
A new open-source project trains language models from scratch using only documents from specific historical periods, creating AI that authentically reflects era-specific vocabulary and worldviews without modern contamination.
In an unconventional approach to reducing AI bias, developer Hayk Grigorian has launched TimeCapsuleLLM, an open-source framework for training language models exclusively on texts from defined historical periods. Unlike fine-tuned models that retain modern knowledge, these models are built from the ground up using documents from specific times and locations—currently focused on London between 1800-1875—resulting in outputs that authentically mirror period-specific language, biases, and perspectives.
Core Methodology: Selective Temporal Training
The project employs Selective Temporal Training (STT), where models ingest only data from rigorously curated historical sources. Grigorian explains the rationale: "Fine-tuning modern models like GPT-2 retains embedded contemporary perspectives. Training from scratch ensures the model doesn't pretend to be historical—it simply is, reflecting the unaltered linguistic and cultural context of its training era."
The workflow involves:
- Data Curation: Collecting public domain texts (books, newspapers, legal documents) from target periods, manually removing OCR errors and modern annotations. The v2 dataset includes 136,344 London documents.
- Custom Tokenization: Building era-specific vocabulary rules via
train_tokenizer.pyto handle archaic phrasing. - Scratch Training: Using architectures like nanoGPT or Microsoft's Phi 1.5, trained from initialization without pretrained weights.
Model Evolution: From Chaotic to Coherent
v0 (187MB data, 16M params) Early outputs showed period vocabulary but incoherent structure:
Prompt: "Who art Henry?"
Output: "I know that man, I have did not a black, the storm."
v0.5 (435MB data, 123M params)
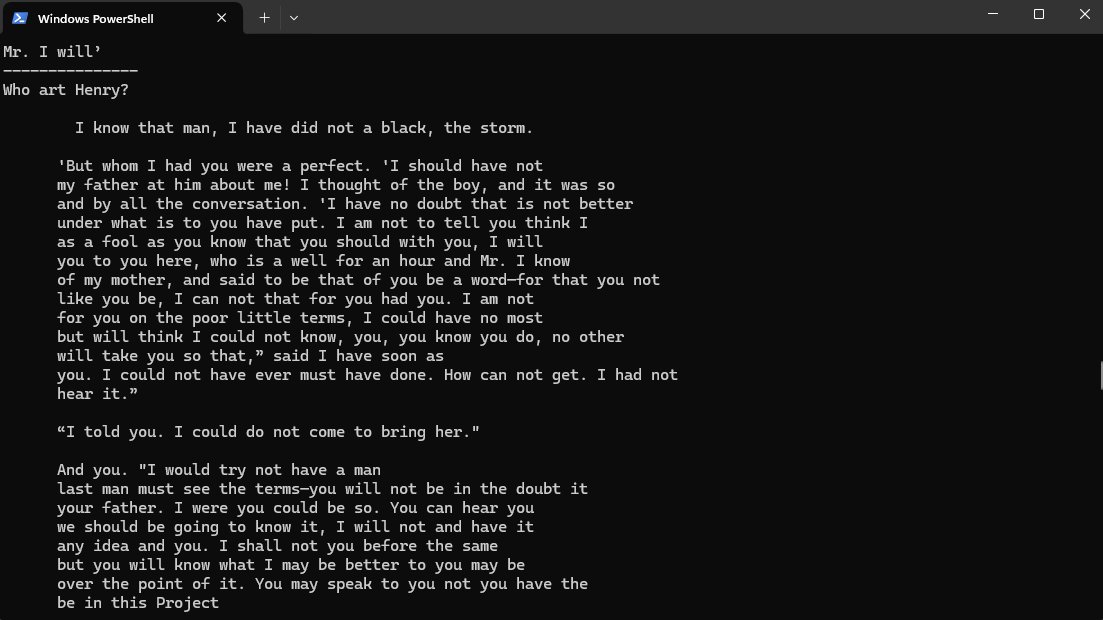 Victorian grammar emerged with proper punctuation, though hallucinations persisted. OCR artifacts remained a challenge.
Victorian grammar emerged with proper punctuation, though hallucinations persisted. OCR artifacts remained a challenge.
v1 (6.25GB data, 700M params)
 The first model to connect real events: When prompted with "It was the year of our Lord 1834," it described London protests mirroring historical accounts of anti-poor law demonstrations. Outputs showed thematic coherence:
The first model to connect real events: When prompted with "It was the year of our Lord 1834," it described London protests mirroring historical accounts of anti-poor law demonstrations. Outputs showed thematic coherence:
Output: "...the streets of London were filled with protest and petition. The cause... was not bound in the way of private, but having taken up the same day in the day of Lord Palmerston..."
v2mini (15GB data, 300M params)
Tokenization issues initially garbled outputs (e.g., mangled responses about Charles Dickens). After fixes, responses adopted fluid Victorian syntax but retained era-typical biases, as analyzed in the v2 bias report.
Technical Constraints and Insights
- Hardware: Early versions trained on consumer RTX 4060 GPUs; larger v1/v2 models required A100 cloud instances.
- Limitations: All versions exhibit factual hallucinations and OCR noise. Sentence coherence scales with data volume—v1's 6.25GB dataset marked a turning point.
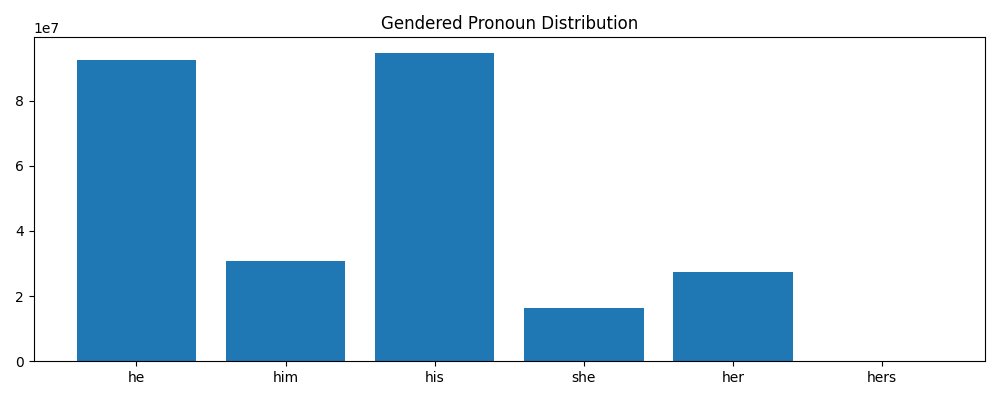
- Bias Reflection: Models replicate period-typical perspectives (e.g., colonial attitudes, limited gender roles), providing unfiltered historical mirrors rather than ethical frameworks.
Applications and Accessibility
TimeCapsuleLLM offers researchers a tool to study linguistic evolution and historical bias propagation. Grigorian provides comprehensive documentation for replicating the workflow, emphasizing that "the value lies in observing how language and worldview intertwine in a closed system."
Future work includes expanding to other eras and locations, though dataset curation remains labor-intensive. As one of few projects exploring temporally isolated training, TimeCapsuleLLM challenges assumptions about how AI assimilates cultural context.
Comments
Please log in or register to join the discussion