
Johns Hopkins researchers introduce ALIGN-Parts, a novel AI model that predicts named 3D object components by aligning geometric segmentation with natural language descriptions. The approach solves dual challenges of segmenting parts and assigning consistent semantic labels through a set-to-set alignment framework, enabling applications from robotics to 3D content creation.
In computer vision and graphics, understanding objects at the part level—not just as whole entities—is crucial for applications ranging from robotic manipulation to 3D content editing. Yet existing methods struggle to simultaneously segment object components and assign them consistent semantic labels. Johns Hopkins University researchers now present ALIGN-Parts, a breakthrough approach that reframes 3D part segmentation as a set alignment problem, yielding complete named decompositions in a single forward pass.
Traditional methods face two core limitations: Segmentation-only models produce anonymous regions requiring post-hoc labeling, while language-grounded systems often retrieve individual parts without holistic object understanding. ALIGN-Parts overcomes these by predicting Partlets—compact representations combining a soft segmentation mask with a text embedding. As described in the team's paper, each Partlet captures both geometric boundaries and semantic meaning, enabling direct matching to natural language descriptions.
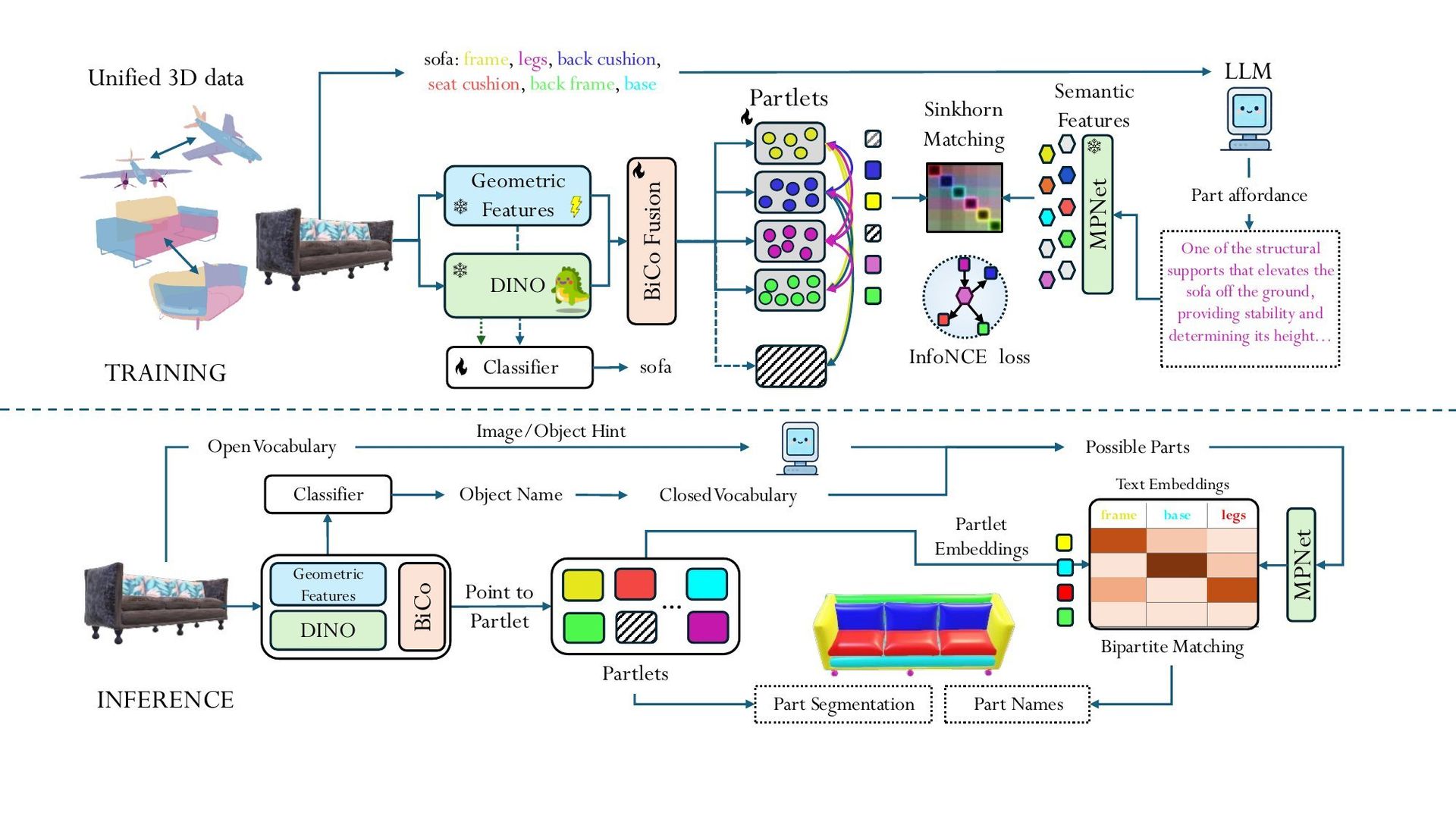 ALIGN-Parts pipeline fuses geometric, appearance, and semantic features to predict Partlets aligned with language descriptions.
ALIGN-Parts pipeline fuses geometric, appearance, and semantic features to predict Partlets aligned with language descriptions.
The architecture integrates three data streams:
- Geometric features from a 3D part-field backbone
- Multi-view appearance features lifted onto the 3D structure
- Semantic context from LLM-generated, affordance-aware descriptions (e.g., "the horizontal surface of a chair where a person sits")
During training, a differentiable bipartite matching aligns predicted Partlets to ground-truth segments using a multi-term loss function:
- Text alignment (InfoNCE): Ensures Partlet embeddings correspond semantically to descriptions
- Mask supervision (BCE + Dice): Refines segmentation accuracy
- Partness loss: Dynamically activates Partlets based on object complexity
- Regularizers: Prevent over-segmentation and point-claiming conflicts
Evaluation across 3DCoMPaT++, PartNet, and Find3D datasets demonstrates ALIGN-Parts' superiority. It outperforms baselines in class-agnostic segmentation (mIoU) and label-aware metrics, including:
- LA-mIoU: Strict exact-name matching
- rLA-mIoU: Relaxed scoring using text embedding similarity (valuable for synonyms like "screen" vs. "monitor")
Crucially, ALIGN-Parts achieves ~100× faster inference than clustering-based approaches by avoiding post-processing. As shown below, it accurately segments fine-grained components like scissor screws despite size challenges:
 Fine-part localization capability enables precise segmentation of small components.
Fine-part localization capability enables precise segmentation of small components.
The team also addresses inconsistent taxonomies across datasets via a two-stage alignment pipeline combining embedding similarity with LLM validation—enabling unified training on diverse part semantics. Ablation studies confirm the text alignment loss ((\mathcal{L}_{\text{txt}})) is indispensable; its removal causes label-aware accuracy to collapse by 90%.
While limitations remain in handling noisy real-world scans and out-of-distribution generalization, ALIGN-Parts represents a paradigm shift. By directly predicting named parts through language-geometry alignment, it opens doors for scalable 3D annotation tools and foundation models capable of understanding objects at human-meaningful levels of abstraction.
Comments
Please log in or register to join the discussion