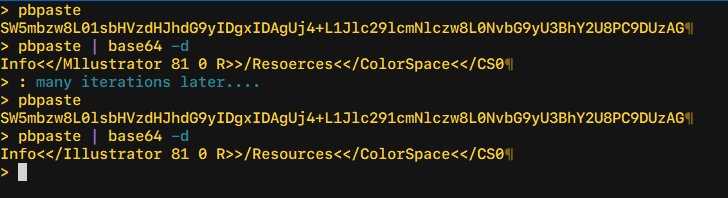
Resources for Further Analysis
For researchers interested in attempting reconstruction:
This case serves as a stark reminder that in the digital age, redaction requires more than black boxes over text - it demands deep technical understanding of how information persists across formats and encodings.
Comments
Please log in or register to join the discussion