
As AI agents become increasingly sophisticated and integrated into business processes, robust evaluation frameworks have become essential for maintaining quality, safety, and performance. This comprehensive analysis examines the evolving landscape of AI agent evaluation, with a focus on Microsoft Foundry's approach, and provides strategic guidance for organizations looking to implement effective evaluation practices in their cloud-native environments.
The rapid advancement of AI agents has transformed them from simple text generators to complex systems that take actions, call tools, and make decisions across multiple steps. This evolution presents both significant opportunities and substantial challenges for organizations deploying these systems. Unlike traditional applications where quality can be verified through deterministic testing, AI agents introduce non-determinism, complex multi-turn interactions, and the potential for silent regressions that may only surface in production environments.
The Evaluation Imperative
AI agents don't just generate responses; they actively interact with systems, modify data, and make decisions that directly impact business operations. A prompt change that improves one workflow can quietly break another, while a model upgrade that boosts fluency could degrade tool selection. Without systematic evaluations, these regressions typically surface only when users encounter them in production, potentially causing significant business disruption.
The consequences of inadequate evaluation extend beyond technical performance. In customer-facing applications, poor agent behavior can damage brand reputation and customer trust. In internal systems, incorrect decisions can lead to operational inefficiencies, compliance issues, or financial losses. The stakes are particularly high in regulated industries where AI agents may be making decisions affecting customer data, financial transactions, or safety-critical operations.
Microsoft Foundry: A Comprehensive Evaluation Framework
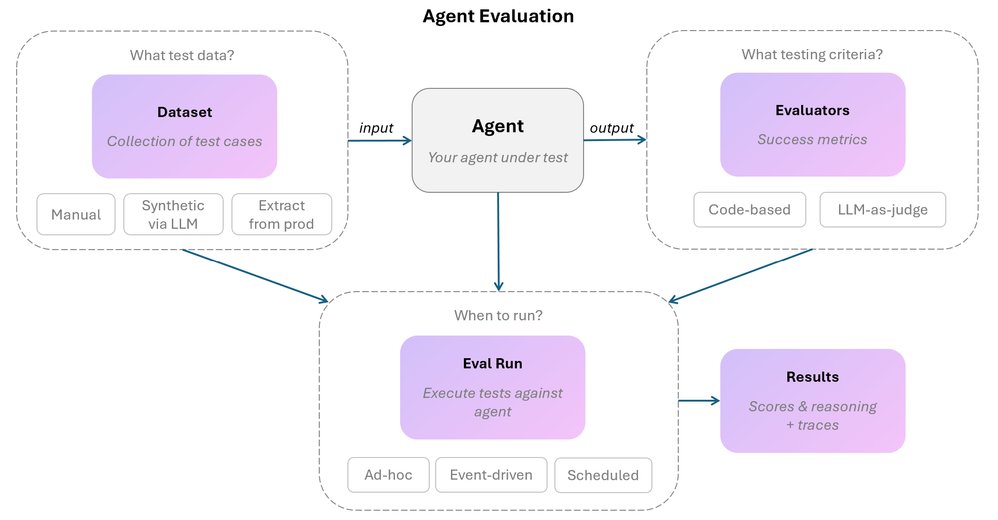
Microsoft Foundry represents a significant advancement in AI agent evaluation, providing an integrated approach that combines datasets, evaluators, evaluation runs, traces, and analysis capabilities. This framework addresses the unique challenges of AI agent evaluation by focusing on end-to-end testing rather than isolated components.
The core components of Microsoft Foundry's evaluation framework include:
Datasets: Collections of test cases that define what to evaluate. These can be manually created, synthetically generated using LLMs, or curated from real production interactions. Effective datasets include both positive and negative cases, covering expected behaviors and edge cases that should be handled appropriately.
Evaluators: The assessment mechanisms that score agent behavior. Foundry offers two primary approaches:
- Code-based evaluators using deterministic logic (string matching, format validation, keyword checks)
- LLM-as-judge evaluators for assessing nuanced qualities like tone, empathy, and policy interpretation
Evaluation Runs: The execution of test cases against the agent with scoring applied. Foundry supports on-demand, event-driven, and scheduled evaluation strategies, allowing organizations to catch issues at different stages of development and deployment.
Traces: Complete execution logs that capture every message, tool call, and reasoning step. These are invaluable for debugging, as they reveal the root cause of failures that scores alone cannot identify.
Analysis Capabilities: Tools for identifying patterns in failures, comparing evaluation runs, and tracking improvement over time. These capabilities help teams prioritize fixes and measure the impact of changes.

Pricing and Cost Considerations
Implementing AI agent evaluation involves several cost considerations that organizations should factor into their planning:
Microsoft Foundry Pricing is based on Azure consumption and includes:
- Compute resources for running evaluations
- Storage for datasets and traces
- API calls to Azure OpenAI services
- Monitoring and analysis capabilities
Pricing typically follows Azure's consumption model, with costs varying based on:
- Scale of evaluation runs (number of test cases and frequency)
- Complexity of evaluators (LLM-based evaluators cost more than code-based)
- Duration of trace retention
- Volume of production monitoring
For organizations with existing Azure investments, Foundry offers a cost-effective solution due to integration benefits and potential for resource optimization. However, the total cost of ownership should include not just direct expenses but also the development resources needed to implement and maintain evaluation practices.
Open-source alternatives may have lower direct costs but often require more development resources to implement effectively. The total cost of ownership for these solutions can be higher when factoring in maintenance, customization, and integration with existing systems.
Commercial alternatives typically offer tiered pricing models based on usage, features, and support levels. These solutions may have higher upfront costs but can reduce development overhead and provide specialized capabilities that justify the investment.
Organizations should conduct a thorough cost-benefit analysis considering:
- Risk reduction (avoiding production failures)
- Development efficiency (catching issues early)
- Operational cost optimization (identifying inefficient agent behavior)
- Compliance requirements (mandated testing in regulated industries)
Comparative Analysis: Evaluation Approaches and Tools
While Microsoft Foundry provides a comprehensive solution, the market offers several approaches to AI agent evaluation, each with distinct advantages and limitations:
Microsoft Foundry stands out for its integration with the Azure ecosystem and its focus on end-to-end evaluation. Its strengths include:
- Seamless integration with Azure OpenAI services
- Built-in evaluators for common use cases
- Comprehensive tracing and debugging capabilities
- Support for both code-based and LLM-based evaluation methods
Open-source frameworks like LangChain and Haystack offer flexibility and customization but require more technical expertise to implement effectively. These frameworks provide the building blocks for evaluation but lack the integrated tooling that Foundry offers.
Commercial alternatives such as DataRobot and Hugging Face Face Evaluation provide specialized capabilities but may lack the comprehensive agent evaluation focus of Foundry. These tools often excel in specific areas like model comparison or dataset management but may require integration with other systems for complete evaluation coverage.
Custom-built solutions offer maximum flexibility but come with significant development and maintenance overhead. Organizations with unique requirements may find this approach necessary, but it typically requires substantial investment in both development and ongoing maintenance.
The choice among these approaches depends on several factors including organizational technical capabilities, existing cloud infrastructure, evaluation requirements, and budget constraints. Microsoft Foundry often represents a balanced solution for organizations already using Azure services, while open-source alternatives may appeal to those requiring maximum flexibility or avoiding vendor lock-in.
Migration Considerations
Organizations considering implementing AI agent evaluation or transitioning between evaluation approaches should carefully plan their migration strategy:
From Manual Testing to Structured Evaluation involves:
- Codifying existing manual test cases into a formal dataset
- Defining clear evaluation criteria and metrics
- Implementing basic evaluation tools and processes
- Training development teams on evaluation practices
This transition typically requires moderate investment in tooling and process changes but yields significant improvements in consistency and reproducibility.
From Basic Evaluation to Continuous Integration involves:
- Integrating evaluation into CI/CD pipelines
- Implementing automated regression detection
- Establishing quality gates for code deployment
- Developing debugging and trace analysis capabilities
This transition requires more substantial technical investment but provides substantial benefits in development efficiency and product quality.
From Single-Cloud to Multi-Cloud Evaluation involves:
- Ensuring evaluation tools work across cloud providers
- Standardizing evaluation metrics and processes
- Addressing differences in API behavior and performance
- Implementing cross-cloud monitoring and alerting
For organizations using Microsoft Foundry as their primary evaluation tool but also operating in other cloud environments, several strategies can facilitate multi-cloud evaluation:
Hybrid Approach: Use Microsoft Foundry for Azure-based agents and complementary tools for other cloud providers, maintaining consistent evaluation standards across environments.
Abstraction Layer: Implement a common evaluation interface that can work with different cloud-specific tools, allowing for consistent metrics while accommodating platform differences.
Centralized Evaluation Hub: Use Microsoft Foundry as a central evaluation hub that can receive and evaluate results from agents running in different cloud environments.
The migration process should be approached incrementally, starting with the most critical systems and gradually expanding evaluation coverage. Organizations should also consider the learning curve associated with new evaluation tools and allocate appropriate resources for team training and knowledge transfer.
Business Impact and Strategic Considerations
Implementing effective AI agent evaluation practices yields significant business benefits that extend beyond technical quality:
Risk Mitigation: Proper evaluation reduces the likelihood of harmful outputs, policy violations, and security vulnerabilities. This is particularly important in regulated industries where compliance requirements mandate rigorous testing of AI systems.
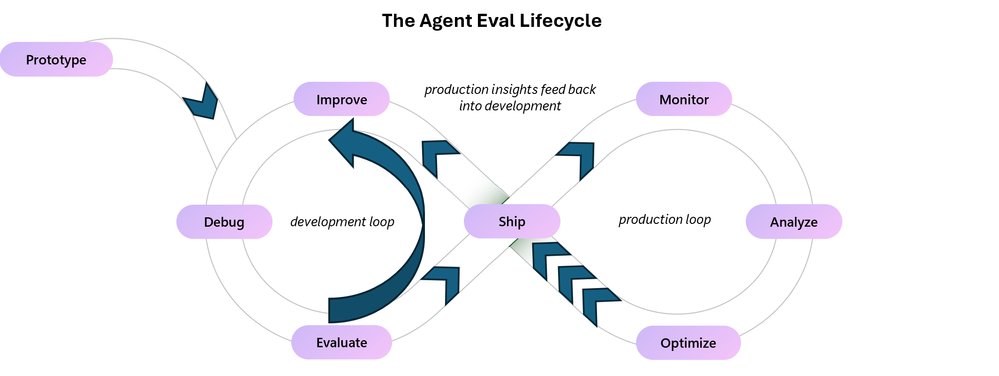
Operational Efficiency: By catching issues early in development, organizations reduce the cost and time associated with fixing problems in production. The two-loop model—combining pre-ship evaluation with post-ship monitoring—creates a continuous improvement cycle that enhances agent performance over time.
Customer Experience: Well-evaluated agents provide consistent, reliable interactions that build customer trust and satisfaction. This is increasingly important as AI agents become the primary interface for many customer service and support functions.
Business Agility: Evaluation frameworks enable organizations to iterate quickly while maintaining quality standards. This allows for faster deployment of new capabilities and more responsive adaptation to changing business requirements.
Cost Optimization: By identifying inefficiencies in agent behavior, evaluation can help reduce unnecessary API calls, optimize tool usage, and minimize computational costs associated with agent operation.
Implementation Strategy and Best Practices
Organizations typically progress through several stages of evaluation maturity, from informal testing to comprehensive continuous improvement:
Stage 1: Informal Testing characterized by manual testing and subjective assessment. While this approach offers quick feedback, it lacks consistency and scalability.
Stage 2: Structured Evaluation introduces codified test cases and defined metrics. Organizations at this stage can run evaluations on demand and establish baseline performance metrics.
Stage 3: Continuous Integration integrates evaluation into the development pipeline, automatically running tests on code changes to catch regressions before they reach production.
Stage 4: Production Monitoring extends evaluation to deployed systems, continuously assessing agent performance on real user interactions and alerting to potential issues.
Stage 5: Continuous Improvement creates a feedback loop where production insights inform test cases and evaluation criteria, driving ongoing enhancement of agent capabilities.
For organizations looking to implement AI agent evaluation, Microsoft provides several resources to get started:
- The Azure AI Foundry offers comprehensive documentation and tutorials for implementing AI agent evaluation.
- The Evaluate your AI agents tutorial provides a step-by-step guide to running evaluations using Microsoft Foundry.
- The get-started-with-ai-agents template includes example evaluation setup that can be deployed directly.
Conclusion
As AI agents become increasingly integral to business operations, robust evaluation practices have shifted from optional to essential. Microsoft Foundry represents a comprehensive solution for organizations looking to implement effective evaluation frameworks, with its integrated approach addressing the unique challenges of AI agent testing.
The strategic implementation of evaluation practices yields significant business benefits, from risk mitigation to operational efficiency and enhanced customer experience. Organizations that develop a mature evaluation capability will be better positioned to leverage the full potential of AI agents while maintaining the quality and reliability required for business success.
In the rapidly evolving landscape of AI agents, evaluation is not a one-time activity but an ongoing process that must evolve alongside the systems it assesses. By implementing a comprehensive evaluation strategy and leveraging tools like Microsoft Foundry, organizations can build AI agents that deliver consistent, reliable value across their cloud-native ecosystems.
This article provides a strategic overview of AI agent evaluation with a focus on Microsoft Foundry. For more detailed technical implementation guidance, refer to the official Microsoft documentation and resources linked throughout this analysis.
Comments
Please log in or register to join the discussion